
From Pretraining to Post-Training: Why Language Models Hallucinate and How Evaluation Methods Reinforce the Problem

LLMS models often create “hallucinations” – incorrect outputs that seem reasonable. Despite the improvements in training and structure methods, hallucinations continue. New research from Openai It provides a strict interpretation: hallucinations stem from the statistical characteristics of learning subject to supervision for the learning subject to supervision, and its continuation is enhanced through the criteria of unprecedented evaluation.
What makes hallucinations statistically inevitable?
The hallucinogenic research team explains that it is inherent errors in obstetric modeling. Even with completely clean training data, the interrupted goal used before pre -pre -previous provides statistical pressure that produces errors.
The search team reduces the problem to the task of classification subject to supervision called Is-II-Valid (IIV): Determine if the output of the model is valid or wrong. They prove that LLM’s obstetric error rate is at least twice the IIV classification rate. In other words, hallucinations occur to the same reasons that appear wrong in the learning subject to supervision: cognitive uncertainty, bad models, distribution or loud data.
Why rare facts lead to more hallucinations?
One driver is Single rate– Part of the facts that appear only once in data training. Through the measurement for a good estimate of the missing block, if 20 % of the facts are vocabulary, then at least 20 % gel will take place. This explains the reason why LLMS is reliably reliable to frequently repeated facts (for example, Einstein’s birthday) but it fails to those that are rarely specific.
Can poor model families lead to hallucinations?
Yes. Halosa also appears when the model category cannot be adequately represented. Classic examples include N-Gram models that generate abnormal sentences, or modern symbolic models imagine messages because letters are hidden inside sub-codes. These representative limits cause systematic errors even when the data itself is sufficient.
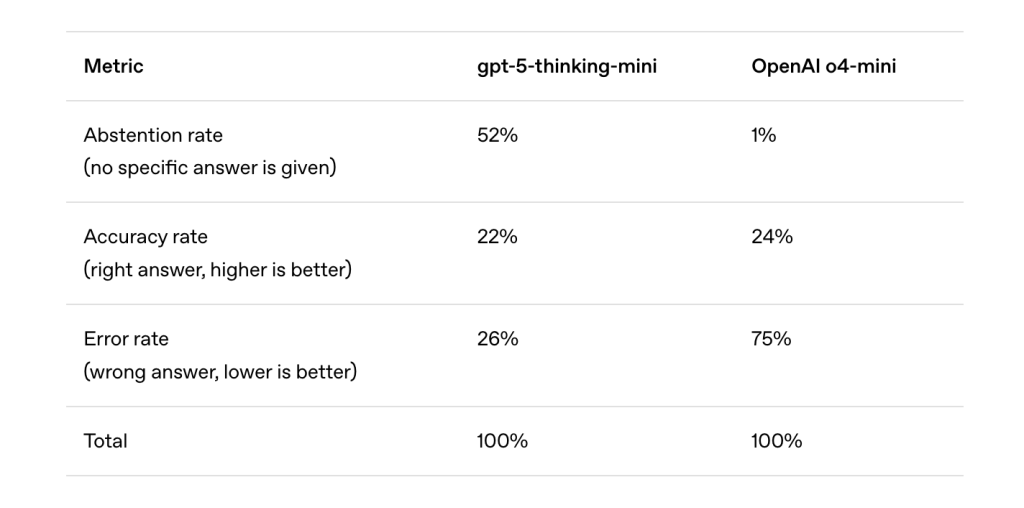
Why don’t you remove training after training?
Post -training methods such as RLHF (learning reinforcement from human comments), DPO and RLAIF reduce some errors, especially harmful or conspiracy outputs. But the excessive hallucinations of confidence are still existing because the evaluation incentives are not specific.
Like guessing students in multi -options selection exams, LLMS is a bonus to be deceived when you are not sure. Most of the criteria-such as MMLU, GPQA and Swe-Bench-dominated a binary registration: the right answers to obtain credit, and refrain from (“I don’t know”) do not get incorrect answers more than cruelty. Under this scheme, guessing increases to the maximum standard degrees, even if it enhances hallucinations.
How to enhance the leaders of hallucinations?
Review of popular standards shows that they all use bilateral appreciation without any partial credit for uncertainty. As a result, the models that honestly express uncertainty are worse than those that they always guess. This creates a systematic pressure for developers to improve models to get confident answers instead of calibration.
What changes can reduce hallucinations?
The research team argues that hallucinations reform requires a technical social change, not only the new evaluation wings. They suggest Explicit confidence goalsThe criteria must clearly determine penalties for the wrong answers and partial credit of abstinence.
For example: “Answer only if you are> 75 % of confidence. The mistakes lose two points; the correct answers earn 1;” I don’t know “earn 0.”
This design reflects the real world’s exams such as SAT and GRE formats earlier, as the guess was sanctions. He encourages Behavioral calibrationThe model refrains from refraining from their confidence less than the threshold, which results in fewer hallucinations in confidence while continuing to improve standard performance.
What are the broader effects?
This work re -expanding hallucinations as a predictive results for training goals and different evaluation instead of irreplaceable dodgers. Highlighting the results:
- The inevitability of what preceded it: Hallus is parallel to misconduct errors in the supervision learning.
- Promoting post -training: Bilateral grades stimulating guessing.
- Evaluation repair: Adjusting prevailing standards for a reward for uncertainty can reorganize incentives and improve the merit with confidence.
By linking hallucinations to the existing learning theory, the research removes mystery from its origin and suggests practical mitigation strategies that turn responsibility from the typical structure to the evaluation design.
verify Paper and technical details here. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-09-07 04:56:00



