TikTok Researchers Introduce SWE-Perf: The First Benchmark for Repository-Level Code Performance Optimization

introduction
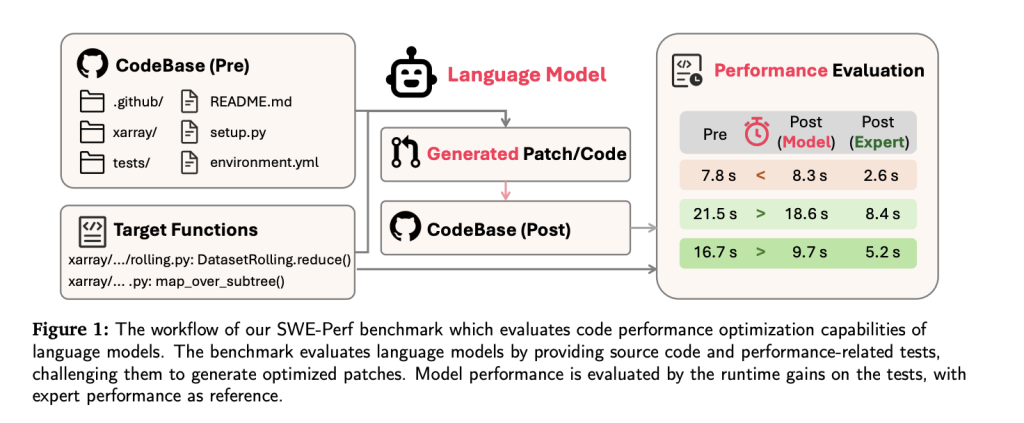
As LLMS models are advanced in software engineering tasks – ranging from the generation of the code to error repair – performance improvement remains out of reach, especially at the warehouse level. To fill this gap, the researchers from Tiktok and cooperative institutions presented Swe-Perf-The first standard specifically designed to assess the LLMS ability to improve the performance of the code in real world warehouses.
Unlike the previous standards that focused on right or function level (for example, Swe-Bench, MERICURIY, EFFIPENCE), Swe-Peer picks up the complexity and contextual depth to adjust the warehouse performance. It provides a quantitative basis to study and improve the possibilities of improving performance for modern LLMS.
Why is Swe-Peer needed
Code bases in the real world are often large, via, and complexly interconnected. Improving them for performance requires understanding cross-file reactions, implementation paths, and mathematical bottlenecks-challenges that exceed the scope of isolated data groups at the level of jobs.
LLMS is largely evaluated on tasks such as a sentence correction or small job transfers. But in production environments, performance control over warehouses can achieve greater benefits at the system level. SWE-Perf is explicitly designed to measure LLM capabilities in such settings.
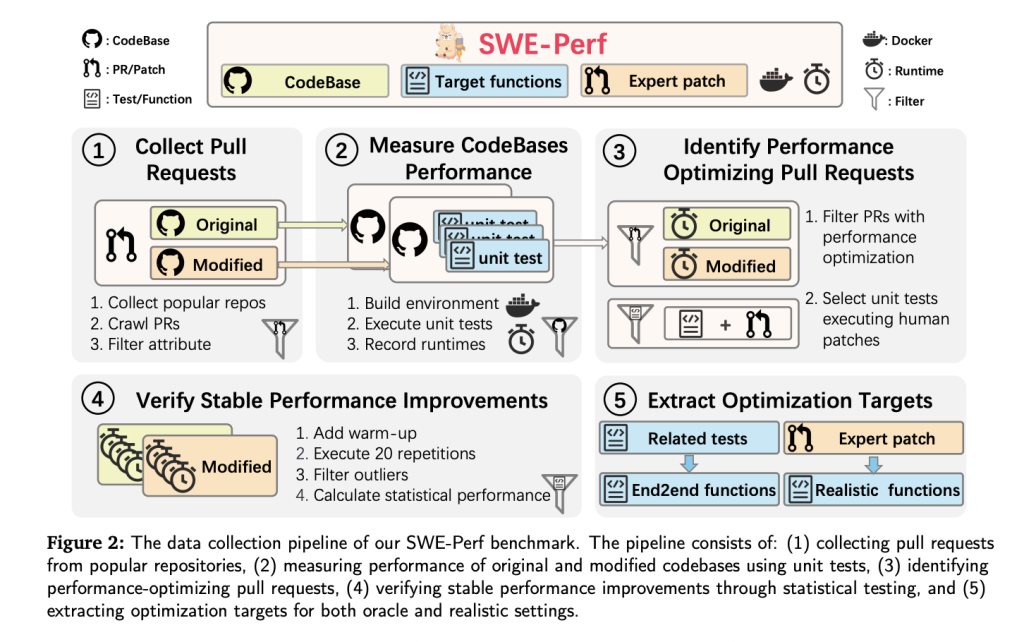
Building a data collection
SWE-Perf was built from more than 100,000 withdrawals requests via high-level ghaseb warehouses. The final data set covered 9 warehouses, including:
- 140 counterparts sponsored Show measuring and stable performance improvements.
