
AI Guardrails and Trustworthy LLM Evaluation: Building Responsible AI Systems
AI-guardrails">Introduction: The increasing need for AI studies
As LLMS models grow in the scope of power and spread, the risk of unintended behavior, hallucinations, and harmful outputs increases. The recent increase in the integration of artificial intelligence in the real world through the healthcare, financing, education and defense sectors is the demand for strong safety mechanisms. Amnesty International – technical and procedural controls to ensure compatibility with human values and policies – as a critical field of focus.
the Stanford Index 2025 Amnesty International I mentioned a 56.4 % jump In incidents related to the prosecution in 2024-233 cases in total-the urgency to obtain strong handrails. At the same time, and Institute for the Future of Life The main artificial intelligence companies have been ranked poorly on AGI safety planning, with no company received a higher classification than C+.
What is the handrail of artificial intelligence?
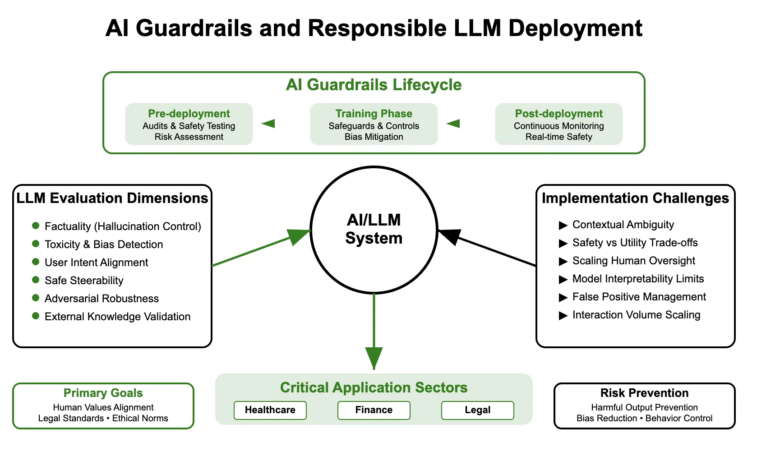
Drill from artificial intelligence indicates safety control elements at the level of the system included in the artificial intelligence pipeline. These are not just output filters, but they include architectural decisions, counter -feeding mechanisms, policy restrictions and actual time monitoring. It can be classified into:
- Pre -publications: Data set, red model, and policy policy. For example, AEGIS 2.0 34,248 includes reactions explained across 21 safety.
- Training at the time of training: Learning reinforcement with human comments (RLHF), differential privacy, layers of mitigation of bias. It is worth noting that overlapping data sets can collapse these handrails and enable prison.
- Green after publishing: Moderation output, continuous evaluation, recovery validity, reserve guidance. Unit 42 June 2025 unveiled high false positives in moderate tools.
Amnesty International is worthy of trust: principles and columns
Amnesty International is worthy of confidence not a single technique but it is a compound of the main principles:
- Durabness: The model should be reliable under the distribution or aggressive inputs.
- Transparency: The path of logic should be an explanation of users and auditors.
- Accountability: There should be mechanisms to track typical actions and failure.
- Equity: Outputs should not be destroyed or social biases.
- Preserving privacy: Techniques such as federal learning and differential privacy is very important.
The legislative focus on the governance of artificial intelligence increased: in 2024 alone, US agencies have issued 59 regulations related to Acting in 75 countries. UNESCO also created global moral guidelines.
LLM rating: beyond accuracy
The LLMS evaluation extends beyond traditional accuracy standards. The main dimensions include:
- realism: Is the hallucinogen?
- Toxicity and bias: Are the outputs comprehensive and harmless?
- coordination: Does the model follow the instructions safely?
- Guidance: Can it be directed based on the user’s intention?
- Durabness: To what extent does aggressive claims?
Evaluation techniques
- Mechanical standards: Bleu, rouge, confusion but is not enough on its own.
- Human reviews in the episode: Experts, expert comments for safety, tone and compliance with politics.
- Divide test: Using red capture techniques for stress test effectiveness.
- The evaluation of retrieval: Answers to verify facts against external knowledge rules.
Multinencing tools such as HELM (the comprehensive evaluation of language models) and collecticeval are adopted.
Teaching handrails in llms
The integration of handrails from artificial intelligence should start in the design stage. The organized approach includes:
- Detection of intent: It classifies unsafe inquiries.
- Guidance layer: Restore to the generation -centered generation (RAG) or human review systems.
- Post -therapy filters: Works are used to detect harmful content before the final output.
- Comments episodes: It includes user notes and constant precise refinement mechanisms.
Open source parties such as AI and RAIL handrails provide standard applications to try these ingredients.
Challenges in the safety and evaluation of LLM
Despite progress, the main obstacles remain:
- Evaluation ambiguity: The identification of damage or fairness vary through contexts.
- The ability to adapt to control: Many restrictions reduce interest.
- Human reactions scaling: Quality guarantee for billions of generations is not trivial.
- Moderate model: LLMS -based llms remains largely black despite the interpretation efforts.
Recent studies indicate that excessive residence leads to high false positives or unusable outputs (source).
Conclusion: to spread responsible artificial intelligence
Harmers are not a final but advanced safety network. Artificial intelligence must be dealt with trustworthy as a challenge at the level of systems, integrate architectural durability, continuous evaluation, and moral insight. With LLMS acquisition of autonomy and influence, the proactive LLM evaluation strategies will be an ethical necessity and technical necessity.
Organizations that build or spread artificial intelligence must deal with safety and merit with confidence, not as Africa, but as central design goals. Only then artificial intelligence can develop as a reliable partner instead of an unpredictable danger.
Common questions on handrails of artificial intelligence and the deployment of LLM responsible
1. What exactly are degrees of artificial intelligence, and why are it important?
Handrails of artificial intelligence are comprehensive safety measures involved during the life development cycle of artificial intelligence-including pre-publication audits, training, and post-publication control-which help prevent harmful outputs, biases and unintended behaviors. It is decisive to ensure that artificial intelligence systems are in line with human values, legal standards and moral standards, especially since artificial intelligence is increasingly used in sensitive sectors such as health care and financing.
2. How are the LLMS models evaluated after a fair accuracy?
LLMS is evaluated in multiple dimensions such as realism (the number of times the hallucinations), the toxicity and the bias in the outputs, the user’s intention, the guidance (the ability to guidance safely), and the durability against aggressive claims. This evaluation combines automatic scales, human reviews, aggressive testing and breaking facts against external knowledge rules to ensure a more secure and reliable AI’s behavior.
3. What are the biggest challenges in implementing effective artificial degrees?
The main challenges include ambiguity in defining harmful or biased behavior through various contexts, buding safety control elements with the benefit of the model, expanding the scope of human supervision on the enormous reaction volumes, and the inherent obfuscation of deep learning models that limit the ability to clarify them. Excessive pursuit handrails can also lead to high false positives, frustration of users and reduce the benefit of artificial intelligence.

Michal Susttter is a data science specialist with a master’s degree in Data Science from the University of Badova. With a solid foundation in statistical analysis, automatic learning, and data engineering, Michal is superior to converting complex data groups into implementable visions.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-23 09:07:00



