
A Code Implementation of a Real‑Time In‑Memory Sensor Alert Pipeline in Google Colab with FastStream, RabbitMQ, TestRabbitBroker, Pydantic
In this notebook, we show how to create a “sensor sensor” pipeline in the entire Google Colab using Faststream, high -performance high -performance, broadcasting, and integrating with rabitmQ. By taking advantage of Faststream.rabbit’s rabitbroker and Testrabbitbroker, we simulate the message broker without the need for an external infrastructure. We organize four distinguished stages: swallowing and verifying health, normalization, monitoring and alerting, and archiving, each of which is known as Pydantic models (rawsensordata, normalizeddata, alertdata) to ensure data quality and type of type. Under the hood, the Python company charges the flow of unsafe messages, while Nest_asyncio provides the interrelated events in the colum. We also use the standard registration unit for the implementation of tracked pipelines and pandas to examine the final results, making it easy to imagine the archived alerts in the data system.
!pip install -q faststream[rabbit] nest_asyncioWe install Faststream with its RabbitmQ integration, providing the basic flow processing framework and mediator connectors, as well as the Nest_asyncio package, which provides interrelated events in environments such as colum. All this is achieved while maintaining the minimum output with a -q mark.
import nest_asyncio, asyncio, logging
nest_asyncio.apply()
We import Nest_asyncio and ASYNCIO units and cut the registration, then we apply Nest_asyncio.Apply () to correct the Python event episode so that you can run the simultaneous tasks involved in environments such as colum or the JuPYTER notebooks without errors. The registration import is prepared to connect your pipeline with detailed operating time records.
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
logger = logging.getLogger("sensor_pipeline")We create Python messages integrated into the recording of messages at the level of information (and above) prior to the timeline and severity, then create a dedicated registrar called “Sensor_Pipeine” to remove organized records within the broadcast pipeline.
from faststream import FastStream
from faststream.rabbit import RabbitBroker, TestRabbitBroker
from pydantic import BaseModel, Field, validator
import pandas as pd
from typing import ListWe bring the FastTream category for FastReam along with RabbitmQ (Bubitbroker connectors for real brokers and Testrabbitbroker test for testing in memory), Pydantants Basemode, Field, inspired to verify educational data, and pandas to inspect the tabular results, and the type of list Python for Inhoting in –
broker = RabbitBroker("amqp://guest:guest@localhost:5672/")
app = FastStream(broker)
We facilitate the creation of the RabbitmQ server (local) using the URL AMQP address, then create the Faststream application connected to this medium, and prepare the backbone of the messages for the pipeline stages.
class RawSensorData(BaseModel):
sensor_id: str = Field(..., examples=["sensor_1"])
reading_celsius: float = Field(..., ge=-50, le=150, examples=[23.5])
@validator("sensor_id")
def must_start_with_sensor(cls, v):
if not v.startswith("sensor_"):
raise ValueError("sensor_id must start with 'sensor_'")
return v
class NormalizedData(BaseModel):
sensor_id: str
reading_kelvin: float
class AlertData(BaseModel):
sensor_id: str
reading_kelvin: float
alert: boolPydantic models define this scheme for each stage: Rawsensordata imposes inputs (for example, reading and sensor’s calmness), DormySeddata Celsius converts into Kelvin, and Elertdata envelops the final alert load (including logical science), ensuring the flow of type data throughout the line.
