
Midjourney v7 launches with voice prompting and faster draft mode — why is it getting mixed reviews?

Join daily and weekly newsletters to obtain the latest updates and exclusive content to cover the leading artificial intelligence in the industry. Learn more
Midjourney, a startup company that suffers from a boot that many AI Power users as the “Golden Standard” to generate artificial intelligence images since its launch in 2022 are now the most advanced version of Midjournyy V7.
The title feature is a new way to demand the form to create images.
Previously, users have been limited to writing in text claims and connecting other images to help direct generations (the model can include a variety of images downloaded and attached by the user, including other generations in Midjourney, to influence the style and subjects of new generations).
Now, the user can simply speak loudly to the Midjournyy (alpha.midjourney.com) – provided that they have a microphone in/run/attachment to their computer (or use a network connected to the network with the audio, such as headphones or smartphone) – the model will listen and evoke his own text based on the recipes of the user overlooking, generated Pictures of these pictures.
It is unclear whether Midjourney has created a new model for introducing (text to text) from zero point or using an accurate or outside the box from one of the other suppliers such as ElevenLabs or Openai. I asked the founder of Midjourney David Holz on X, but he has not yet responded.
Using the draft mode and entering the voice conversation to the claim in case of flow
It goes together with this input method is a new “drafts” that generates images more quickly than Midjourney v6.1, which is the most urgent version, often in less than a minute or even 30 seconds in some cases.
Although images of quality are less than V6.1, the user can click on the buttons “improve” or “vary” on the right of each generation to restart the full quality.
The idea is that the human user will be happy to use both of them – in fact, “draft mode” should be run to activate the audio inputs – to enter a smoother flowing state of creative formulation with the model, spending less time improving the specific language of claims and more than seeing new generations, responding to them in real time, modifying or modifying them more modern.
“Make this look more detailed, darker, lighter, more realistic, more dynamic, more vibrant,” etc., are some instructions that the user can provide through the new sound interface in response to generations to produce new modifications that fit better with their creative vision.
Begin with Midjourney v7
To enter these situations, starting with the new “draft” feature, the user must first jump through the new Midjourney customization feature: Midjourney.
Although this feature was previously presented to Midjourney v The user can then switch a pattern that matches the images that I love better during the marital classification process.
Now, Midjournyy V7 requires users to create a new specific personal style V7 before Even it is ever used in the first place.

Once the user does this, they will fall on the familiar Midjourney Alpha dashboard where they can click “Create” from the left side railway to open the creation tab.

Next, in the admission bar at the top, the user can click on the new “P” button to the right of the tape to run his customization mode.

The founder and leader of Midjourney David Holz emphasized on Venturebeat that the older allocation patterns of V6 can also be chosen, but not separate “mood panels”-patterns of image collections that have been uploaded by the user-although the Midjournyy X account will be separately due to that the feature will return soon. However, I didn’t see the opportunity to choose the older V6 style.
However, the user can then click on the new “Black mode” button to the right of the customization button (also to the right of the insertion of the text router) to activate this faster image generation mode.
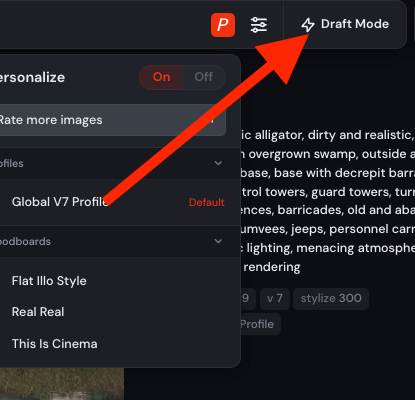
Once you are determined using the indicator, the orange color will be turned on, indicating that it is turned on, then a new button should appear with a microphone icon to the right of this. This is the audio claim mode, which the user can again click to activate it.

Once the user presses this microphone button to enter the audio claim mode, they should see the microphone icon that changes from white to orange to indicate that it is engaged, and the wave line line will appear on its right that must start to crocodize in time with the user’s speech.
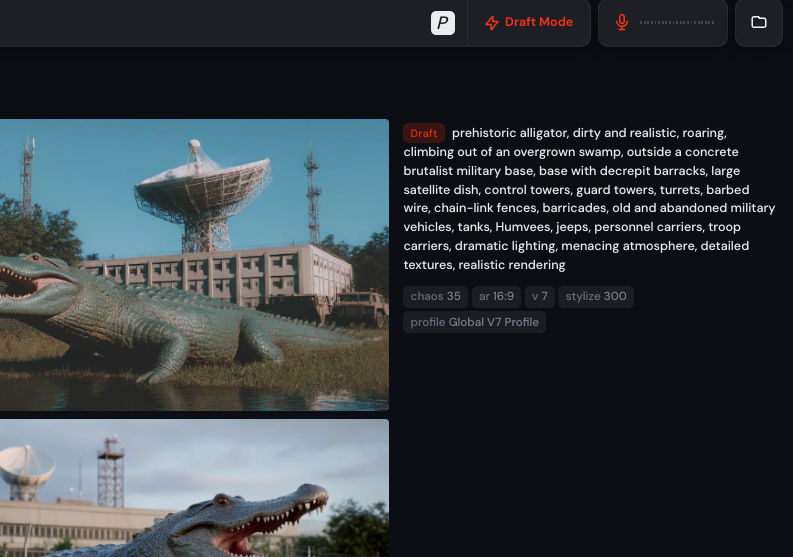
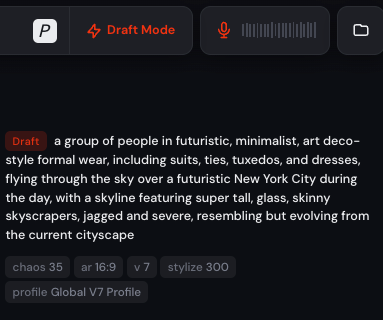
The model will then be able to hear and you should also hear when you’re done speaking. In practice, I sometimes received an error message saying “API in an actual time is not connected”, but stop and restart the audio input mode and update the web page is usually wiped quickly.
After a few seconds of speaking, Midjourney will start flashing some of the keyword windows below the admission text box on top, and creating a full text router to the right because it creates a new set of 4 photos based on what the user said.

The user can then adjust these new generations by speaking to the model again, switching the sound mode and turning off as needed.
Here is a fast experimental video that it uses today to create some pictures. You will see that the process is far from perfection, but it is really fast and allows more intermittent condition from the claim, refining and receiving pictures of the form.
2025-04-04 18:47:00



