ByteDance Researchers Introduce DetailFlow: A 1D Coarse-to-Fine Autoregressive Framework for Faster, Token-Efficient Image Generation

The generation of automatic images has been formed by applying in serial modeling, which was originally seen in the treatment of natural language. This field focuses on creating one symbolic images at one time, similar to how to build sentences in language models. The attractiveness of this approach lies in its ability to maintain structural cohesion through the image while allowing high levels of control during the generation process. When researchers began to apply these technologies to visual data, they found that organized prediction not only maintained spatial safety but also supported by tasks such as image processing and effective multimedia translation.
Despite these benefits, the generation of high -precision images is still expensive and slow. The main issue is the number of symbols required to represent complex images. Bottical scanning methods that make two -dimensional images in the linear sequence of thousands of distinctive symbols of detailed images, which leads to long conclusion times and high memory consumption. Models such as Infinity need more than 10,000 symbols of a 1024 x 1024 image. This becomes unnecessary for applications in actual or when scaling into more comprehensive data sets. Reducing the distinctive symbol burden while maintaining or improving output quality has become a challenge.
The efforts to alleviate the distinctive inflation have led to innovations such as the forecast for the next scale in VAR and Flexvar. These models create pictures by predicting more accurate standards, which imitate the human tendency to draw outstands before adding details. However, they still rely on hundreds of symbols – 680 in the case of VAR and Flexvar for 256 x 256 photos. Moreover, approaches such as Titok and Flextok use the distinctive 1D code to compress spatial repetition, but they often fail to expand efficiently. For example, the GFID of Flextok increases from 1.9 at 32 icons to 2.5 in 256 icons, highlighting a deterioration in the quality of the output with the growth of the distinctive number of symbol.