archive: List[AlertData] = []
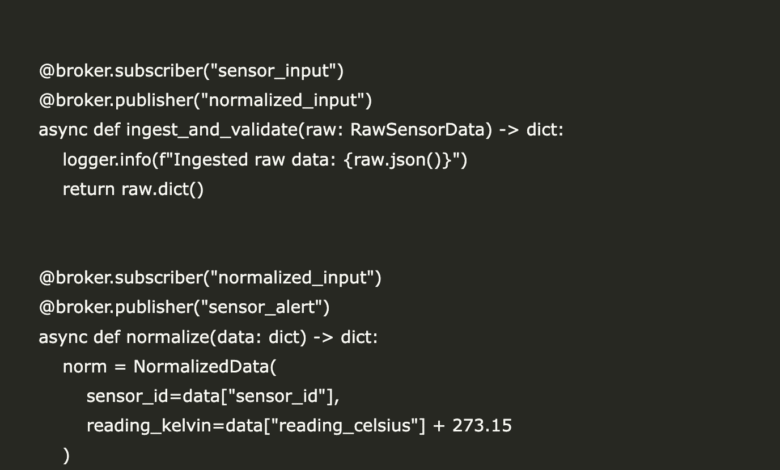
@broker.subscriber("sensor_input")
@broker.publisher("normalized_input")
async def ingest_and_validate(raw: RawSensorData) -> dict:
logger.info(f"Ingested raw data: {raw.json()}")
return raw.dict()
@broker.subscriber("normalized_input")
@broker.publisher("sensor_alert")
async def normalize(data: dict) -> dict:
norm = NormalizedData(
sensor_id=data["sensor_id"],
reading_kelvin=data["reading_celsius"] + 273.15
)
logger.info(f"Normalized to Kelvin: {norm.json()}")
return norm.dict()
ALERT_THRESHOLD_K = 323.15
@broker.subscriber("sensor_alert")
@broker.publisher("archive_topic")
async def monitor(data: dict) -> dict:
alert_flag = data["reading_kelvin"] > ALERT_THRESHOLD_K
alert = AlertData(
sensor_id=data["sensor_id"],
reading_kelvin=data["reading_kelvin"],
alert=alert_flag
)
logger.info(f"Monitor result: {alert.json()}")
return alert.dict()
@broker.subscriber("archive_topic")
async def archive_data(payload: dict):
rec = AlertData(**payload)
archive.append(rec)
logger.info(f"Archived: {rec.json()}")The memory archive menu combines all the final alerts, while four simultaneous, wireless functions via @Broker.subscripr/ @Broker.publisher, constitute the pipeline stages. These functions that you consume and verify the authenticity of the raw sensor inputs, convert Celsius into kevin, check the alert threshold, and finally archive every Alertdata record, which emanates from records in each step to track full tracking.
async def main():
readings = [
{"sensor_id": "sensor_1", "reading_celsius": 45.2},
{"sensor_id": "sensor_2", "reading_celsius": 75.1},
{"sensor_id": "sensor_3", "reading_celsius": 50.0},
]
async with TestRabbitBroker(broker) as tb:
for r in readings:
await tb.publish(r, "sensor_input")
await asyncio.sleep(0.1)
df = pd.DataFrame([a.dict() for a in archive])
print("\nFinal Archived Alerts:")
display(df)
asyncio.run(main())
Finally, the main Coroutine publishes a set of sample sensors readings in Bassrabbitbroker in memory, and it stops shortly to allow each stage of the pipeline to play, then collects Alertdata records from the archive to Dataframe Pandas for easy display and checking a comprehensive alert flow. In the end, asyncio.run (main ()) begins the complete ASYNC trial in Colab.
In conclusion, this tutorial shows how speed, as well as RabbitmQ abstracts and memory test via Testrabbitbroker, accelerate the development of data pipelines in actual time without spreading external intermediaries. By verifying the health of the Atlantic handling plan, compatibility with ASYNCIO, and Pandas, which allows fast data analysis, this style provides a strong basis for sensor monitoring, ETL tasks, or event -based workflow tasks. You can smoothly move from this memory demonstration to production by switching URL for live mediation (RabbitmQ, Kafka, Nats, or Redis) and Faststream operation under UVCORN or your favorite Asgi server, and cancel the developmental, developed, developed flow processing process, in any Beton environment.
Here is Clap notebook. Also, do not forget to follow us twitter And join us Telegram channel and LinkedIn GrOup. Don’t forget to join 90k+ ml subreddit.
🔥 [Register Now] The virtual Minicon Conference on Agency AI: Free Registration + attendance Certificate + 4 hours short (May 21, 9 am- Pacific time)
SANA Hassan, consultant coach at Marktechpost and a double -class student in Iit Madras, is excited to apply technology and AI to face challenges in the real world. With great interest in solving practical problems, it brings a new perspective to the intersection of artificial intelligence and real life solutions.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-04-22 00:40:00



