
A 100-AV Highway Deployment – The Berkeley Artificial Intelligence Research Blog

We have published 100 reinforcement learning vehicles (RL)-they are controlled in highways traffic in the peak hour to smooth congestion and reduce fuel consumption for everyone. Our goal is to address the waves of “stopping and abandoning”, that frustrated slowdown and races that usually have no clear cause but lead to crowding and large energy waste. To train control units adherence to effective flow, we have built rapid simulations based on data that interact with RL factors with them, and learn to maximize energy efficiency while maintaining productivity and working safely around human operation programs.
In general, a small percentage of well -controlled independent vehicles (AVS) is sufficient to improve traffic flow and fuel efficiency significantly for all drivers on the road. Moreover, trained control units are designed to be published on most modern vehicles, which operate in an ultraviolet way and rely on standard radar sensors. In our last paper, we explore the challenges of the RL deployment units widely, from simulation to the field, during the experience of 100 cars.
The challenges of the mineral jam
The wave of stopping and moving moves back through the traffic on highways.
If you are driving your car, you certainly faced the frustration of stopping and mobility waves, then this is the inexplicable slowdown that appears from anywhere and then suddenly died. These waves are often caused by small fluctuations in our behavior in driving that enlarges through the flow of traffic. We naturally adjust our speed based on the car in front of us. If the gap opens, we are rushing to keep up with. If they are the brakes, then we slow down. But due to the time of our non -scratch reaction, we may be a little more difficult than the car in the front. The next driver behind us does the same, and this continues to amplify. Over time, what a little hook has begun turns into a full traffic stop. These waves move back through a traffic current, which leads to a significant decrease in energy efficiency due to frequent acceleration, accompanied by CO2 Emissions and accident risk.
This is not an isolated phenomenon! These waves everywhere on the crowded roads when the traffic density exceeds a critical threshold. How can we address this problem? Traditional methods such as slope measurement and variable speed limits try to manage traffic flow, but they often require costly infrastructure and central coordination. The most developmental approach is to use AVS, which can adjust driving behavior dynamically in actual time. However, the AVS inclusion between the two human drivers is not enough: they must also lead in a more intelligent way that makes traffic better for everyone, the place where RL comes.
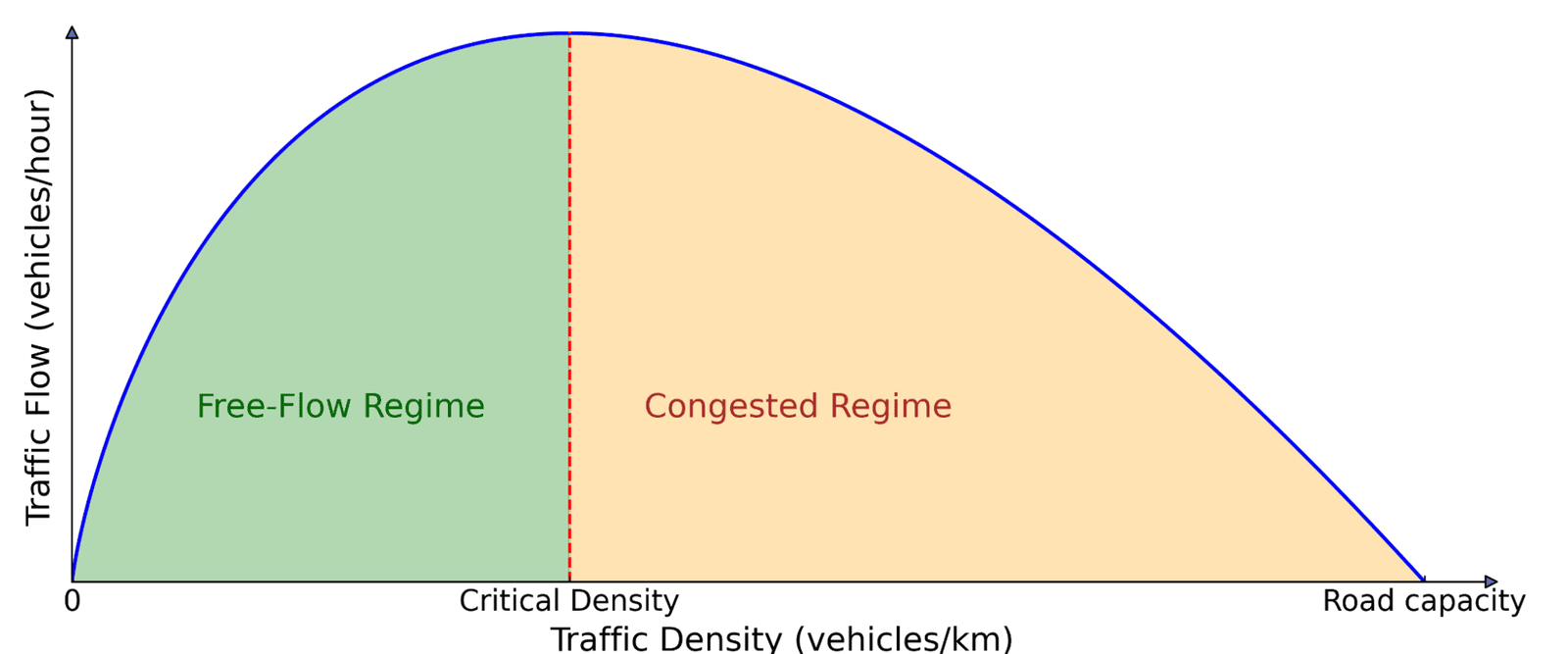
The primary graph for traffic flow. The number of cars on the road (density) affects the amount of traffic that moves forward (flow). With low intensity, adding more cars increases the flow because more vehicles can pass. But besides the decisive threshold, the cars begin to ban each other, which leads to crowding, adding the addition of more cars actually the movement in general.
