
High-Entropy Token Selection in Reinforcement Learning with Verifiable Rewards (RLVR) Improves Accuracy and Reduces Training Cost for LLMs
LLMS models create step -by -step responses known as the COTS chain, where each symbol contributes to a coherent and logical narration. To improve the quality of thinking, various reinforcement learning techniques have been used. These methods allow the model to learn from the feedback mechanisms by aligning the outputs created with the standards of righteousness. As LLMS grows in complexity and ability, researchers began to investigate the internal structure to generate the distinctive symbol to distinguish patterns that enhance or reduce performance. One of the areas that gained attention is the distribution of symbolic anthropia, and the measurement of uncertainty in a distinctive prediction, which is now linked to the ability of the model to make logical decisions meaningful during thinking.
There is an essential problem in training thinking models using reinforcement learning is to address all distinctive symbols on an equal. When models are improved using reinforcement learning with verified bonuses (RLVR), the process of modernization is traditionally included in the created sequence, regardless of its functional role. This uniform treatment failed to distinguish between symbols that lead to a shift of great thinking about those that only provide existing linguistic structures. As a result, a large part of the training resources may be directed to symbols that provide minimal contribution to the possibilities of thinking about the model. Without specifying the priorities of the few symbols that play decisive roles in moving in different logical paths, these methods miss opportunities to improve focus and effective.
Most RLVR frameworks, including improved policy (PPO), improving the group’s relative policy (GRPO), improving dynamic sampling policy (DAPO), and the function by assessing a full sequence of symbolic outputs against the reward functions that evaluate the right. PPO depends on policy updates stability through a separate objective function. GRPO improves from this by estimating the advantage of the advantage of using collected responses, instead of a separate value mesh. DAPO offers additional improvements, such as a mechanism with high books and the formation of accumulated rewards. However, these methods are not treated in Interopia at the level of the distinctive symbol or the importance of individual symbols in the thinking chain, rather than applying uniform updates in all areas.
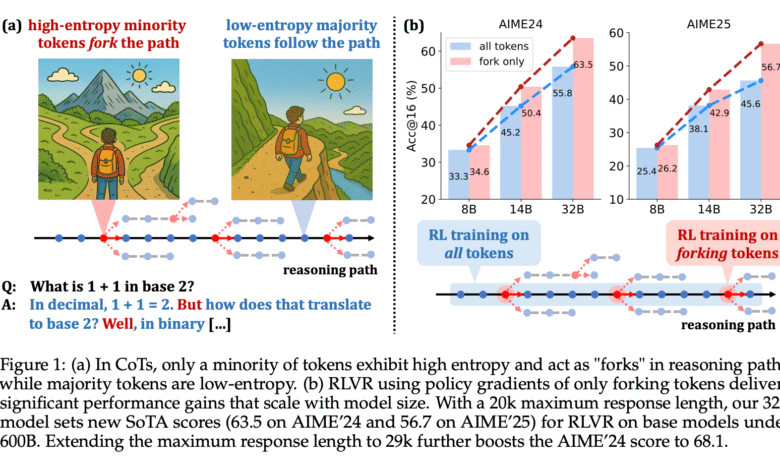
In an attempt to improve how to affect RLVR training, researchers from Alibaba Inc. presented. The University of Tsinghua is a new methodology that focuses on symbolic anthropia patterns. Note that in the COT sequence caused by QWEN3 models, a small sub -group of symbols appears, about 20 %, entryubia is much higher. These distinctive symbols, called “distinctive symbols”, often match the moments when the model must decide between multiple thinking paths. The remaining 80 % of low entropy symbols usually appear and act as accessories for previous data. By reducing political gradual updates only on these high symbols, the research team was not only able to maintain, but in many cases, improving performance on difficult thinking standards.
To measure the distinctive symbol, researchers used the entropy formula based on the distribution of the possibility to the potential symbol options in each step. They found that more than half of all the symbols created had an entropy values less than 0.01, indicating almost directed behavior. Only 20 % exceeded enteopia of 0.672, on the occasion of Cots. High symbols often include logical players and connective words such as “assumption” or “since then” or “and so on,” which provide new terms or transformations in logic. On the other hand, low administrative symbols included symbols, fragments, or code fragments. Through controlled experiments, it became clear that the treatment of these anthropic symbols directly affects the performance of the model, with the change of distinctive low -entropy symbols had no significant effect.
