
Getting Started with MLFlow for LLM Evaluation
MLFlow is a powerful open source platform for managing a lifestyle of machine learning. Although it is traditionally used to track models, recording parameters, and publishing operations management, MLFlow has recently provided support for assessing large language models (LLMS).
In this tutorial, we explore how to use MLFOW to assess LLM-in our case, the GEMINI model of Google- on a set of fact-based claims. We will create responses to fact -based claims using Gemini and evaluate their quality using a variety of scales that are supported by MLFlow directly.
Preparation of dependencies
For this tutorial, we will use both Openai and Gemini applications. AI’s compact evaluation measures in MNFOW are currently dependent on Openai models (for example, GPT-4) to work as judges for standards such as similarity of the answer or sincerity, so the API Openai key is required. You can get:
Install libraries
pip install mlflow openai pandas google-genaiSet the Openai and Google API keys as an environment
import os
from getpass import getpass
os.environ["OPENAI_API_KEY"] = getpass('Enter OpenAI API Key:')
os.environ["GOOGLE_API_KEY"] = getpass('Enter Google API Key:')Preparing evaluation data and bringing outputs from Gemini
import mlflow
import openai
import os
import pandas as pd
from google import genaiCreate evaluation data
In this step, we define a small evaluation data set that contains realistic claims along with the correct answers of the truth. These claims extend topics such as science, health, web development and programming. This structured coordination allows us to compare Gemini responses objectively in exchange for the correct answers known to use different evaluation measures in MLFlow.
eval_data = pd.DataFrame(
{
"inputs": [
"Who developed the theory of general relativity?",
"What are the primary functions of the liver in the human body?",
"Explain what HTTP status code 404 means.",
"What is the boiling point of water at sea level in Celsius?",
"Name the largest planet in our solar system.",
"What programming language is primarily used for developing iOS apps?",
],
"ground_truth": [
"Albert Einstein developed the theory of general relativity.",
"The liver helps in detoxification, protein synthesis, and production of biochemicals necessary for digestion.",
"HTTP 404 means 'Not Found' -- the server can't find the requested resource.",
"The boiling point of water at sea level is 100 degrees Celsius.",
"Jupiter is the largest planet in our solar system.",
"Swift is the primary programming language used for iOS app development."
]
}
)
eval_dataGet Gemini responses
This code block determines the function of the Gemini_completion () that sends a directed to the Gueini 1.5 Flash model using Google Generation AI SDK and re -responds as a normal text. Then we apply this function to each router in our evaluation data collection to create the form predictions, and store them in a new “prediction” column. These predictions will be evaluated later against the answers of the Earth’s truth
client = genai.Client()
def gemini_completion(prompt: str) -> str:
response = client.models.generate_content(
model="gemini-1.5-flash",
contents=prompt
)
return response.text.strip()
eval_data["predictions"] = eval_data["inputs"].apply(gemini_completion)
eval_dataGemini outputs with MLFlow
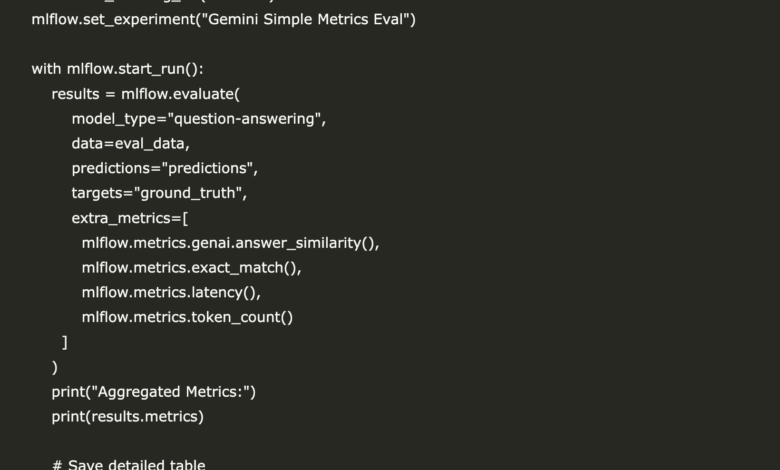
In this step, we start running the MNFlow to assess the responses resulting from the Gemini model versus a set of realistic real truth answers. We use MLFlow.evalunet () with four lightweight standards: Answer (Measuring semantic similarity between the product of the model and the basic truth), Excal_match (Check Word matches against the word), cumin (Tracking the time generation), and TOKEN_COUnt (Record the number of distinctive symbols for output).
It is important to note that Answer The measurement is used internally Openai’s GPT A model to judge the semantic rapprochement between the answers, which is why access to the API Openai is required. This setting provides an effective way to evaluate LLM outputs without relying on the logic of assigned evaluation. The results of the final evaluation are also printed and saved in the CSV file for inspection or subsequent perception.
mlflow.set_tracking_uri("mlruns")
mlflow.set_experiment("Gemini Simple Metrics Eval")
with mlflow.start_run():
results = mlflow.evaluate(
model_type="question-answering",
data=eval_data,
predictions="predictions",
targets="ground_truth",
extra_metrics=[
mlflow.metrics.genai.answer_similarity(),
mlflow.metrics.exact_match(),
mlflow.metrics.latency(),
mlflow.metrics.token_count()
]
)
print("Aggregated Metrics:")
print(results.metrics)
# Save detailed table
results.tables["eval_results_table"].to_csv("gemini_eval_results.csv", index=False)To display the detailed results of our evaluation, we download the preserved CSV file in the framework of data and setting the display settings to ensure a complete vision for each response. This allows us to examine individual claims, predictions created in Al -Jumini, and the answers of the earthly truth, and the metrics associated with them without deduction, and it is especially useful in notebook environments such as Colab or Jupyter.
results = pd.read_csv('gemini_eval_results.csv')
pd.set_option('display.max_colwidth', None)
resultsverify The symbols here. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
I am a graduate of civil engineering (2022) from Islamic Melia, New Delhi, and I have a strong interest in data science, especially nervous networks and their application in various fields.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-27 22:01:00