Reinforce learning for AVS
RL is a strong control approach where the worker learns to increase the reward signal through interactions with the environment. The agent collects experience through experience and error, learn from his mistakes, and improves time. In our case, the environment is a mixed traffic scenario, where AVS learns driving strategies to calm the waves of stopping and reduce and reduce fuel consumption for themselves and the nearby vehicles driven by a person.
The training of RL factors requires rapid simulations with real traffic dynamics that can repeat the cessation of highways. To achieve this, we took advantage of the experimental data collected on the 24th (I-24) highway near Nashville, Tennessee, and we used it to build a simulation where vehicles return the highway paths, creating an unstable traffic that AVS learns behind it.
Simulation restarting the highway path that displays many stops and mobility waves.
We are designed with the publication mode in mind, making sure that it can work using only basic sensor information about themselves and the car in the foreground. The notes consist of the AV speed, the speed of the pioneering car, and the space gap between them. Looking at these inputs, the RL factor describes either an immediate acceleration or the speed required for AV. The main advantage of using these local measurements only is that RL control units can be deployed on most modern vehicles in a decentralized manner, without the need for an additional infrastructure.
The reward design
The most challenging part is to design a reward function, when glorified, in line with the different goals that we want to achieve AVS:
- Wave homogeneity: Reducing stop oscillations.
- Energy efficiency: Low fuel consumption for all vehicles, not just AVS.
- safety: Be sure of the following reasonable distances and avoid sudden braking.
- Driving comfort: Avoid aggressive acceleration and retreat.
- Commitment to human leadership standards: Make sure the “normal” driving behavior that does not make the surrounding drivers is uncomfortable.
It is difficult to balance these goals together, as appropriate transactions must be found for each term. For example, if reducing fuel consumption dominates the reward, the RL AVS learns to stop in the middle of the highway because this energy is perfect. To prevent this, we have provided the minimum dynamic and the maximum gap to ensure a safe and reasonable behavior while improving fuel efficiency. We also punished the fuel consumption for the vehicles that a person drives behind AV to inhibit them from learning a selfish behavior that improves energy savings for AV at the expense of the surrounding traffic. In general, we aim to achieve a balance between energy saving and reasonable and safe driving behavior.
Simulation results

A clarification of the minimum dynamic and the maximum gap, through which the AV can work freely to soften the traffic as possible.
