Can LLMs Really Judge with Reasoning? Microsoft and Tsinghua Researchers Introduce Reward Reasoning Models to Dynamically Scale Test-Time Compute for Better Alignment
Reinforcement learning (RL) has emerged as a basic approach in LLM after training, using supervisory signals from human reactions (RLHF) or verified bonuses (RLVR). While RLVR shows the promise of sports thinking, it faces great restrictions due to relying on training inquiries with verified answers. This requirement limits applications to wide -scale training on public domain information as the verification of the preparation is proven. Moreover, current reward models, classified into numerical and obstetrics cannot effectively determine the test time time to estimate the rewards. Current methods apply uniform calculations in all inputs, and they lack adaptation to allocate additional resources for difficult information that require accurate analysis.
Drafting strategies and registration plans distinguish bonus models. Digital methods have standard degrees to inquire about response pairs, while obstetric methods produce natural linguistic reactions. Registration follows the absolute evaluation of individual couples or discriminatory comparison of candidates’ responses. The models of obstetric rewards, which are compatible with the LLM-AS-A-JUGE model, offer interpretable but subject to reliable fears due to biased rulings. The scaling methods are adjusted at the time of dynamic inference, computational resources, including parallel strategies such as multiple multiple and scaling on the horizon of extended thinking trends. However, it lacks a systematic adaptation with the complexity of inputs, which limits its effectiveness through various types of query.
Microsoft Research, Tsinghua University, and Beijing University suggested that the RRMS think, which performs frank thinking before producing final rewards. This thinking stage allows RRMS to customize additional arithmetic resources when assessing responses for complex tasks. RRMS provides a dimension to enhance the bonus modeling by limiting the test time test time while maintaining public application capacity through various evaluation scenarios. By thinking about the thought chain, RRMS uses an additional account for the time for complex information when the appropriate bonuses are not clear immediately. This encourages RRMS to develop self -development capabilities of bonus without explicit thinking effects as training hypotheses.
RRMS uses the QWEN2 model with the spine of the converted spine, and the formulation of bonus modeling as completing the text as RRMS creates thinking operations followed by final rulings. Each entry contains inquiries and responses to determine the preference without allowing relationships. Researchers use the Rawardbench warehouse to direct systematic analysis through evaluation criteria, including sincerity of instructions, assistance, accuracy, damage, and the level of details. RRMS supports a multi -response assessment through ELO classification systems and a knockout championships, both of which can be combined with the majority vote to use the test time account. These RRMS samples are several times for marital comparisons, which leads the majority vote to obtain strong comparative results.
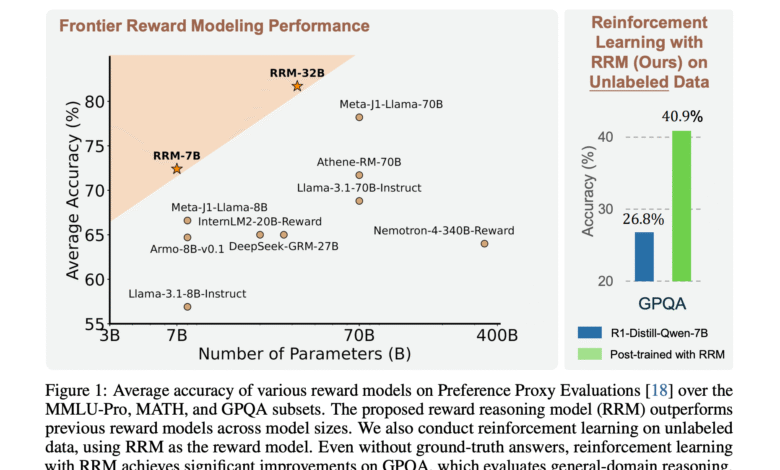
The evaluation results show that RRMS achieves competitive performance against strong foundation lines on bonus testing and Pandalm, with RRM-32B get 98.6 % in thinking categories. Comparing the trained DirectjudGE models on identical data reveal large performance gaps, indicating the effective use of RRMS calculating the time of the sophisticated information. In the best inference directed to the rewards, RRMS exceeds all basic models without calculating additional test time, with the majority vote provides significant improvements across sub -set groups. Post-training experiences show fixed performance improvements on MMLU-PRO and GPQA. The scaling of experiments through the 7B, 14B and 32B models that the longer thinking prospects are constantly improving accuracy.
In conclusion, researchers presented RRMS to perform explicit thinking processes before setting the bonus to treat mathematical flexibility in current bonus modeling methods. RRMS RRMS allows the development of complex thinking capabilities without the need for explicit thinking effects as supervision. RRMS is efficiently used to calculate test time through the parallel scaling approach and sequence. The RRMS effectiveness in practical applications, including the best inference directed to reward and comments after training, shows its capabilities as strong alternatives to traditional numerical reward models in alignment technologies.
Check out paper and models on the embraced face. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 95K+ ML Subreddit And subscribe to Our newsletter.

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-26 18:17:00