
Google AI Releases VaultGemma: The Largest and Most Capable Open Model (1B-parameters) Trained from Scratch with Differential Privacy

Google Ai Research and DeepMind have released VAULTGEMA 1BThe largest large linguistic model is fully trained with Differential Privacy (DP). This development is a major step towards building strong Amnesty International models and maintaining privacy.
Why do we need a differential privacy in LLMS?
Large language models trained on extensive data collections on the Internet are vulnerable Conservation attacksWhere sensitive or personal information can be extracted from the form. Studies have shown that craft training data can appear, especially in open -weight versions.
The differential privacy provides a Sports guarantee This prevents any one -training example from affecting the model. Unlike the methods that apply to the DP only during the accurate control, the vaultgemma is executed Before the full private opinionEnsure that privacy protection begins at the foundation level.

What is the structure of Vaultgemma?
VAULTGEMA is similar to the architectural aspect of the previous GEMMA models, but it has been improved for private training.
- Form size1B parameters, 26 layers.
- Transformer: Only decomposition.
- ActivationGEGLU with feeding dimension from 13,824.
- attention: Multi -centers (MQA) with the global range of 1024 symbols.
- normalization: RMSNORM in pre -perfume composition.
- code: Sencepiece with 256K vocabulary.
A noticeable change is Reducing the length of the sequence to 1024 symbolsWhich reduces the cost account and enables the largest impulses of the bonds of Dubai ports.

What data used for training?
VAULTAMMA has been trained on The same collection is 13 trillion As GEMMA 2, it consists primarily of the English text of web documents, symbol and scientific articles.
The data collection has undergone several liquidation stages to:
- Remove unsafe or sensitive content.
- Reducing exposure to personal information.
- Preventing evaluation data pollution.
This guarantees both safety and fairness in measurement.
How was the differential privacy applied?
Vaultgemma used DP-SGD (Displaced RAM) With the gradient and add -on -to -point. Implementation has been built Jax privacy and Improved expansion improvements:
- An example of an example of an example For parallel efficiency.
- Pleading accumulation To simulate large batches.
- Poleton cut Integrated in data rally to take effective samples while moving.
Model A. Official DP guarantee From (ε ≤ 2.0, δ ≤ 1.1E – 10) at the sequence level (1024 symbols).
How do scaling laws work for private training?
Training of large models under Dubai ports restrictions requires new scaling strategies. The development of the Vaultgemma team DP private scaling laws With three innovations:
- Modeling the optimal learning rate Using upper seizures through training operations.
- Boundary extrapolation of loss values To reduce dependence on intermediate checkpoints.
- Semi -raramite seizures For generalization via the size of the model, training steps and noise noise ratios.
This methodology enabled the accurate prediction of the investigative loss and the use of effective resources on the TPUV6E training group.
What are the training formations?
VAltMMma has been trained 2048 tpuv6e chips Using the GSPMD and Megascale XLA assembly.
- The size of the batch: ~ 518k codes.
- Repeated training: 100000.
- Noise: 0.614.
The achieved loss was among the 1 % of the predictions of the Dubai Ports law, and the validity of the approach.
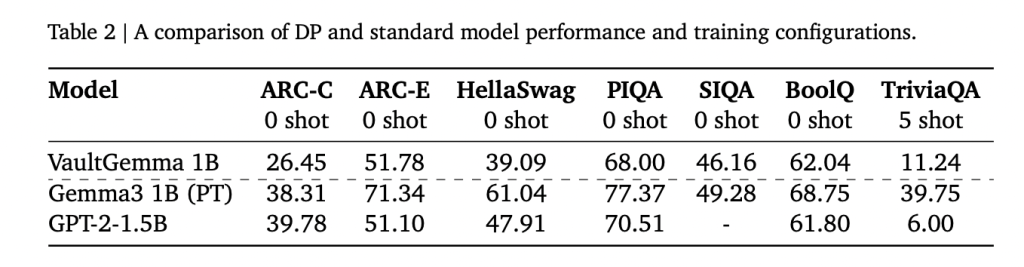
How do you perform vaultgemma compared to non -private models?
On academic standards, vaultgemma tracks its non -private counterparts but shows a strong benefit:
- Arc-C: 26.45 compared to 38.31 (GEMMA-3B).
- PIQA: 68.0 versus 70.51 (GPT-2 1.5B).
- Triviaqa (5 shots): 11.24 versus 39.75 (GEMMA-3B).
These results indicate that the DP -trained models are currently comparable Models not private for about five years. More importantly, memorization tests confirmed this Do not leak training data It was discovered in VAULTGEMA, unlike non -private GEMMA models.
summary
In short, VAULTGEMA 1B proves that large -scale language models can be trained with strict differential differential guarantees without making them inappropriate for use. While the tool gap remains compared to non -private counterparts, the version of both the model and the training methodology provides society with a strong basis for progress in private artificial intelligence. This work indicates a shift towards building models that are not only capable but also safe, transparent and preserving privacy.
verify Paper, embracing face model and Technical details. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-09-13 07:54:00



