
CURE: A Reinforcement Learning Framework for Co-Evolving Code and Unit Test Generation in LLMs

introduction
LLMS models showed significant improvements in thinking and accuracy through reinforcement learning (RL) and scaling techniques at test time. Despite the superiority of traditional unit testing methods, most current methods such as O1 and UTGen require supervision of the Earth’s truth symbol. This supervision increases the costs of data collection and reduces the volume of usable training data.
Current methods of methods
The generation of the traditional unit test depends on:
- software analysis methodsWhich depends on the rules and stolen.
- Neurological translation techniquesWhich often lacks semantic alignment.
Although the modern methods based on the student and the agent are working to improve performance, they still rely heavily on the software instructions for control. This dependence restricts the ability to adapt and expansion, especially in widely wide publishing scenarios.
Treatment: a common evolutionary approach that underwent itself
Researchers medicineThe framework for self -supervision learning is jointly trained by the symbol generator and the generation of unit test without any symbol of the earthly truth.
Treatment works using a self -playing mechanism:
- LLM creates a correct and incorrect code.
- The unit test generator learns to distinguish between the conditions of failure and becomes itself accordingly.
This bilateral joint development enhances both the generation of the code and verification without external supervision.
Architecture and methodology
Basic models and sampling strategy
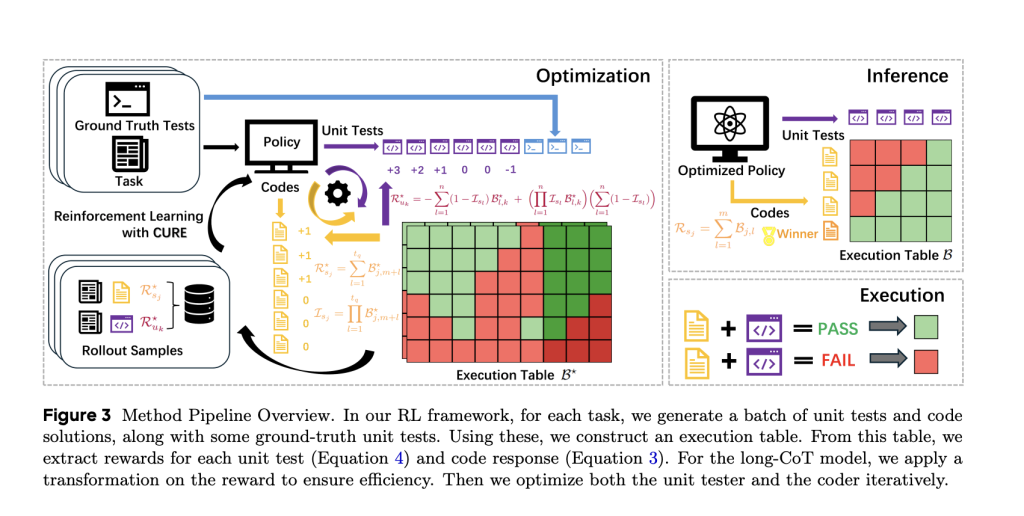
Cure was built on QWEN2.5-7B and 14B models, with QWEN3-4B models for long chain variables (COT). All samples of the training step:
- 16 Complete the candidate symbol.
- 16 tests for the tasks derived from the tasks.
Samples are made using VLLM with a temperature of 1.0 and Top-P 1.0. For long models, the transformation that realizes the response is punished for long outputs, which improves the efficiency of the time of reasoning.
The reward and improvement function
Cure offers bonuses on a mathematical basis to:
- Glorification AccuracyIt was defined as the possibility that the correct code will be recorded higher than the incorrect software instructions through the unit tests created.
- Apply bonus modifications based on response to long responses to reduce cumin.
Improvement continues through political progressive methods, and a joint update between the programmer and unity to improve its mutual performance.
Standard data standards and evaluation measures
Treatment is evaluated on five standard coding data sets:
- Livebench
- Mbp
- LiveCOOOOOBENCH
- Codecontss
- Code
Performance is measured by:
- Unit test unit
- The accuracy of generating one symbol
- The best accuracy of N (bon) using 16 icons and test samples.

Performance and efficiency gains
the Quentflux-Coder Models derived via Cure Achievement:
- +37.8 % In the unit test unit.
- +5.3 % In the accuracy of generating one symbol.
- +9.0 % In the accuracy of Bon.
It is worth noting that Qualityflux-Coder-4B achieves 64.8 % Decrease in the average length of the unit test response – improving the speed of reasoning. In all standards, these models outperform the traditional models that are set on coding (for example, QWEN2.5-Coder-Instruct).
App for commercial llms
When Quentflux-Coder-4B is paired GPT-Series models:
- GPT-4O-MINI gains +5.5 % bon accuracy.
- GPT-4.1-Mini is improving before +1.8 %.
- The costs of the application programming interface are reduced during performance enhancement, indicating a cost -effective solution for pipeline inference at the production level.
Use a sticker -free compression bonus form
Trained unit test generators that were treated as a bonus for RL training models can be reused. The use of unit tests created in Underflux-Coder-4B leads to similar improvements to supervising the test called human-its delivery Pipes learning to reinforce free from stickers.
The capacity of a broader application and future directions
Beon, the Distafflux-Coder models integrate smoothly with the edge of coding agents such as:
- MPSC (multi -perspective self -compatibility)
- Alphacodium
- S*
These systems benefit from Cure’s ability to improve both code and tests. The treatment also enhances the accuracy 25.1 %Enhancing ingenuity.
conclusion
Cure represents a great progress in self -supervision learning to generate the code and verify health, which provides great language models from developing the capabilities of coding and unit testing testing jointly without relying on the earth’s truth symbol. By taking advantage of the framework of joint evolutionary reinforcement learning, Cure does not enhance basic performance standards such as one accuracy of the best choice and choice but also improves the efficiency of inference by improving length. His compatibility with the current coding pipelines and its ability to work as a feed -free bonus model makes it a developmentable and cost -effective solution for each of the training and publishing scenarios.
Check the paper page and GitHub. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 99k+ ml subreddit And subscribe to Our newsletter.

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.

Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-06-12 02:30:00



