
Microsoft Releases Phi-4-mini-Flash-Reasoning: Efficient Long-Context Reasoning with Compact Architecture
Phi-4-MINI-Flash-RESTINGThe latest addition to the Microsoft Phi-4 Model family is an open and lightweight language model designed to outperform long thinking while maintaining high inference efficiency. It was released in embrace, the 3.8B parameter model is an alleged version of the Phi-4-MINI, which is well seized for dense thinking tasks such as solving mathematics problems and answering multiple laws. Designed using the new microsoft Sambay Decoder-Hybrid-Decoder structure, which is recently fulfilled between compact models and works up to 10 x faster than its predecessor in the tasks of the long generation.
Architecture
At the core of Phi-4-Mini-Flash-RESTENING is Sambay Architecture, a new decoding model-Brickter merges State area models (SSMS) With attention layers using a lightweight mechanism called GMU). This structure allows the participation of effective memory between the layers, which greatly reduces the time of inference in the scenarios of the long context and the long generation.
Unlike the structure based on transformers that depend greatly on intense attention accounts, Sambay benefits Samba (SSM hybrid structure) In the autonomous uterus and replaces nearly half of the layers of joining the shape of GMUS. GMUS works as wise cheap gates functions that reuse the hidden state of the final SSM layer, thus avoiding excess account. This leads to pre -complexity in the linear time and decreased decoding input/output, which leads to a large speed during reasoning.
Training pipeline and thinking capabilities
The Phi-4-MINI-Plash model is pre-trained on 5T symbols of real high-quality, high-quality industrial data, in line with the rest of the Phi-4-MINI family. Pre -training, subject SFT luxury deals (SFT) multi -stage (SFT) and Improving direct preference (DPO) Using the instruction data collections that focus on thinking. It is worth noting, unlike the phi-4-mini-doxer, it completely excludes reinforcement learning (RLHF).
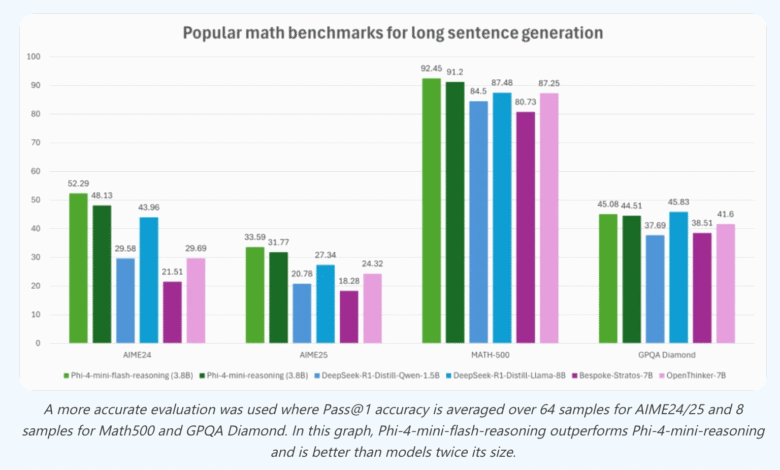
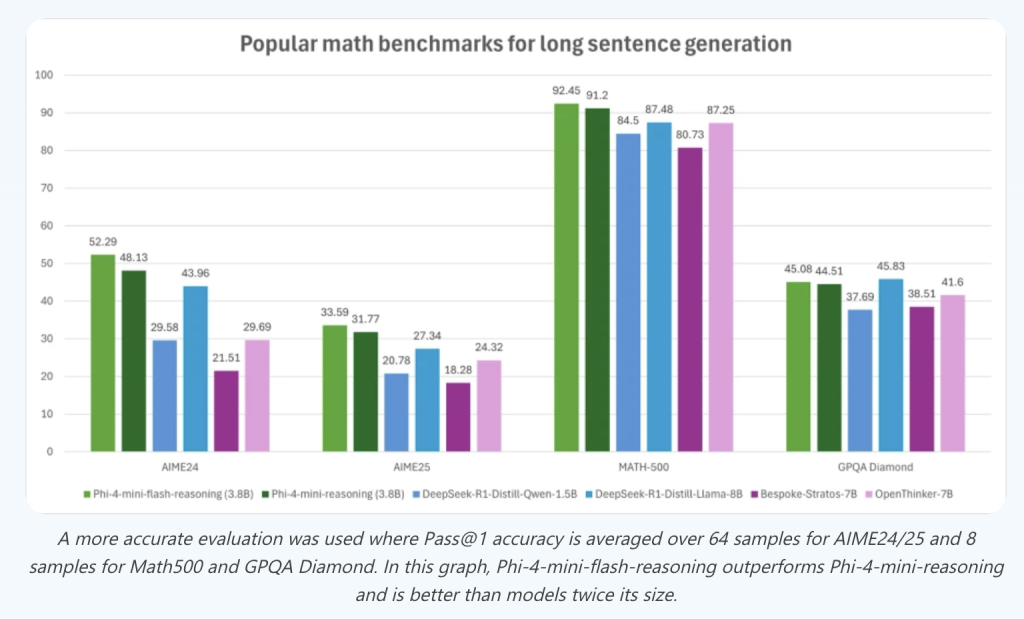
Nevertheless, Phi-4-MINI-Flash-Ecting is outperforming Phi-4-MINI-RESTENING over a set of complex thinking tasks. In the Math500 Standard, it achieves a 92.45 % pass accuracy, surpasses Phi-4-MINI-RESTENING (91.2 %) and exceeds other open models such as QWEN-1.5B and Bespoted-Strateos-7B. On Aime24/25, strong gains also appear, with more than 52 % accuracy on Aime24.
