
Ming-Lite-Uni: An Open-Source AI Framework Designed to Unify Text and Vision through an Autoregressive Multimodal Structure
The multimedia develops rapidly to create systems that can understand, create multiple data and respond to them in one or one task, such as text, images and even video or sound. These systems are expected to operate through various reaction formats, allowing more smooth human communication. With the increasingly involved users of artificial intelligence for tasks such as illustrations of the images, editing of text -based images, and elegance transmission, it has become important to these models to process inputs and interact through the actual time. The boundaries of the research in this field focus on integrating the capabilities that are dealt with by simply dealing with separate models in uniform systems that can be performed fluently and accurately.
A major obstacle in this field stems from the imbalance between the semantic understanding based on language and visual sincerity required to create images or editing. When separate models deal with different methods, outputs often become inconsistent, which leads to poor cohesion or inaccuracy in tasks that require interpretation and obstetric. The visual model may excel in reproducing an image, but it fails to understand the accurate instructions behind it. On the other hand, it may understand the claim model, but it cannot be visually formed. There is also anxiety of expansion when models are trained in isolation; This approach requires significant mathematical resources and re -training efforts for each field. The inability to link vision and language smoothly in a coherent and interactive experience remains one of the basic problems in the progress of smart systems.
In recent attempts to fill this gap, the researchers merged a structure with fixed visual symbols and separate cities that operate through spreading techniques. Tools such as Tokeenflow and Janus are combined with the distinctive symbol -based language models with the background of images, but it usually confirms the accuracy of the pixels on the semantic depth. These methods can produce visually rich content, however they often miss the nuances of the user input. Others, like GPT-4O, moved towards the capabilities of original images but still working with restrictions in very integrated understanding. The friction in the translation of the abstract text is meaningful images and eyes in the interaction of fluid without dividing the pipeline into broken parts.
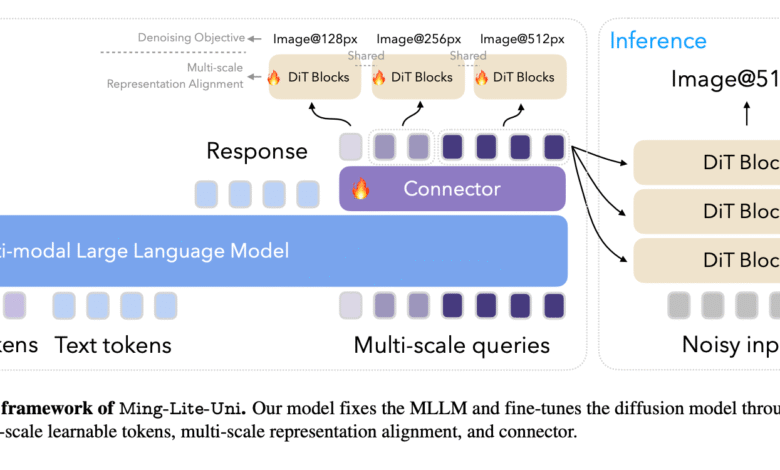
The AI researchers presented Ant Group, Ming-Lite-Yuni, an open source frame designed to unify the text and vision through the multimedia structure of automatic slope. The system features an automatic specific model designed above a large fixed language model and a picture of a picture. This design depends on two basic frameworks: Metaqueries and M2-omni. Ming-Lite-Youi offers an innovative component of multiple symbols that can learn, which act as interpretable visual units, and a multi-scale alignment strategy corresponding to maintaining cohesion between different image standards. The researchers presented all the typical weights and implementation publicly to support society’s research, and the position of the Ming-Lite-Youi site as a preliminary model that moves towards general artificial intelligence.
The basic mechanism behind the model includes the pressure of the optical input in an organized symbolic sequence via multiple standards, such as 4 x 4, 8 x 8, and 16 x 16 image corrections, each representing different levels of details, from planning to texture. These symbols are processed along with text symbols using a large self -transformer. Each level of accuracy is distinguished by the start and unique termination and dedicated localized codes. The model uses a multi -scale representation strategy that corresponds to intermediate features and outputs through the loss of medium Spring error, ensuring consistency across the layers. This technology enhances the quality of the image rebuilding with more than 2 dB in PSNR and improves the generation assessment (Geneval) by 1.5 %. Unlike other systems that re-train all components, the Ming-Lite-Youi keeps the language model frozen and only runs a photo generator, allowing faster updates and larger expansion.
The system has been tested on various multimedia tasks, including generating the text to an image, transmitting style, editing detailed images using instructions such as “making small sunglasses” or “removing two flowers in the image”. The model dealt with these tasks with high sincerity and contextual fluency. It has maintained strong visual quality even when abstract claims or style such as “Hayao Miyazaki style” or “three -dimensional are adorable”. The training group spanned more than 2.25 billion samples, combining Laion-5B (1.55B), Coyo (62M), Zero (151M), completed with Midjournyy candidates (5.4M), Wukong (35M), and other web sources (441M). Moreover, it merged the accurate granules data collections for aesthetic evaluation, including AVA (255K sample), tad66k (66K), AESMMIT (21.9K), and APDD (10K), which strengthened the model’s ability to generate attractive outputs visually according to human broadcast standards.

The model combines semantic durability with high -resolution images in one corridor. It achieves this by aligning the representation of images and text at the level of the distinctive symbol via the standards, rather than relying on the division of fixed coding coding. The approach allows automatic decline models to carry out complex editing tasks with contextual guidance, which was previously difficult to achieve. The flow loss and the scale of the scale supports a better reaction between the adapter and the proliferation layers. In general, the model surrounds a rare balance between understanding language and visual output, as it has been put as an important step towards the multimedia systemic systems.
Many major meals from searching for Ming Lite-Unit:
- Ming-Lite-Youi presented a unified structure for the vision tasks and linguistic tasks using automatic modeling.
- Visual inputs are coded using multiple symbols that can learn (4 x 4, 8 x 8, 16 x 16).
- The system maintains a frozen language model and trains a separate photo generator.
- The alignment of multi -scale representation improves cohesion, which improves more than 2 dB in PSNR and an increase of 1.5 % in Geneva.
- Training data includes more than 2.25 billion samples from public and institutional sources.
- The tasks that are handled include a text generation to an image, editing photos, questions and visual answers, all of which have been dealt with with strong contextual fluency.
- Merging aesthetic scoring data helps to generate visually enjoyable results consistent with human preferences.
- Typical weights and implementation are open source, and encourage repetition and extension by society.
verify paperA model on the face embrace and the Jashab page. Also, do not forget to follow us twitter.
Here is a brief overview of what we build in Marktechpost:
SANA Hassan, consultant coach at Marktechpost and a double -class student in Iit Madras, is excited to apply technology and AI to face challenges in the real world. With great interest in solving practical problems, it brings a new perspective to the intersection of artificial intelligence and real life solutions.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-09 06:26:00



