
SwiReasoning: Entropy-Driven Alternation of Latent and Explicit Chain-of-Thought for Reasoning LLMs
SwiReasoning is a decoding framework that allows the LLM heuristics teacher to determine when it is appropriate to do so Think about latent space And when? Write a clear series of ideasuse Time-wise confidence estimated from entropy trends in the following token distributions. The way is Free of training, Atheist modeland goals Pareto superior Accuracy/efficiency trade-offs in mathematics and STEM standards. Reported results are shown +1.5%-2.8% Medium resolution improvements with unlimited number of icons and +56%-79% Average token efficiency gains under constrained budgets; In AIME’24/’25, it reaches maximum inference accuracy previously From standard CoT.
What changes in SwiReasoning at inference time?
The control unit monitors the decoder The following symbolic entropy To form a Trust wise signal. When confidence is low (entropy is trending up), it enters Underlying logic– The model continues to think Without emitting symbols. When trust recovers (entropy goes down), it returns back to Clear logicissuing CoT tokens to merge and commit to a single path. A Control the number of switches Limits the maximum number Thinking block shifts To suppress overthinking before finishing the answer. This dynamic rotation is the underlying mechanism behind the reported accuracy gains for each token.
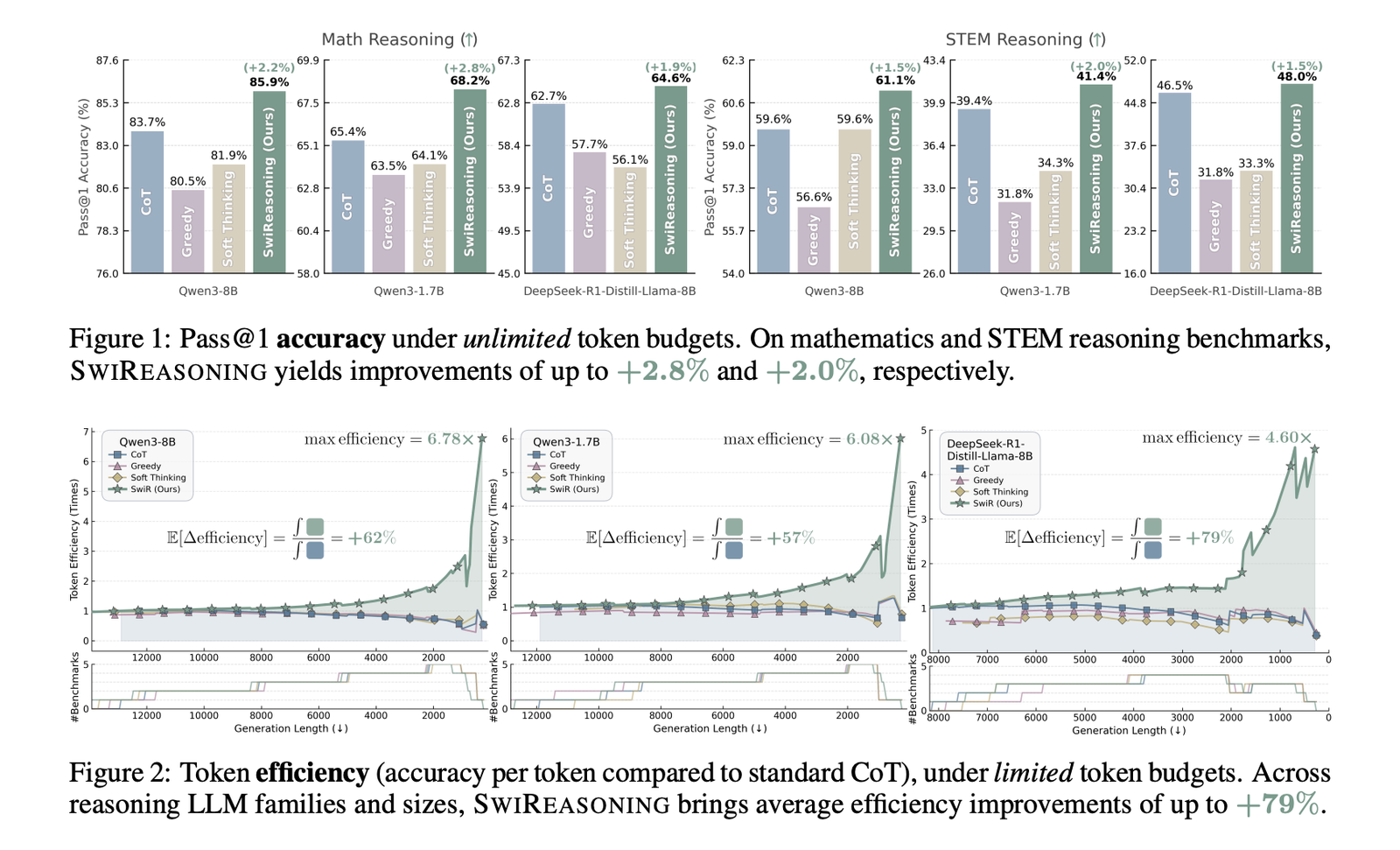
Results: Accuracy and efficiency in standard suites
Reports improvements across STEM math and reasoning tasks:
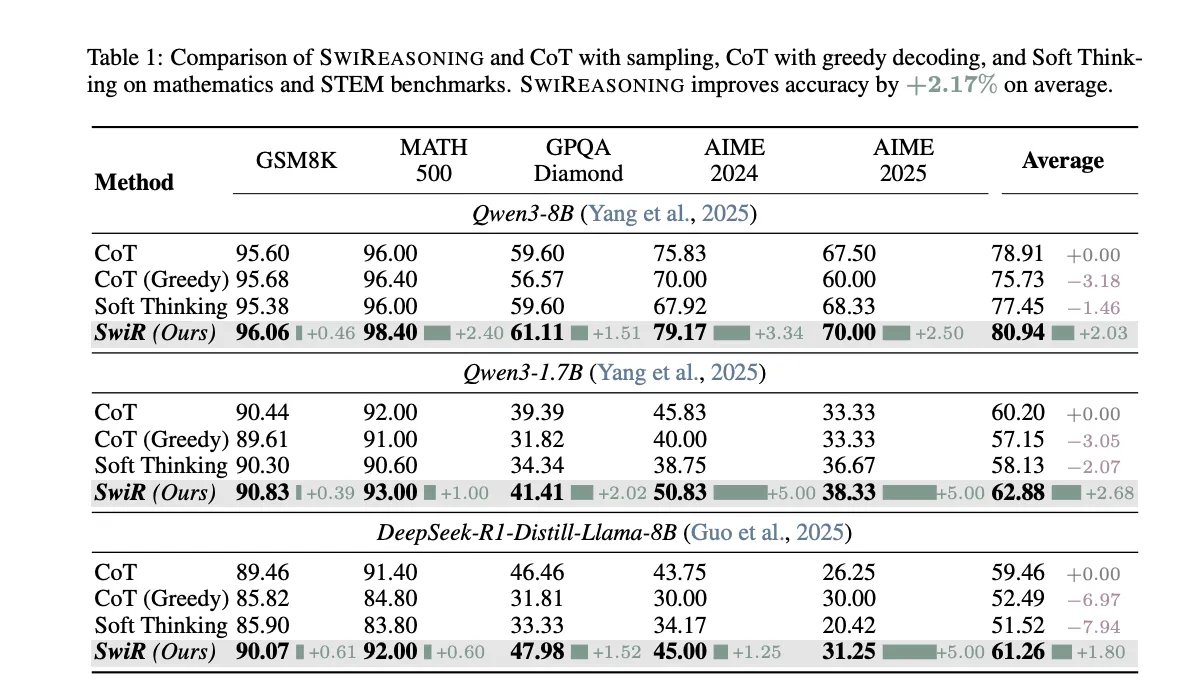
- Pass@1 (unlimited budget): Accuracy goes up to +2.8% (mathematics) and +2.0% (STEM) in Figure 1 and Table 1, with a +2.17% Average over baselines (CoT with sampling, CoT greedy, CoT soft thinking).
- Token efficiency (limited budgets): Average improvements Up to +79% (Figure 2). Our comprehensive comparison shows that SwiReasoning is up to The highest token efficiency is at 13/15 Ratings, with +84% Average improvement on CoT across those settings (Figure 4).