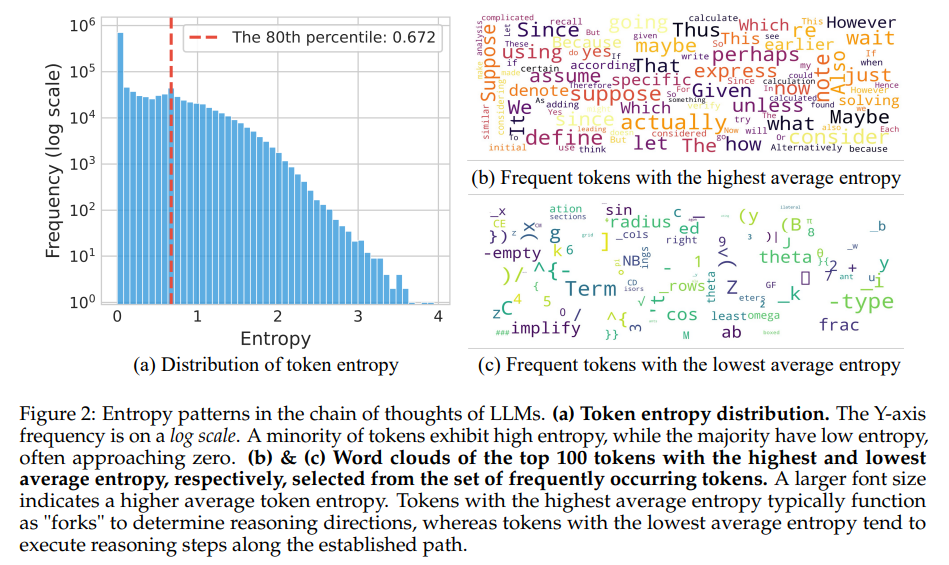
The research team conducted wide experiences across three sizes of models: QWEN3-8B, QWEN3-14B and QWEN3-32B. When training high high symbols on only 20 %, the QWEN3-32B model scored 63.5 on Aime’24 and 56.7 on Aime’25, both of which set new performance criteria for models under 600B parameters. Moreover, the increased length of the maximum response from 20k to 29k raised the Aime’24 degree to 68.1. In comparison, training on 80 % of the low administrative symbols caused a significant decrease in performance. QWEN3-14B model showed gains +4.79 on Aime’25 and +5.21 on Aime’24, while QWEN3-8B has maintained competitive results for full training. The eradication study also stressed the importance of maintaining a 20 % threshold. The fracture decreased to 10 % of the basic decision points, increasing it to 50 % or 100 % relieving the effect by including many low symbols, which reduces the diversity of the entropy and obstructing exploration.

In essence, the research provides a new trend to enhance the capabilities of the causes of language models by selectively identifying and training on the minority of symbols that contribute inconsistently to the success of thinking. It avoids ineffective training and instead suggests a developmental approach that corresponds to reinforcement learning goals with the actual decision -making moments in the distinctive symbol sequence. The success of this strategy lies in the use of anthropia as a guide to distinguish useful filling symbols.
Many main meals include:
- About 20 % of the symbols appear high entropy and serve as a router that directs thinking paths.
- Training only on these high -performance symbols provides equality or better than training on a full distinctive symbol group.
- QWEN3-32B has achieved 63.5 degrees on Aime’24 and 56.7 on Aime’25, outperforming larger traditional training models.
- Extension of the response length from 20 kilos to 29 kg to a h in Aime’24 to 68.1.
- Training on the remaining 80 % of low -entropy symbols has deteriorated acute performance.
- Maintaining a 20 % threshold for high -in -input symbols optimally exploration and performance.
- The largest models gain more of this strategy because of its ability to benefit from the improvement.
- The strategy is well protected and can direct more efficient training for the next generation thinking models.
In conclusion, this research rethinks effectively in applying learning to enhance language models by inserting an entrance to anthropia at the distinctive symbol level. By improving only the minority that affects the thinking paths, the method is enhanced while reducing the general account expenditures. It provides a practical road map for future efforts to improve the thinking of LLMS without unnecessary complexity.
Check the paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 98k+ ml subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-09 01:38:00



