
This AI Paper Introduces LLaDA-V: A Purely Diffusion-Based Multimodal Large Language Model for Visual Instruction Tuning and Multimodal Reasoning
Melms is designed to process and create content via various methods, including text, photos, sound and video. These models aim to understand and integrate information from different sources, and enable applications such as answering visual questions, the labels of the illustrations of the images, and multimedia dialogue systems. The development of MLLMS is an important step towards creating artificial intelligence systems that can explain the world and interact in a more like human way.
The main challenge is to develop the effective MLMS in integrating various types of inputs, especially visual data, in language models while maintaining high performance through tasks. Current models are often struggled with the balance of understanding of strong language and effective visual thinking, especially when limiting into complex data. Moreover, many models require large data collections for good performance, making it difficult to adapt to specific tasks or fields. These challenges shed light on the need for more efficient and developed methods for multimedia learning.
The current MLMS mostly uses automatic slope methods, and one -time symbol is one way from left to right. While this approach has restrictions in dealing with complex multimedia contexts. Alternative methods have been explored, such as proliferation models; However, they often show a weaker understanding of the language because of its restricted structure or insufficient training strategies. These restrictions indicate a gap where a purely prevalent model can provide multimedia competitive capabilities if they are effectively designed.
Researchers from the University of Renmin in China and the ANT LLADA-V group, a Melm, disguised language modeling model (MLM) combining visual instructions with convincing proliferation models. Based on Llaada, the Great Language Proliferation model includes a vision encoded and a MLP connector to show visual features in the language included in the language, allowing effective multimedia alignment. This design is a departure from the dominant automatic models in the current multimedia methods, with the aim of overcoming current restrictions while maintaining data efficiency and expansion.
 AI-Paper-Introduces-LLaDA-V-A-Purely-Diffusion-Based-Multimodal-Large.png" alt="" style="width:794px;height:auto"/>