The researchers from bytedance provided the flow of details, which is a 1D automatic image generation frame. This method is arranged by the distinctive symbol sequence from global to minute details using a process called the following detail. Unlike traditional techniques with bilateral or based fiery clicks, the details of the details are used by a 1D code trained on gradually deteriorating images. This design allows the model to determine the priorities of the founding photo structures before improving visual details. By setting the distinctive symbols directly to the levels of accuracy, the flow of details significantly reduces the requirements of the distinctive symbol, which enables the creation of images in a significant way, from coarse to coarse.
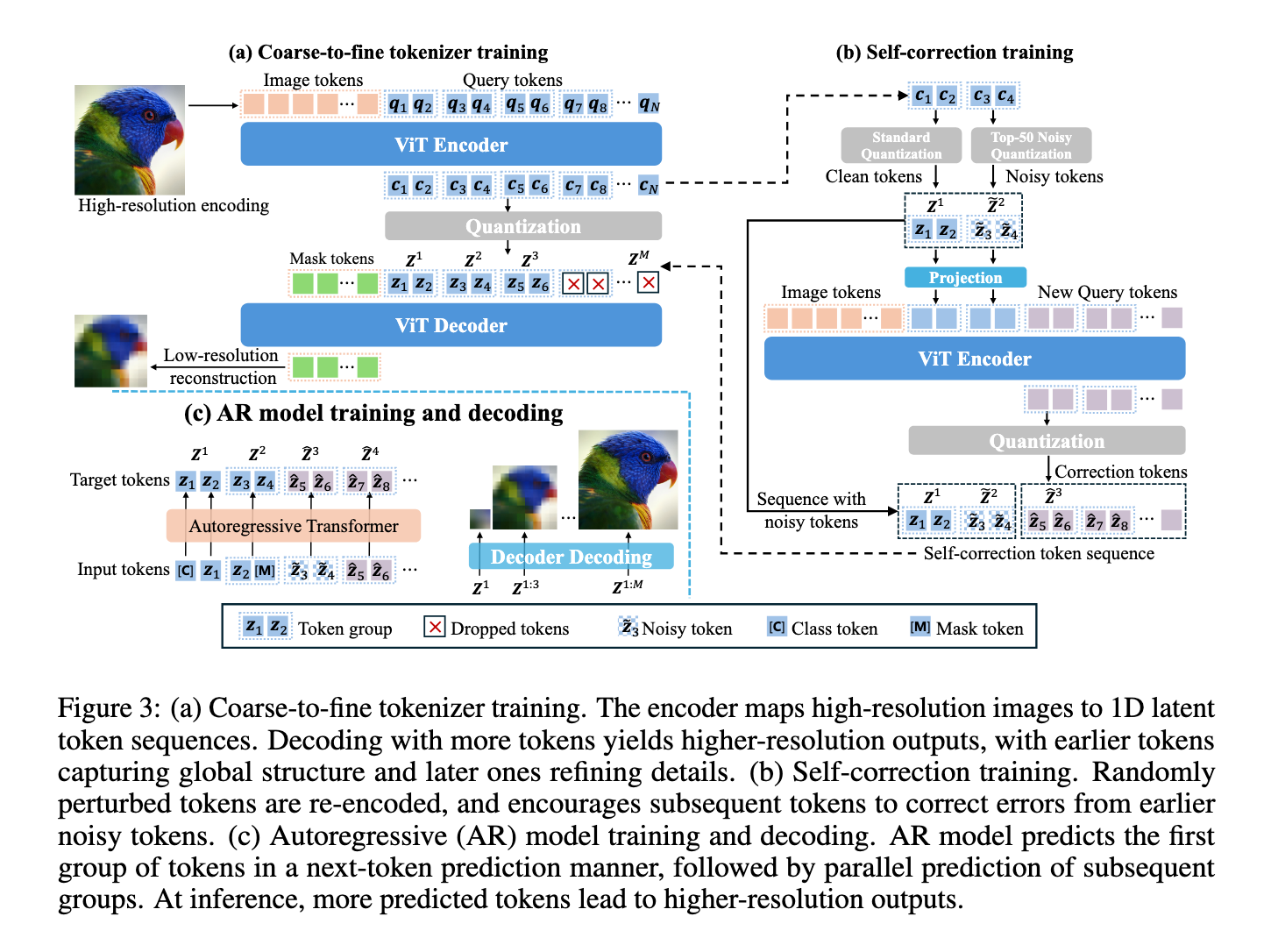
The mechanism focuses on the flow of details on a 1D underlying area where each symbol contributes more details gradually. Previous symbols encrypt global features, while the distinctive symbols later improve specific visual aspects. To train this, the researchers created a accuracy appointment function linking the number of the distinctive code for consumption. During training, the model is exposed to pictures of varying quality and learns to predict high accuracy outputs gradually while providing more symbols. It also implements the parallel prediction by collecting a sequence and predicting whole groups at one time. Since parallel prediction can make samples errors, the autonomous mechanism has been combined. This system raises some distinctive symbols during training and teaches subsequent symbols for compensation, ensuring that the final and visual images are maintained.
The results of the experiments on the standards of Imagenet 256 x 256 were noticeable. Details flowing the GFID score of 2.96 using only 128 icons, outperformed VAR at 3.3 and Flexvar at 3.05, both of which used 680 icons. Even more impressive, details of the flow 64 reached GFID from 2.62 using 512 icons. In terms of speed, he delivered nearly twice the rate of VAR and Flexvar. Another era of eradication confirmed that training on self -correction and semantic arrangement of improved symbols is very improved. For example, GFID self -correction empowerment fell from 4.11 to 3.68 in one setting. These scales show both high quality and fastest generation compared to existing models.