The typical behavior that AVS learned is to maintain slightly larger gaps than human drivers, allowing them to absorb the next, and possibly sudden slowdown, more effectively. In simulation, this approach led to great fuel savings of up to 20 % in all road users in the most crowded scenarios, with less than 5 % of AVS on the road. These AVS should not be private vehicles! Standard consumer cars can be equipped with smart adjustment powers (ACC), which we have extensively tested.
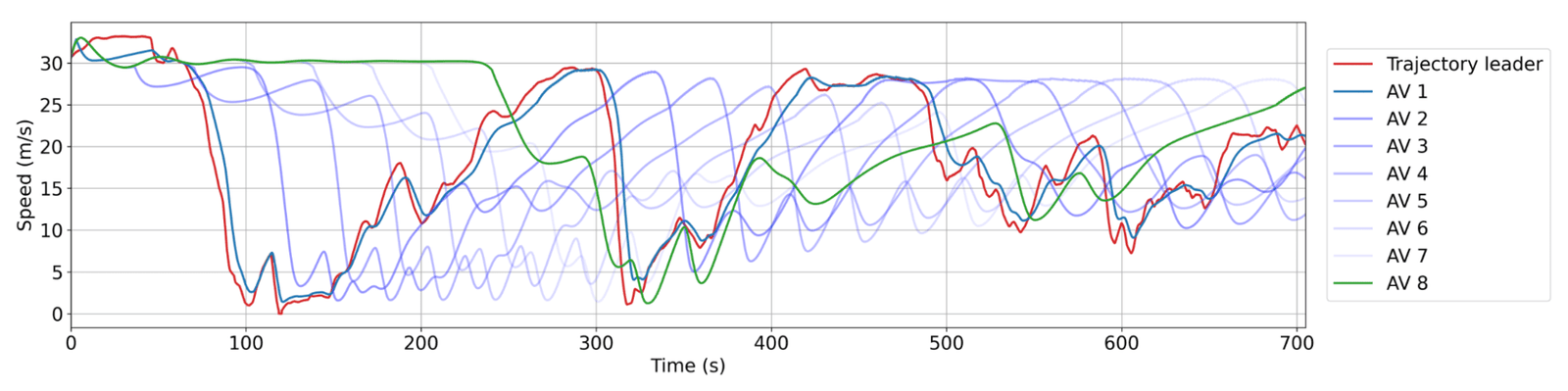
RL AVS behavior homogeneity. Red: a human path from the data collection. Blue: successive AVS in the family, where AV1 is closest to the human path. There are usually between 20 and 25 human vehicles between AVS. Each Av does not slow down or accelerates its fastest leader, which reduces the wave capacity over time and thus energy savings.
100 Av Field Test: RL spread widely


We have 100 parked cars at our operating center during the experience week.
Looking at the results of promising simulation, the next natural step was to bridge the gap from simulation to the highway. We took the trained RL control units and posted them on 100 vehicles on I-24 during the peak hours of the peak over several days. This wide range, which we called Megavandertest, is the largest experience in the field of mixed traffic in the field of mixed traffic.
Before deploying RL console in this field, we trained and evaluated them widely in simulating and checking their health on devices. In general, the steps towards the relevant publication:
- Training in data -based simulation operations: We used the highway traffic data from I-24 to create a training environment with realistic wave dynamics, then verify the validity of the trainer’s performance and strength in a variety of new traffic scenarios.
- Publishing on devices: After checking the validity of robots programs, the trained console is loaded on the car and is able to control the speed of the car specified. We work by controlling the car on board, which acts as a low -level safety control unit.
- Standard control framework: One of the main challenges during the test was not to reach the leading car information sensors. To overcome this, the RL console was merged into a pyramidal system, Megacontroller, which combines the speed scheme guide that explains the estuaric traffic conditions, with the RL console as the final decision maker.
- Checking the health of the devices: RL agents are designed to work in an environment in which most vehicles were driven by humans, which requires strong policies that adapt to unexpected behavior. We check this by driving RL vehicles on the road under careful human supervision, and making changes to control based on comments.

Each car is connected from 100 cars to Raspberry PI, where the RL console (a small nervous mesh) is deployed.

The RL control unit controls the ACC on board, and its speed and distance are determined.
