Xiaomi Released MiMo-Audio, a 7B Speech Language Model Trained on 100M+ Hours with High-Fidelity Discrete Tokens

The MIMO team at Xiaomi Mimo-Audio released, a 7 billion audio formal model that runs one rebel goal on the intertwined text and appreciated speech, exceeding 100 million hours of sound.
What’s new actually?
Instead of relying on the mission or lost vocal codes, the Mimo-UADIO uses a distinctive symbol of RVQ (the remaining vector quantity) that targets both semantic loyalty and high-quality reconstruction. Tokeenizer works at a speed of 25 Hz and comes out 8 layers of RVQ (≈200 symbols/s), allowing to reach LM to “unspecified” speech features that can be self -designed alongside the text.
Architecture
To deal with the sound/text rate mismatch, the system packs four time time per correction of LM consumption (decrease 25 Hz → 6.25 Hz), then rebuild complete RVQ flows with a modified RVQ with a causal correction decoding unit. The multi -layer RVQ generation scheme delayed predictions for each symbol notebook to stabilize the synthesis and respect the dependencies between the layer. All three parts-the coding of the dish, the MIMO-7B spine, and the coding of the correction-under one experienced goal.
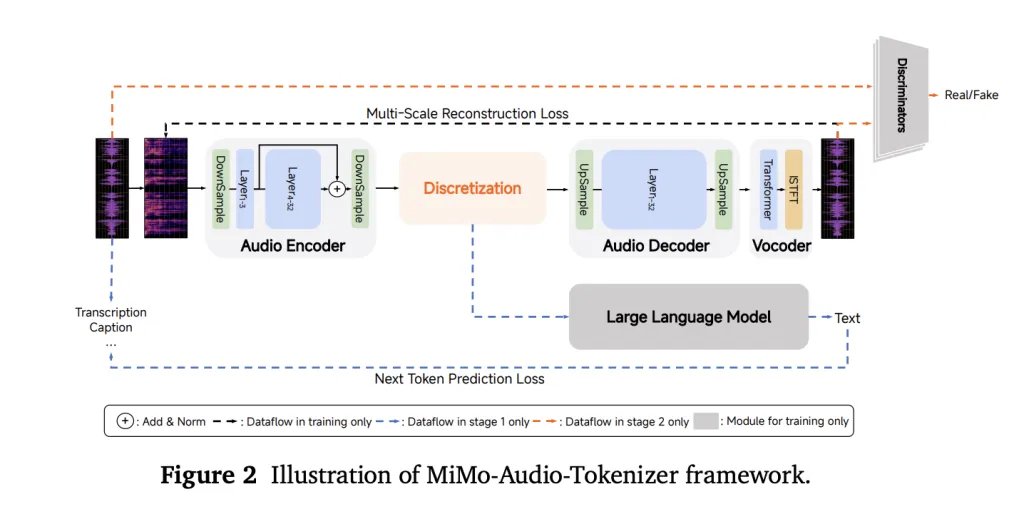
The domain is algorithm
The training continues in two large phases: (1) the “understanding” stage that improves the loss of the text on the intertwined texts of the text, and (2) a common stage “understand + generation” that manages audio losses for continuing speech, S2T/T2S tasks, and data similar to the instructions. The report emphasizes an account/data threshold, as it seems that a little shot behavior “works to run”, echoing the appearance curves seen in LMS just large.
