
Meet LocAgent: Graph-Based AI Agents Transforming Code Localization for Scalable Software Maintenance
Software maintenance is an integral part of the software development cycle, as developers repeatedly reconsider the current code bases to fix errors, implement new features and improve performance. An important task at this stage is to localize the code, which spoils specific locations at the code base that must be modified. This process has gained importance while increasing the scope of software and complexity projects. The increasing dependence on automation and tools that depend on AI led to the inclusion of large language models (LLMS) in supporting tasks such as detection of errors, searching for code, and suggestion. However, although LLMS progresses in linguistic tasks, enabling these models to understand the signs and structures of the complex code still represents a technical challenge that researchers seek to overcome.
Talking about problems, one of the most stable problems in software maintenance is to identify the relevant parts of the database that needs changes based on the problems that the user or features have been informed. Often, I remember describing the symptoms in the natural language, but not the actual radical cause of the code. This separation makes it difficult for developers and automated tools to connect descriptions with micro -software elements that need updates. Moreover, traditional methods are combined with complex code dependencies, especially when the relevant code extends multiple files or requires hierarchical thinking. The localization of the weak code contributes to solving ineffective errors, incomplete spots, and longer development courses.
Previous methods for settling software instructions often depend on dense retrieval models or agents based on the agent. The heavy retrieval requires an entire base of the blade in a search space, which is difficult to preserve and update to large warehouses. These systems often cause badly when the release descriptions lack direct signals to the relevant code. On the other hand, some modern methods use the agent based on a human -like exploration of the code base. However, it often depends on passing the guide and lacks the understanding of deeper semantic ties such as inheritance or function. This limits their ability to deal with complex relationships between the elements of the code is explicitly related.
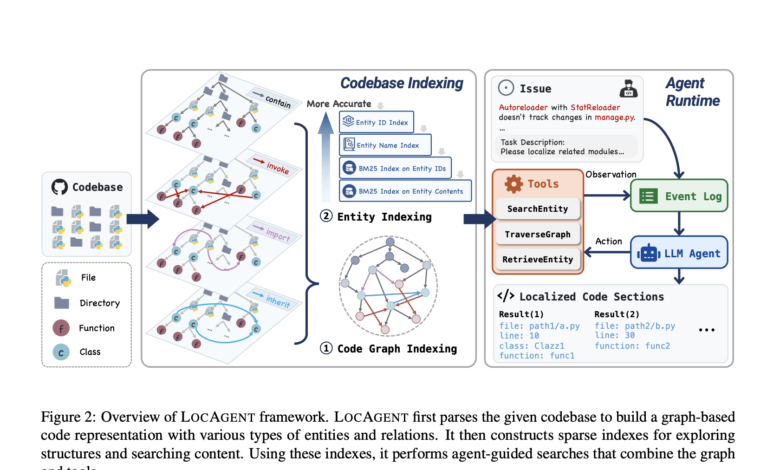
A team of researchers from Yale University, the University of Southern California, the University of Stanford, and all the hands Ai Locagent, developed a framework for the graph to transfer the localization of code. Instead of relying on lexical matching or fixed inclusion, Locagent converts the entire code bases into heterogeneous graphic graphics directed. These graphs include a contract for connotations, files, groups, functions and edges to capture relationships such as summoning jobs, file imports, and category inheritance. This structure allows the agent to think about multiple levels of the code. Then the system applies tools such as Searchchentity, Travers The use of sporadic hierarchical indexing ensures rapid access to entities, and the design of the graph supports a multi -law, which is necessary to find communications across the distant parts of the code base.
Locagent makes indexing within seconds and supports actual time, making it practical for developers and organizations. The researchers installed two open source models, QWEN2.5-7B, and QWEN2.5-32B, on a set of successful settlement paths. These models have impressive standards. For example, on the SWE-Bench Data collection, Locagent has made a 92.7 % accuracy of the file using QWEN2.5-32B, compared to 86.13 % with CLAUDE-3.5 and lower degrees than other models. On the newly presented LOC-Bused data collection, which contains 660 examples via error reports (282), features of features (203), safety problems (31), performance problems (144), Locagent showed competitive results again, and achieved 84.59 % Acc@5 and 87.06 % Acc@10 at the file level. Even the smaller QWEN2.5B model performed near the high-cost models while it only costs $ 0.05 per example, on the blatant contrast with a cost of $ 0.66 for Clauds-3.5.
The basic mechanism depends on the detailed indexing process based on the graph. Each knot, whether it represents a category or function, is determined uniquely by a fully qualified name and indexing using BM25 to search for elastic keywords. The model enables agents to simulate thinking chain that begins to extract keywords related to problems, and continues through the traveler of the graph, and concludes with code recovers for a specific contract. These procedures are recorded using an approach to confidence based on the consistency of prediction of multiple repetitions. It is worth noting that when researchers disable tools such as Traversegraph or Searchity, the performance decreased by up to 18 %, highlighting their importance. Moreover, multiple hop thought was very important; The jumps’ repair led to a decrease in the accuracy of the function level from 71.53 % to 66.79 %.
When applied to clinic tasks such as the accuracy of the GitHub problem, LOCAGENT increased the rate of passing the version (Pass@10) from 33.58 % in Learning Listerless systems to 37.59 % with the QWEN2.5-32B form. The framework and open source model make a convincing solution for institutions looking for internal alternatives for the LLMS commercial. LOC-Bench, with its broader representation of maintenance tasks, ensures a fair evaluation without pollution from pre-training data.
Some of the main meals of search on Locagent include the following:
- LOCAGENT converts the Bass code into heterogeneous graphic graphics of the multi -level logic.
- It has achieved up to 92.7 % accuracy at the file level on Swe-Bench-Lite with QWEN2.5-32B.
- Reducing the cost of resettlement of the code by about 86 % compared to royal models. LOC-PINCED data collection was presented with 660 examples: 282 Bugs, 203 features, 31 Security, 144 Performance.
- Seized models (QWEN2.5-7B, QWEN2.5-32B) similar to Clauds-3.5.
- Tools such as Traversegraph and Searchity have proven necessary, with decreased accuracy when disabled.
- Benefit in the real world has shown by improving the rates of solving the GitHub issue.
- It provides a cost -effective and effective alternative to LLM Special LLM solutions.
Payment Paper and GitHub page. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 85k+ ml subreddit.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically intact and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
2025-03-23 22:37:00