- Code complementary Before and after the improvement.
- Target It is classified as Oracle (the file level) or realistically (the rib level).
- Unit tests and peak environments For repetition and performance measurement.
- Pcues of experts composed It is used as gold standards.
To ensure validity, every unit test must be:

- Pass before and after the correction.
- Statistically significantly operating time has shown more than 20 repetitions (MANN-LHITNEY U testing, p <0.1).
Performance is measured using minimal performance (δ), isolation of statistical improvements that are due to the correction during noise filtering.
Standard Settings: Oracle vs. realism
- Oracle preparationThe model receives target functions and corresponding files only. This setting tests topical improvement skills.
- Realistic preparationThe model is given a full warehouse and must be determined and improved independently. This is closer to how human engineers work.
Evaluation measures
SWE-Perf sets a three-level evaluation framework, with an independently a scale:
- ProgressIs it possible to apply the correction resulting from the model cleanly?
- healthDo you keep the correction on job safety (all unit tests pass)?
- performance: Does correction correction improve the time of its operation?
The scales are not assembled in one degree, allowing a more accurate evaluation of the branches between grammatical rightness and performance gains.
Experimental results
The index evaluates many high -class LLMS under the Oracle and realism:
| model | session | performance (%) |
|---|---|---|
| Claude-4 Obus | Oracle | 1.28 |
| GPT-4O | Oracle | 0.60 |
| Gemini-2.5-PRO | Oracle | 1.48 |
| Claud-3.7 (Agentless) | TRUE | 0.41 |
| Claude -3.7 (OpenHands) | TRUE | 2.26 |
| Expert (human correction) | – | 10.85 |
It is worth noting that the best LLM formations with the best performance are significantly short of performance at the human level. The OpenHands method based on the agent, built on Claude-3.7-Sonnet, exceeds other configurations in realistic preparation but still fails to improve the improvements made by experts.
Main notes
- Walk -based frameworks such as OpenHands It is more convenient to improve complex and multiple steps, outperforming direct models demands and a pipeline -based approach such as Agentless.
- Performance decomposes With the increase in the number of targeted functions – LLM struggles with broader improvement ranges.
- LLMS exhibition expansion is limited In long length scenarios, expert systems continue to show performance gains.
- Correction analysis LLMS appears more on low -level code structures (for example, imports, environmental preparation), while experts target high -level semantic abstraction to control performance.
conclusion
SWE-Perf is a pivotal step towards measuring and improving the possibilities of improving LLMS performance in the functioning of realistic software engineering. It reveals a large gap in the ability between current models and human experts, providing a strong basis for future research control over warehouse performance. With the development of LLMS, Swe-Perf can be a North star that directs them towards improving practical software and is widely ready for production.
verify Paper, Jaytab and project page. All the credit for this research goes to researchers in this project.
Care opportunity: Access to the most developer of artificial intelligence in the United States and Europe. 1m+ monthly readers, 500K+ community builders, endless possibilities. [Explore Sponsorship]
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-07-21 08:56:00