Standards: Speech and General Voice
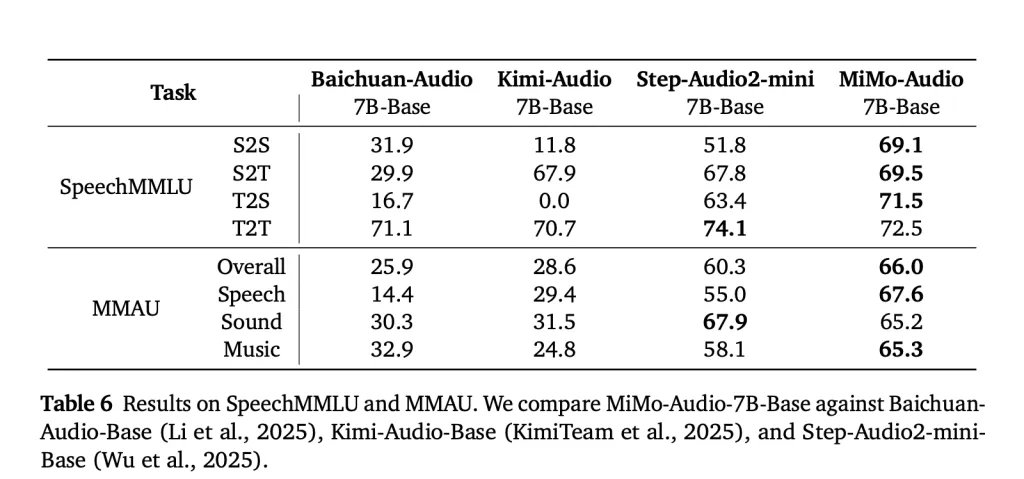
MIMO-UADIO is evaluated on the wings of speech (for example, speech) and the voices understanding standards (for example, MMAU), reporting strong degrees through speech, sound, music and a reduced “method” between the text and speech settings in the discourse. Xiaomi also releases MIMO-UADIO-EVALA general tool group to reproduce these results. Available online online (continuing speech, transforming sound/passion, translating speech, translating speech, translating speech, translating speech (continuing speech, transforming the voice/passion, translating speech, translating speech, and translating speech))
Why is this important?
This approach is intentionally simple-there is no multi-head tower, nor the ASR/TTS targets are dedicated at some time before predicting-just predictions similar to GPT on Without losing Voice symbols in addition to the text. The main engineering ideas are (1) the distinctive symbol that LM can actually use without eliminating the identity of charity and the identity of the speaker; (2) Correction to keep the sequence lengths to be controlled; And (3) delay the decoding of RVQ to maintain quality at the time of obstetrics. For the teams that build the spoken agents, these design options translate into editing a letter into a few speech and continuing strong speech with the minimum specified tasks.
6 fast food:
- The high -resolution, distinctive symbol
MIMO-UADIO uses a dedicated icon for RVQ that works at 25 Hz with 8 active symbol books, ensuring that the symbols in speech maintain the identity of miscarriage, Timbre, and the identity of the speaker while keeping it friendly LM. - Serial modeling
The model reduces the length of the sequence by collecting 4 timers to one correction (25 Hz → 6.25 Hz), allowing 7 to LLM to deal with long speech efficiently without getting rid of the details. - The next unified goal
Instead of separating the heads of ASR, TTS or dialogue, MIMO-UADIO is trained under one single prediction loss through the text and intertwined sound, simplifying architecture with multi-task generalization support. - A few emerging capabilities
Little behaviors such as continuing speech, transforming the sound, transmitting passion, and translating speech are accepted as soon as the training exceeds a large -scale data threshold (about 100 meters, trillion of symbols). - Standard driving
Mimo-upio determines modern degrees on speech (S2S 69.1, T2S 71.5) and MMAU (66.0 in general), while reducing the gap in the text method to words to 3.4 points only. - Open the open ecosystem
Xiaomi provides Tokenizer points, 7 B checkpoints (base and instructions), MIMO-UADIO-EVAL tools, general illustrations, enabling researchers and developers to test and expand speech intelligence to speech in open source pipelines.
summary
MIMO-UADIO explains that the distinctive “losing” symbol that is still based on RVQ, along with the pre-pre-leading pre-lead, is sufficient to cancel the lock of a few speech intelligence without the task heads. Pact 7B-Tokenizer → Patch Encoder → LLM → Dechoder- urges the gap to the audio/text rate (25 → 6.25 Hz) and maintains the Prosody and Oberted identity by decoding the late multi-layer RVQ. Experimental, the model narrows the Modality Text ↔spich gap, depends on the standards of speech/sound/music, and supports the editing of the S2S within the context.
verify Paper, technical details and Jaytap page. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.

Michal Susttter is a data science specialist with a master’s degree in Data Science from the University of Badova. With a solid foundation in statistical analysis, automatic learning, and data engineering, Michal is superior to converting complex data groups into implementable visions.
🔥[Recommended Read] Nvidia AI Open-Sources VIPE (Video Forms)
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-09-20 08:23:00