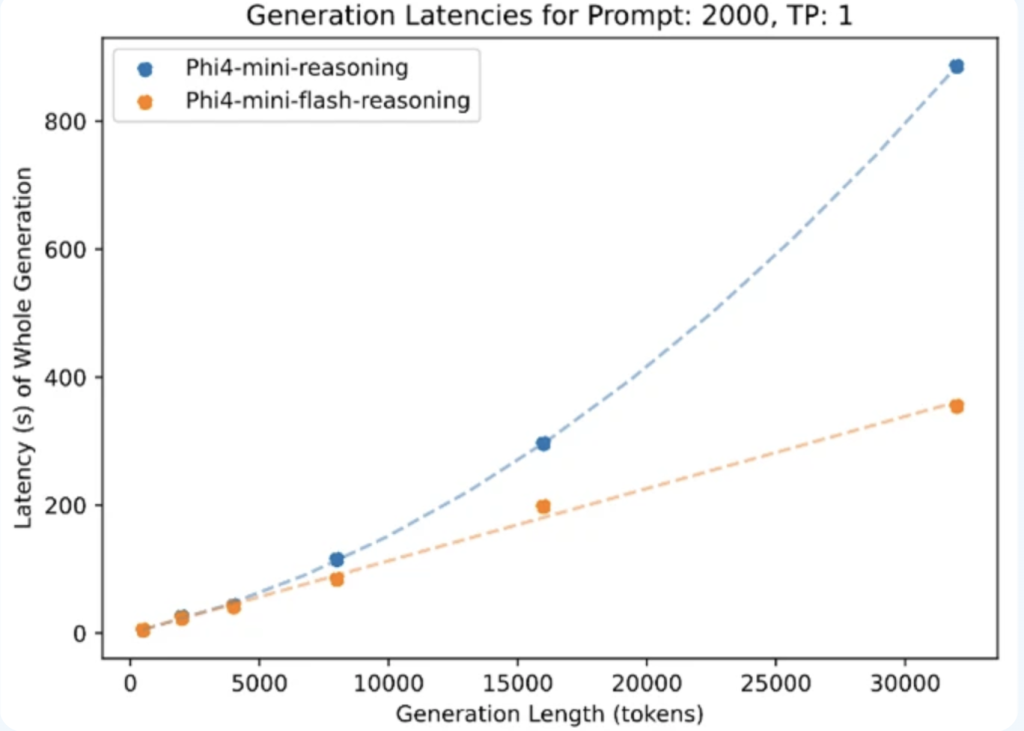
This performance leap is attributed to the ability of architecture A long generation of thought (COT). With the support of context 64K and the optimal reasoning under vlm The frame, the model can be born and operate through multiple thousands of style without bottlenecks. In cumin criteria with 2K-aken and 32 thousand generations claims, Phi-4-MINI-Flash-RASINING offers 10 x higher productivity From its predecessor.
Treating long, effective context
Efficiency gains in Phi-4-Mini-Flash-Rostening are not only theory. By designing Decoder-Hybrid-Decoder, the model achieves a competitive performance on long context standards such as a phone book and ruler. For example, with a Slide slide (SWA) A small size of up to 256, and maintains a high resolution, indicating that long -term symbolism is well captured via SSMS and GMU’s memory sharing.
These architectural innovations lead to a decrease in account and memory account. For example, while decoding, the GMU layers replace attention processes that may cost or (n · D) at the time of the distinctive symbol, lower it to O (D), where n is the length of sequence and D after hidden. The result is the ability to inference in actual time even in multiple scenarios or document levels.
Open weights and cases of use
Microsoft has open sources of weights and composition through embracing face, providing full access to society. The model supports the length of the context of 64 km, and works under Standard embrace and VLLM operating times, and it is improved for the productivity of the distinctive symbol fast on the A100 graphics processing units.
Possible use of Phi-4-MINI-Flash-Romening:
- Sports thinking (For example, sat, problems at the AIME level)
- Multiple law QA
- Legal and scientific documents analysis
- Independent factors with long -term memory
- High productive chat systems
Its mixture of open access, the ability to think, and effective reasoning makes it a strong candidate for publication in environments where the account resources are restricted but the complexity of the task is high.
conclusion
Phi-4-MINI-Flash-RESONING explains how architectural innovation-especially hybrid models can benefit from SSMS and effective gates-achieving transformational gains in thinking without size or typical cost. It represents a new trend in the moderation of the long, effective language language, which paves the way for actual time thinking agents and open -sourceable alternatives to LLMS commercial.
verify Paper, symbols, Form on face embrace and technical details. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitterand YouTube and Spotify And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-11 03:26:00



