Meta Superintelligence Labs Introduces REFRAG: Scaling RAG with 16× Longer Contexts and 31× Faster Decoding
A team of researchers from SuperINTelligence Meta, National University of Singapore and Rice University revealed Rafah (representation of the piece)Rag’s decoding framework. Refrag Windows Llm extends by 16 x And achieve up to a 30.85 x acceleration in time for the first time (TTFT) Without prejudice to accuracy.
Why is the long context the bottleneck of LLMS?
The mechanism of attention in large language models is used in the way of the spring with the length of the input. If the document is twice its length, the cost of the account and the memory may grow four times. This not only slows down the inference, but also increases the size of the main storage memory of the main value (KV), which makes large context applications insecure in production systems. In RAG settings, most of the clips that have been slightly retrieve contribute to the final answer, but the model still pays the full spring price to treat it.
How is the rip and the context of the context?
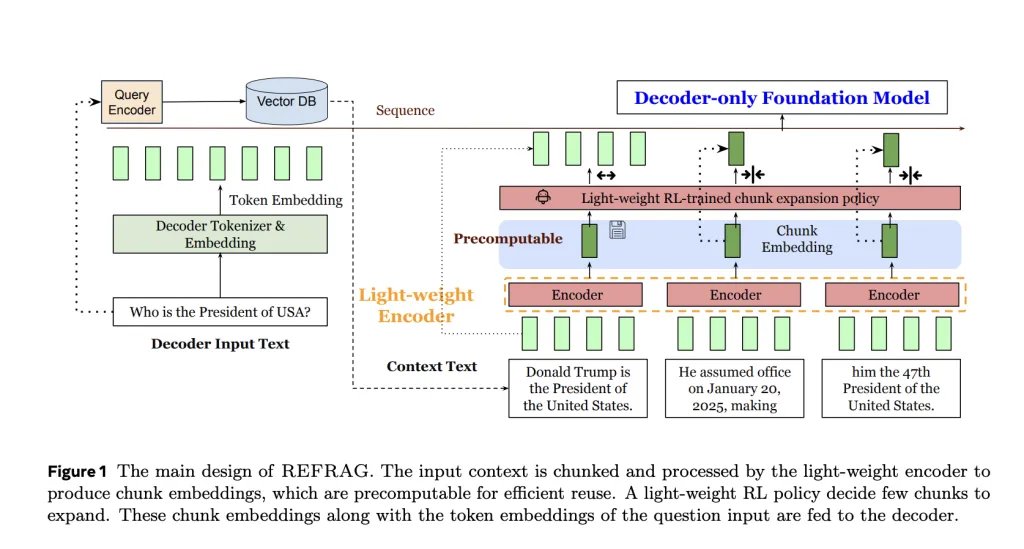
It offers a lightweight siphine ribg. It divides the clips that are recovered into parts of fixed size (for example, 16 symbol Include a piece. Instead of feeding thousands of raw symbols, the unit of coding treats this shorter sequence of implications. The result is a 16 x decrease in the length of the sequenceWith no change in LLM architecture.
How is the acceleration achieved?
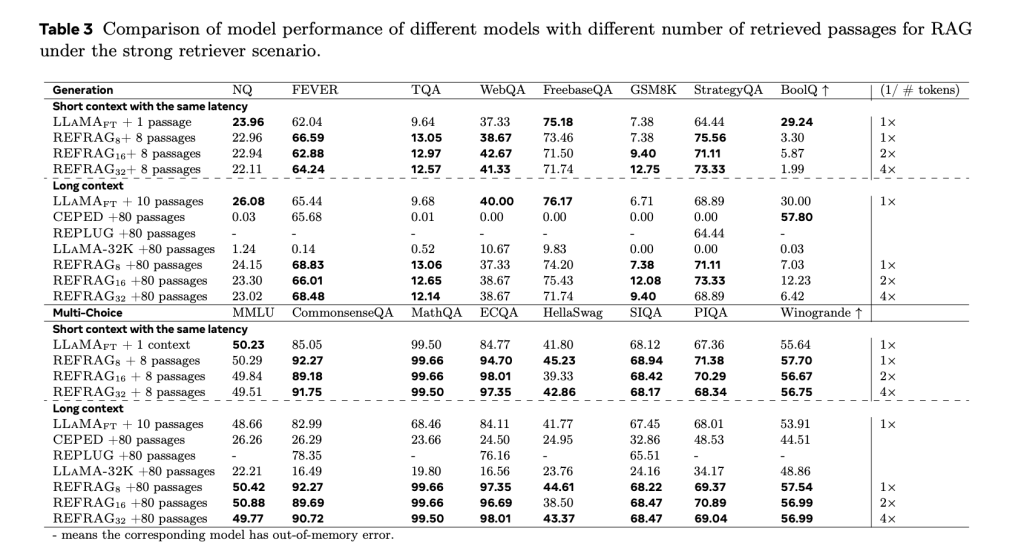
By shortening the sequence of insertion of the coding unit, the Refrag reduces the Spronary Attention Account and reduces the KV cache. Experimental results show 16.53 x TTFT acceleration at K = 16 and 30.85 x acceleration in K = 32Specger CEPE over the latest model (which only achieved 2-8 x). Productivity also improves through 6.78 x Compared to Lama’s foundation lines.
How do you maintain an accuracy?
Reinforcement learning policy (RL) oversees pressure. It determines the most intensity of information and allows them to overcome pressure, and feed raw symbols directly in the unit of coding. This selective strategy ensures that critical details – such as fine numbers or rare entities – are not lost. Through multiple criteria, confusion has been kept or improved compared to CEPE while working at a long time of transition.
What do experiences reveal?
Riprag is equipped on Slimpajama Corpus (Books + Arxiv) and tested on long text data collections including Book, Arxiv, PG19 and ProPile. On the standards of rags, multiple conversation tasks, and summarizing long year, Refrag has constantly outperformed the powerful basic lines:
- 16 x context extension Beyond standard lama-2 (4K codes).
- ~ 9.3 % improved confusion On CEPE across four data sets.
- Better accuracy in the weak recovery settings, as the non -relevant corridors dominate, due to the ability to treat more corridors under the same cumin budget.
summary
Refrag explains that LLMS Long-Contentxt should not be slow or thirsty for memory. By compressing the corridors that are recovered in compressed inclusion, expanding the important scope only selectively, and rethinking how to make the slurry of the rag, making the Superintelligence Meta laboratories that can be processed much larger with their operation significantly. This makes large context applications-such as the entire reports analysis, dealing with multiple conversations, or limiting the establishment of the institution’s rag systems-not only possible but effective, without prejudice to accuracy.

Common questions
Q1. What is the rhetoric?
Refrag (RAG) is a meta -decoding framework from the Meta Superintecessance laboratories that press the corridors that have been recovered in the implications, allowing the faster and long inference in LLMS.
Q2. What is the fastest to be in the direction compared to the current methods?
Rahal greets even 30.85 x faster time than the first time (TTFT) and 6.78 x Productivity improvement Compared to Lama’s foundation, while outperforming CEPE.
Q3. Does pressure reduce accuracy?
no. The reinforcement learning policy guarantees that critical pieces remain uncompromising, while maintaining the main details. Through standards, accuracy has been preserved or improved improved for previous methods.
Q4. Where will the symbol be available?
Meta SuperINIGE LABS will release Refrag on GitHub in Facebookresearch/Refrag
verify Paper here. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-09-07 20:49:00