This AI paper from DeepSeek-AI Explores How DeepSeek-V3 Delivers High-Performance Language Modeling by Minimizing Hardware Overhead and Maximizing Computational Efficiency
Growth in the development and publication of large language models (LLMS) is closely related to architectural innovations, large -scale data groups and equipment. Models such as Deepseeek-V3, GPT-4O, Claude 3.5 Sonnet and Llama-3 showed how scaling enhances thinking and dialogue capabilities. However, with increasing its performance, computing, memory and communication requires a frequency range, which puts great pressure on the devices. Without parallel progress in the joint design of infrastructure and infrastructure, these models risk access to organizations with mega resources only. This makes improving the cost of training, speed of reasoning and memory efficiency is an important field for research.
The basic challenge is the incompatibility between the size of the model and the capabilities of the devices. LLM consumption grows over 1000 % annually, while high -speed high -speed domain width increases by less than 50 %. During the inference, the previous cache storage in the main value stores (KV) adds to the memory strain and slows down the processing. Dense models activate all parameters for each symbol, escalating mathematical costs, especially for models that include hundreds of billions of parameters. This results in billions of floating comma operations for each symbol and high -energy requirements. The time for each TPOT icon, which is a major performance scale, also suffers from user experience. These problems require solutions that go beyond merely adding more devices.
Techniques such as multi -seventh attention (MQA) and your gathering interest (GQA) reduce memory by sharing attention weights. KV cache reduces the use of memory by storing modern symbols only, but can limit the long -context understanding. Quantitative pressure with low -bit formats such as 4 bits and 8 bits cuts more memory, although sometimes the stimulus in accuracy. Resolution formats such as BF16 and FP8 improve training and efficiency speed. Although they are useful, these technologies often deal with individual issues rather than a comprehensive solution to limit the challenges.
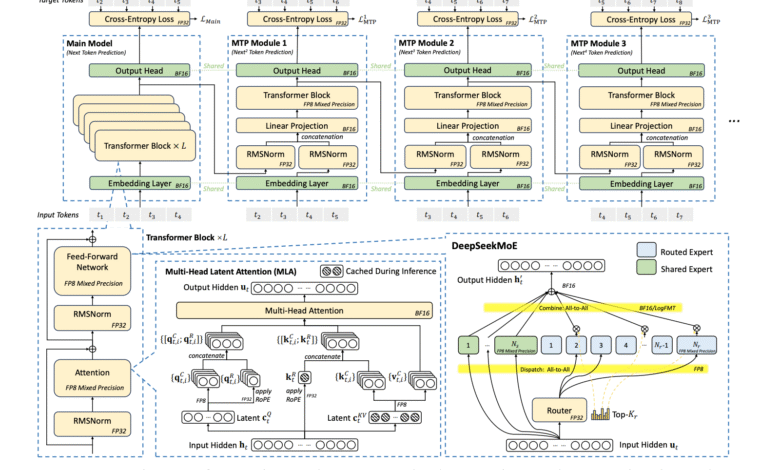
Researchers from Deepseeek-EAI presented a more integrated and effective strategy with Deepseek-V3, designed to expand its scope intelligently, not excessively. Using 2,048 Nvidia H800 GPU, the model achieves the latest model with cost efficiency. Instead of relying on the extensive infrastructure, the team designed the structure of the model to work in harmony with devices restrictions. Suitable for this effort, innovations such as multi -header interest (MLA) to improve memory, a mixture of experts (MEE) for mathematical efficiency, and mixed accuracy FP8 to accelerate performance without sacrificing accuracy. A multi -aircraft network toby is also used to reduce the general expenditures for communication between devices. Collectively, these ingredients make Deepsek-V3 a developmentable and accessible solution, able to compete with much larger systems while working for much smaller resources.
The structure achieves the efficiency of memory by reducing the requirements of the KV cache per code to only 70 km using MLA, compared to 327 km and 516 km in QWEN-2.5 and Llama-3.1, respectively. This reduction is accomplished by compressing the heads in a smaller, smallest trained carrier with the form. Accounting efficiency is increased more with the MEE model, which increases the total parameters to 671 billion, but only 37 billion is active for each symbol. This contrasts sharply with the dense models that require the stimulation of a complete parameter. For example, Llama-3.1 needs 2448 GFLOPS per code, while Deepseek-V3 works only 250 GFLOPs. Also, architecture merges a multiple prediction unit (MTP), allowing the generation of multiple symbols in one step. The system achieves up to 1.8x improvement in the speed of obstetrics, and the real world measurements show the acceptance of the distinctive symbol 80-90 % to dismantle speculation.

Using an interconnected system with CX7 400 GB: Deepseek-V3 is a theoretical TPot of 14.76 milliseconds, equivalent to 67 code per second. With the highest domain settings such as NVIDIA GB200 NVL72, which offers 900 GB/s, this number can be reduced to 0.82 milliliters of TPOT, which achieves 1,200 code per second. Practical productivity is lower due to the overlap in the arithmetic and memory, but the frame sets the basis for high -speed applications in the future. FP8 resolution adds more speed gains. The training framework applies 1 x 128 tile size and quantity 128 x 128 blocks, with a loss of accuracy less than 0.25 % compared to BF16. These results were validated on the microcredit of parameters 16B and 230B before integration in Form 671b.
Many main meals include search-v3 ideas:
- The MLA pressure reduces the size of the KV cache per code from 516 km to 70 km, which greatly reduces memory requirements during reasoning.
- Only 37 billion of a total of 671 billion parameters are activated for each symbol, which greatly reduces account and memory requirements without prejudice to the performance of the model.
- DeepSeek-V3 only requires 250 GFLOPs per code, compared to 2448 GFLOPs for dense models such as Llama-3.1, while highlighting its mathematical efficiency.
- It achieves up to 67 icons per second (TPS) on the Infiniband 400 GB, with the ability to expand 1200 TPS using advanced connections such as NVL72.
- Multiple prediction (MTP) improves the speed of generation by 1.8 x, with a symbol acceptance rate of 80-90 %, enhancing inference productivity.
- The FP8 mixed accuracy provides a faster account with a deterioration of less than 0.25 %, and its validity is validated by the wide -ranging commandments.
- A capable of operating a $ 10,000 server equipped with a consumer graphics processing unit, providing approximately 20 TPS, making access to LLMS high -performance.
In conclusion, the research provides a good framework for building strong, conscious linguistic models. By directing basic restrictions directly, such as memory restrictions, high mathematical costs, and inference specifications, researchers explain that the joint design of architecture programs can open high performance without relying on vast infrastructure. Deepseek-V3 is a clear example of how efficiency and expansion are coexisted, allowing the broader adoption of advanced artificial intelligence through various organizations. This approach transforms the narration from scaling through brute force to scaling through smarter engineering.
Check the paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 90k+ ml subreddit.
SANA Hassan, consultant coach at Marktechpost and a double -class student in Iit Madras, is excited to apply technology and AI to face challenges in the real world. With great interest in solving practical problems, it brings a new perspective to the intersection of artificial intelligence and real life solutions.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-17 06:29:00