Once checked, RL controllers were deployed on 100 cars and drove on I-24 during the morning peak hour. The traffic surrounding the experiment was not, ensuring the behavior of the driver is not biased. The data was collected during the experiment from dozens of upper cameras located along the highway, which led to the extraction of millions of individual vehicle tracks through the computer vision pipeline. The metrics affiliated with these tracks indicate the direction of low fuel consumption around AVS, as expected from the results of the simulation and the spread of the previous smaller verification. For example, we can note that the closest people who lead behind our AVS, the more it seems that the fuel they consume on average (which is calculated using the caliber energy model):

The average fuel consumption as a function of the distance behind the closer AV, which is controlled by RL in the traffic traffic. With the height of human drivers behind AVS, the average fuel consumption increases.
Another way to measure the effect is to measure the contrast of speeds and acceleration: the lower the contrast, the lower the waves, the higher what we notice from the field test data. In general, although obtaining accurate measurements of a large amount of camera data is complex, we notice a trend ranging between 15 and 20 % of energy saving around our controlled cars.
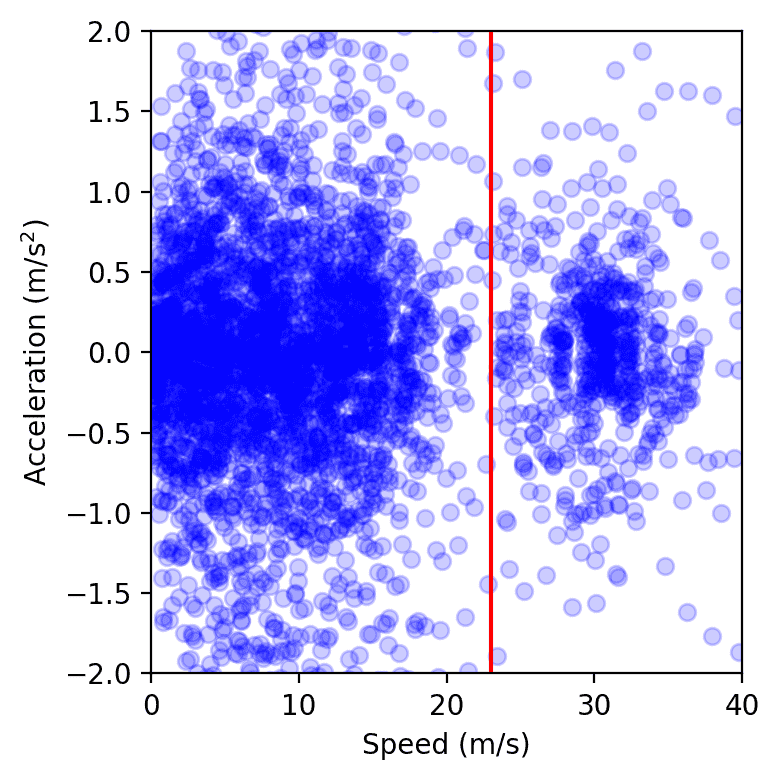
Data points from all vehicles on the highway during one day of the experiment, drawn in the speed of speed acceleration. To the left of the red line, the group represents crowding, while the group on the right corresponds to the free flow. We note that the congestion group is smaller when AVS is present, as it was measured by calculating a soft, convex envelope area or by installing a galaxy nucleus.
Final ideas
The field operational test was 100 cars, not central, with no cooperation or explicit communication between AVS, reflecting the spread of the current self -ruling, and made us one step more than the most smooth and most efficient energy roads. However, there are still tremendous potential for improvement. The expansion of the simulation to be faster and more accurate with better models for controlling a person is very important to bridge the simulation gap to reality. Avs with additional traffic data, whether through advanced sensors or central planning, can improve the performance of control units. For example, although the RL Multi-Agent is promising to improve cooperative control strategies, it remains an open question how empowerment of frank communication between AVS networks on 5G can improve stability and relieve stops and application. Decally, our control units are smoothly integrating with the existing voltage control systems, which makes the field publishing widely possible. The higher the number of vehicles equipped with smart control in the spread of traffic, the greater the number of waves that we will see on our roads, which means less contaminated and fuel for all!
Many contributors to make megavandertest happen! The full menu is available on the circuit project page, along with more details about the project.
Read more: [paper]
2025-03-25 09:00:00



