
Detecting Text Ghostwritten by Large Language Models – The Berkeley Artificial Intelligence Research Blog
Ghostbuster structure, the most recent method of detecting the text created by artificial intelligence.
Big language models such as Chatgpt are impressive – well, in fact, it has become a problem. Students began to use these models to Ghostwrite tasks, which leads to a chatGPT on some schools. In addition, these models are also vulnerable to the production of text with realistic errors, so you may be cautious readers to know whether the Truntic IQs have been used in ghost news articles or other sources before trusting them.
What can teachers and consumers do? The current tools to detect the text created in artificial intelligence are sometimes weak on data that differ from what has been trained on it. In addition, if these models are classified as true human writing as being created by artificial intelligence, they can endanger students who question their real work.
Our modern paper is presented by Ghostbuster, a modern way to detect the text created by artificial intelligence. Ghostbuster works by finding the possibility of generating each symbol in a document under several weaker linguistic models, then combining jobs based on these possibilities as an entrance to the final work. Ghostbuster does not need to know the form used to create a document, nor the possibility of creating the document within this specific model. This ghostbuster feature makes it particularly useful to detect the text that is likely to be created by an unknown model or a black box model, such as the famous commercial models ChatgPT and Claude, which does not have possibilities. We are particularly interested in ensuring that Ghostbuster is well circulated, so we evaluated it through a set of methods in which the text can be created, including various areas (using newly collected data collections of articles, news and stories), language models or claims.
Examples of the text that has been composed and the creation of Amnesty International from our data collections.
Why this approach?
Many text detection systems created by AI are fragile to classify different types of text (for example, different writing patterns, or different models or claims to generate text). Simple models that use confusion alone cannot capture more complicated features and are especially badly done in new writing fields. In fact, we found that only the confused foundation line was worse than random in some areas, including non -original English amplifier data. Meanwhile, the works based on large language models such as Roberta easily acquires complex features, but overcoming the training data and circulating them badly: we have found that Roberta’s foundation was worse, sometimes worse than the foundation line. The zero lead methods that classify the text without training in the named data, by calculating the possibility of creating the text with a specific model, also tend to do this badly when a different model has already been used to create the text.
How Ghostbuster works
Ghostbuster uses a three -stage training process: computing possibilities, selection of features, and workbook training.
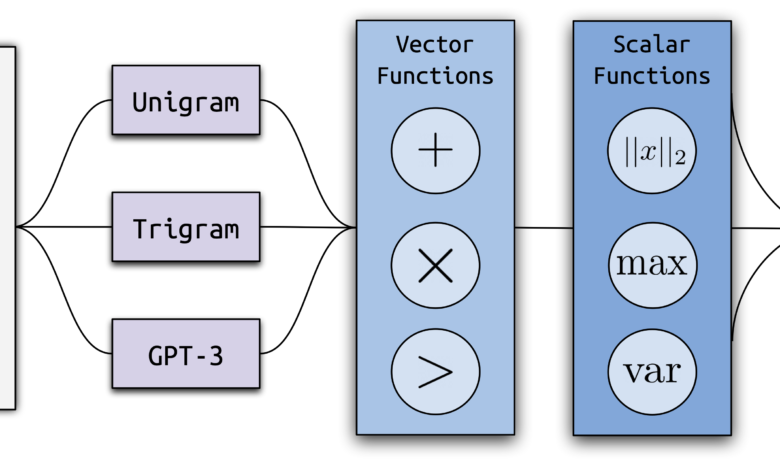
Computing possibilities: We converted each document into a series of vectors by calculating the possibility of generating each word in the document within a series of weakest language models (Unigram model, TRIGRAM model, and non-solid GPT-3 Moody, ADA and Davinci).
Choose features: We used an organized research procedure to identify features, which work by (1) identifying a set of vector operations and numerical number that combines possibilities, and (2) search for useful groups of these processes using the front feature selection, adding frequently the remaining feature.
Class trainingWe have trained a written workbook on the best features based on possibilities and some hand -chosen features.
results
When training and testing it in the same field, Ghostbuster 99.0 F1 has achieved across all three data sets, beating GPTZero with a margin of 5.9 F1 and discovered by 41.6 F1. Outside the field, Ghostbuster 97.0 F1 has achieved in all circumstances, outperforming the discovery of GetethGPT by 39.6 F1 and GPTzero by 7.5 F1. We achieved our basic line for Roberta 98.1 F1 when evaluated in all data sets, but the generalization performance was inconsistent. Ghostbuster outperformed Roberta’s foundation in all fields except for creative writing outside the field, and was much better performance than Roberta on average (13.8 F1).
Results on Ghostbuster’s performance in the field of domain and performance outside the field.
To ensure that Ghostbuster is strong in the range of ways that the user may claim a model, such as requesting different writing patterns or reading levels, we have evaluated the durability of Ghostbuster to many rapid variables. Ghostbuster outperformed all other methods tested on these rapid variables with 99.5 F1. To test the generalization via models, we evaluated the performance on the text created by CLADE, where Ghostbuster also outperforms all other methods tested with 92.2 F1.
Text detection devices created from artificial intelligence have been deceived by lightly editing the text created. We studied the durability of Ghostbuster in modifications, such as sentences or vertebrae, rearranging characters, or replacing words with synonyms. Most of the changes in the sentence or the paragraph level did not significantly affect the performance, although the performance decreased smoothly if the text was released by frequent reformulation, using evaders from commercial detection such as uncovered artificial intelligence, or making many changes at the level of words or personality. Performance was also better on the longest documents.
Since the text detection devices created from artificial intelligence may misuse the Non -original English speakers’ text as created by AI, we have evaluated the Ghostbuster performance on writing the non -original English speakers. All models that were tested were more than 95 % on two of three databases tested, but were worse in the third group of shortening articles. However, the length of the document may be the main factor here, since Ghostbuster also works on these documents (74.7 F1) as in other documents outside the field with a similar length (75.6 to 93.1 F1).
Users who want to apply Gostbuster on the real world cases for potential use of text generation (for example, students written in ChatGPT) must make mistakes more vulnerable to the shortest text, or areas far from those trained on models that were trained in the model, or model created by the human model. To avoid perpetuating algorithm damage, we strongly praise the alleged use of the generation of the text without human supervision. Instead, we recommend using ghostbuster cautious, if the classification of someone writing is created by artificial intelligence may harm them. Ghostbuster can also help in a variety of low -risk applications, including AI’s creation filtering by AI outside the language training and verification model data whether online information sources were created.
conclusion
Ghostbuster is a model for detecting the text created by AI, with 99.0 F1 performance via tested fields, and it represents great progress on current models. It depends well on various fields, demands and models, and it is completely suitable for determining the text of black models or unknown models because it does not require access to the possibilities of the specified model used to create the document.
Ghostbuster’s future trends include explanations for model decisions and improving the durability of attacks that are specifically trying to deceive detection devices. Methods of discovering text from artificial intelligence can also be used as well as alternatives such as a watermark. We also hope that Ghostbuster will help via a variety of applications, such as liquidating the language of the language model training or reporting the AI’s content on the web.
Try ghostbuster here: ghostbuster.app
Learn more about ghostbuster here: [ paper ] [ code ]
Try to guess if the text was created from artificial intelligence here: ghostbuster.app/expermement
2023-11-14 12:30:00