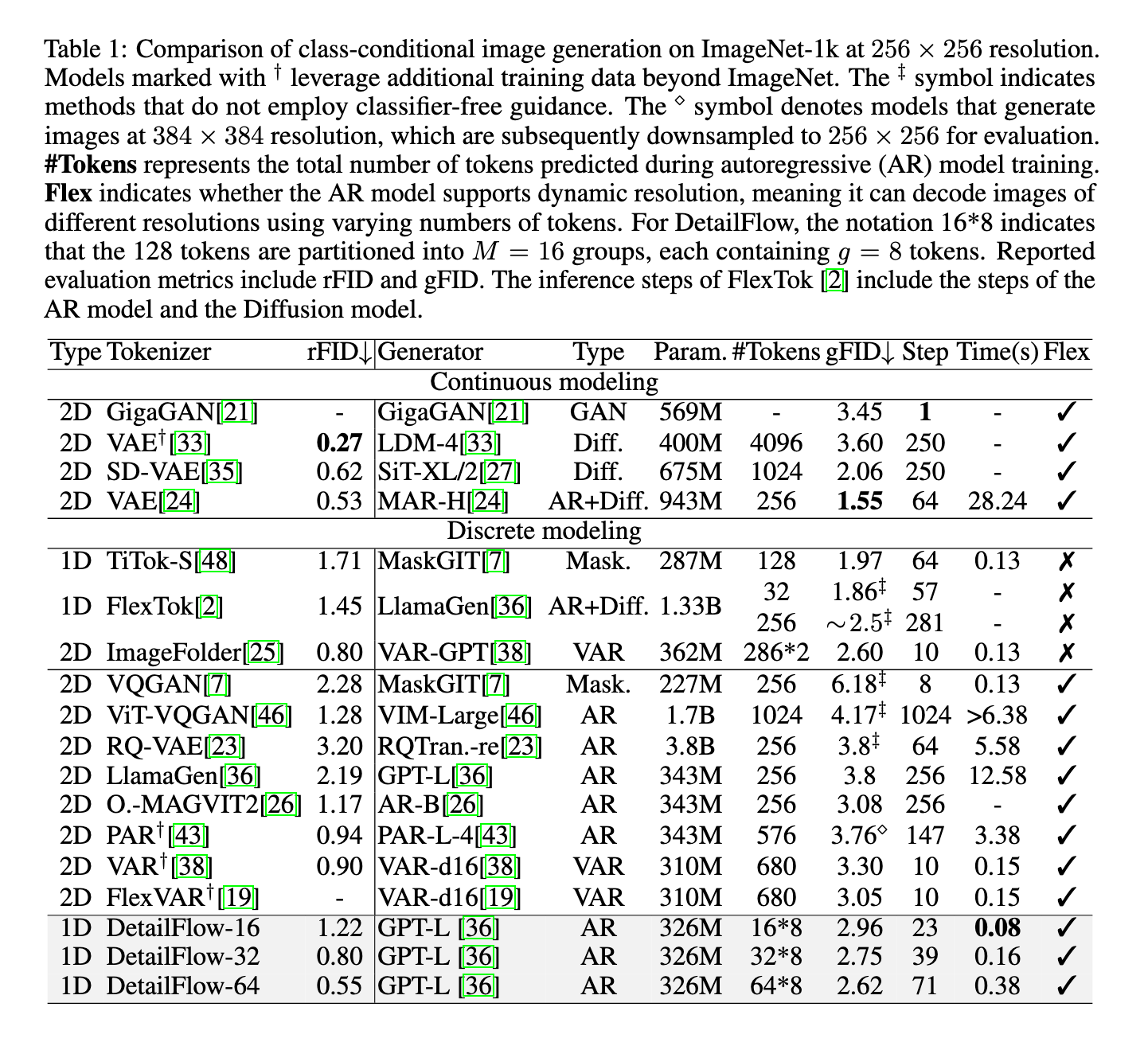
By focusing on the semantic composition and reducing repetition, the flow of details provides a applicable solution to long -term issues in generating automatic images. The rough to the rough to the rough, the effective parallel decoding, and the ability to correct the self to highlight how architectural innovations can address performance restrictions and expansion. By using a regulator of 1D symbols, researchers from Bytedance showed a model that maintains the loyalty of the high image while greatly reducing the arithmetic load, making it a valuable addition to image creation research.
Check the paper page and GitHub. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 95K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.
Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-06-07 06:33:00