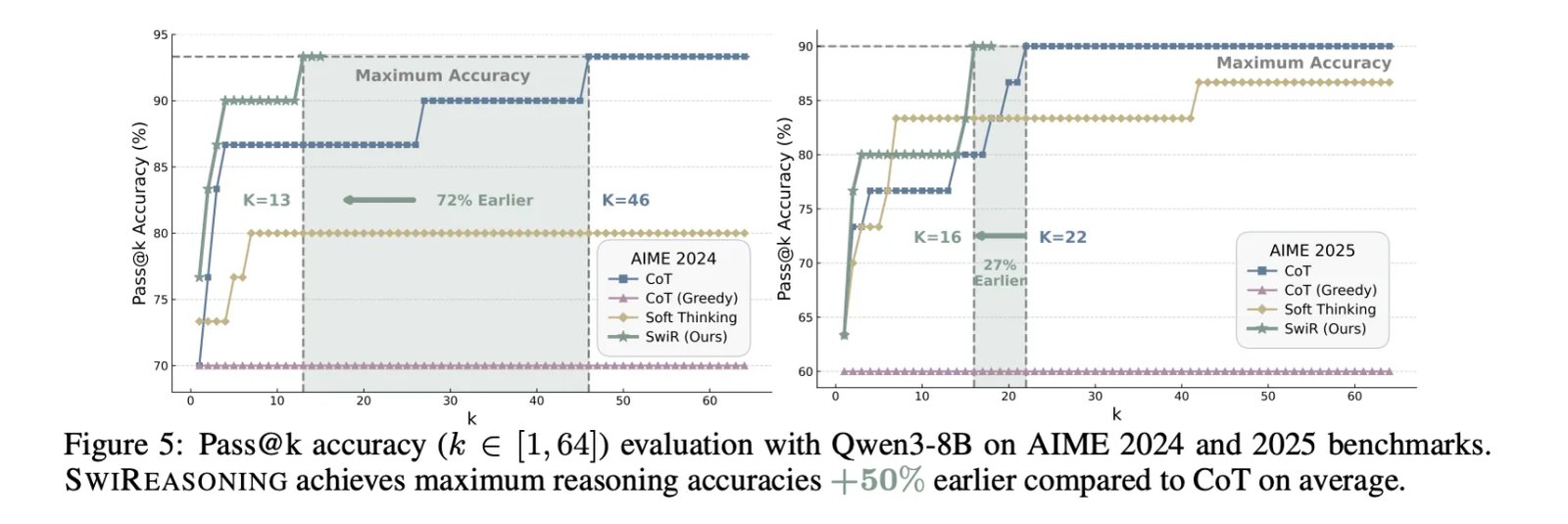
- Pass@k dynamics: With Qwen3-8B running Im 2024/2025, Maximum inference accuracy is achieved +50% earlier of CoT on average (Figure 5), indicating faster convergence to the ceiling with fewer sampled paths.
Why switching helps?
Express CoT Discrete and readable but locked into one path prematurely, which can lead to useful alternatives being overlooked. Underlying logic Continuous and information-intensive at each step, but purely latent strategies may disperse the probability mass and hinder convergence. SwiReasoning adds a Trust-guided alternation: Latent stages extend exploration when the model is uncertain; Explicit stages exploited Increase confidence to solidify the solution Commit codes only when they are useful. the Control the number of switches It regulates the process by reducing oscillations and limiting “silent” wandering for long periods – addressing both Loss of accuracy from spreading and Waste is symbolic of overthinking These have been cited as challenges to latent training-free methods.
Positioning versus baselines
The project compares against Children’s bed with sampler, Greedy cradleand Soft thinkingReport A +2.17% The average accuracy lift with unlimited budgets (Table 1) is consistent Efficiency per code Advantages under budget constraints. Plasmodium Pareto frontier Shifts outwards – either Higher resolution at the same budget or Similar accuracy with fewer symbols-Lir Different model families and different scales. In AIME’24/’25, Pass @k The curves show that SwiReasoning reaches the performance ceiling With fewer samples of CoT, reflecting the improvement Convergence behavior Rather than just better raw roofing.
Key takeaways
- Training-free controller: SwiReasoning alternates between latent reasoning and explicit chain of thoughts using global confidence from the following symbolic entropy directions.
- Efficiency gains: Reports +56–79% Average token efficiency improvements under constrained budgets versus CoT, with larger gains as budgets tighten.
- Lifting accuracy: He achieves +1.5–2.8% Average Pass@1 improvements in math/STEM standards with unlimited budgets.
- Faster convergence: In AIME 2024/2025, it reaches maximum inference accuracy previously From CoT (improved Pass@k dynamics).
SwiReasoning is a useful step toward practical control of the “inference policy” at decoding time: it is training-free, slots behind the token artifact, and reveals measurable gains in math/STEM clusters by switching between latent and explicit CoT using a confidence signal in the entropy direction with a specified number of keys. Open source BSD implementation and clear flags (--max_switch_count, --alpha) Make replication straightforward and lower the stacking barrier with orthogonal efficiency layers (e.g., quantization, speculative decoding, KV cache tricks). The value proposition of this method is “accuracy per token” rather than raw SOTA accuracy, which is operationally important for budgeted inference and clustering.
verify paper and Project page. Feel free to check out our website GitHub page for tutorials, codes, and notebooks. Also, feel free to follow us on twitter Don’t forget to join us 100k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of AI for social good. His most recent endeavor is the launch of the AI media platform, Marktechpost, which features in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand by a broad audience. The platform has more than 2 million views per month, which shows its popularity among the masses.
🙌 FOLLOW MARKTECHPOST: Add us as a favorite source on Google.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-10-13 07:24:00