AI-Paper-Introduces-LLaDA-V-A-Purely-Diffusion-Based-Multimodal-Large.png" alt="" style="width:794px;height:auto"/>LLADA-V is employing a common post as the text responses are gradually improved through the frequent prediction of convincing symbols. Unlike the automatic models that expect successive symbols, Llada-V creates outputs by contrary to the disguised spread. The model has been trained in three stages: the first stage corresponds to the vision and linguistic implications by setting the visual features from Siglip2 to the area of Llaada. The second stage fills the form using 10 million samples of one images and 2 million multimedia samples from Mammoth-VL. The third stage focuses on thinking, using the QA 900K pairs of Visualwebinstruct and a mixed data collection strategy. Dual -directional attention improves context, which provides a strong, multimedia understanding.
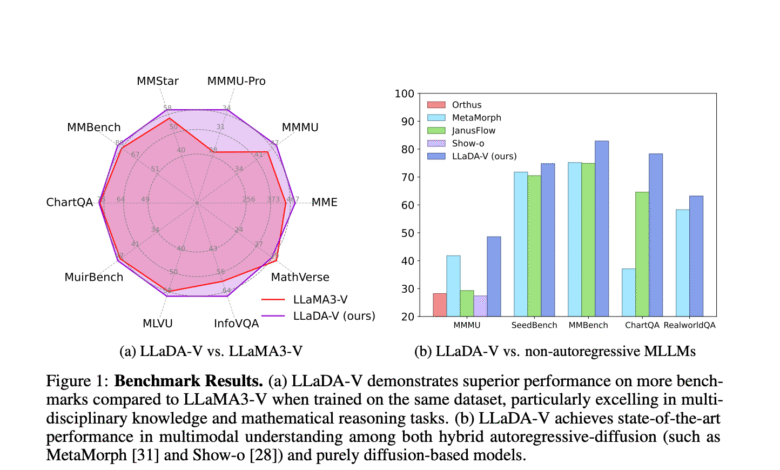
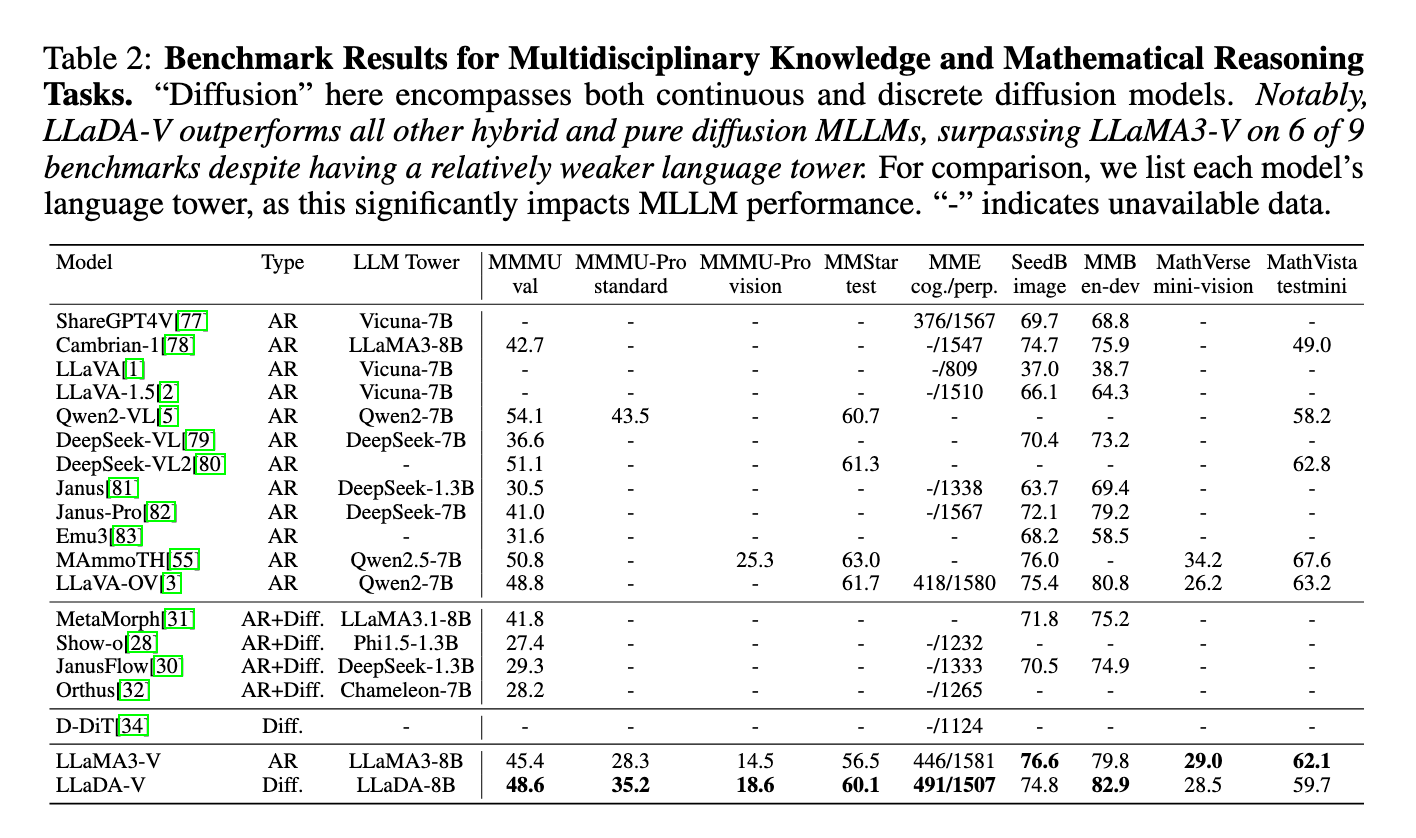
In the assessments across 18 multimedia mission, Llada-V showed a superior performance compared to the automatic hybrid spread and models based on purely spread. It surpassed Llama3-V on most of the multidisciplinary and sporting knowledge tasks such as MMMU, MMMU-PRO and MMSTAR, where it achieved 60.1 degree on MMSTAR, near QWEN2-VL’s 60.7, despite Llada-V using the weakest Llaada-8B tower. Llada-V also was also distinguished by data efficiency, surpassing Llama3-V on MMMU-PRO with 1m sample against Llama3-V’s 9M. Although he is behind the standards of graph and documentation of understanding, such as AI2D, and in the tasks of the real scene, such as Realworldqa, the results of Llaada-V are highlighted and promised to multimedia tasks.
In short, LLADA-V address the challenges of building effective multimedia models by introducing a purely widespread structure that combines visual instructions with convincing proliferation. The approach provides strong multimedia thinking possibilities while maintaining data efficiency. This work shows the potential of spreading models in multi -media artificial intelligence, which paves the way for further exploration of the possibility of complex artificial intelligence tasks.
Check the paper page and GitHub . All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 95K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-03 02:36:00



