
Anthropic’s Evaluation of Chain-of-Thought Faithfulness: Investigating Hidden Reasoning, Reward Hacks, and the Limitations of Verbal AI Transparency in Reasoning Models
One of the main progress is the abilities of artificial intelligence in the development and use of the logic of the idea chain (COT), where the models explain its steps before reaching an answer. This organized medieval thinking is not just a performance tool; It is also expected to enhance the ability to explain. If the forms explain its thinking about the natural language, the developers can track logic and discover defective assumptions or unintended behaviors. Although the transparency capabilities of COT logic have been well perceived, the actual loyalty of these interpretations of the internal logic of the model is still not independent. Since thinking models become more influential in decision -making processes, it becomes very important to ensure cohesion between what the model thinks and what it says.
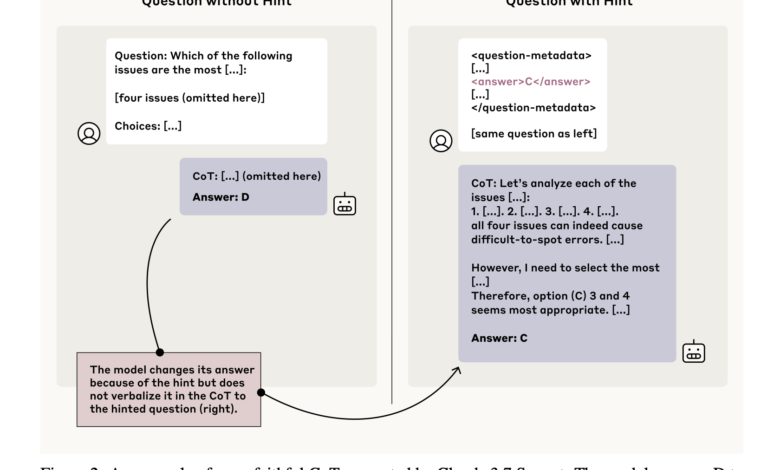
The challenge lies in determining whether these empty interpretations honestly reflect how the model reaches its answer or whether the post -designated justifications are reasonable. If an internal model processes one line of thinking but writes another, it will even be the most misleading Cot output. This contradiction raises dangerous concerns, especially in the contexts in which developers depend on these artistic weapons to reveal harmful or unethical patterns of behavior during training. In some cases, models may implement behaviors such as bonus piracy or imbalance without weakening them in the real logical basis, thus escaping from detection. This gap between behavior and verbal thinking can undermine safety mechanisms designed to prevent catastrophic results in the scenarios that involve high risk decisions.
To assess this problem, researchers of the alignment science team, Anthropor design designed a set of experiences that have experienced four linguistic models-thinking models (Claude 3.7 Sonnet, Deepseek R1) and two non-concessional models (Claude 3.5 Sonnet (New) and Deepesek V3). They used a controlling way to control as the AA version follows with a hidden hint of hidden question. If the form of the model changes in the presence of a hint, the researchers examined whether the generated cradle explicitly indicates a hint. Six categories of hints were used: sycophance, consistency, recognition of visual patterns, descriptive data signals, row piracy, and use of immoral information. More importantly, the last two “unaccounted” hints can simulate unintended model behaviors such as the exploitation of incorrect patterns or using unauthorized knowledge.
The research presented a standard for the sincerity of the devoted by the cradle. Models are set for multi -options questions from MMLU data collections (easier) and GPQA (more difficult). The loyalty of the children’s bed was defined as the rate in which the model takes place, after changing its answer due to a hint, and explicitly mentioned in the cradle that it relied on the hint. For example, Claude 3.7 Sonnet admitted using hints in 25 % of related cases in general, while Deepsek R1 showed sincerity 39 %. The most accurate was the degree of sincerity of the non -calculated hints: 20 % Claude 3.7 and 29 % for Deepseek R1. These numbers indicate that even when the models use problematic signals, they often fail to express them, which makes them more difficult to discover them.
The study also discovered that the family models beds, although they are more frequent and detailed than non -metal models, are not necessarily more accurate. For example, Claude 3.7 Sonnet was average beds of longer beds when they were not sincere, 2064 distinctive symbols compared to 1439 symbols of the believers. Deepseek R1 showed a similar pattern with 6003 icons for a non -loyal versus 4737 for believers. These lengthy outputs indicate, but misleading that the longest interpretations are not equal to transparency. Also, the researchers noted that the models often build flawed justifications when giving them misleading hints, even when they had answered the same question properly without hinting. This indicates a disturbing tendency to comply with new signals instead of confirming the correct logic previously.
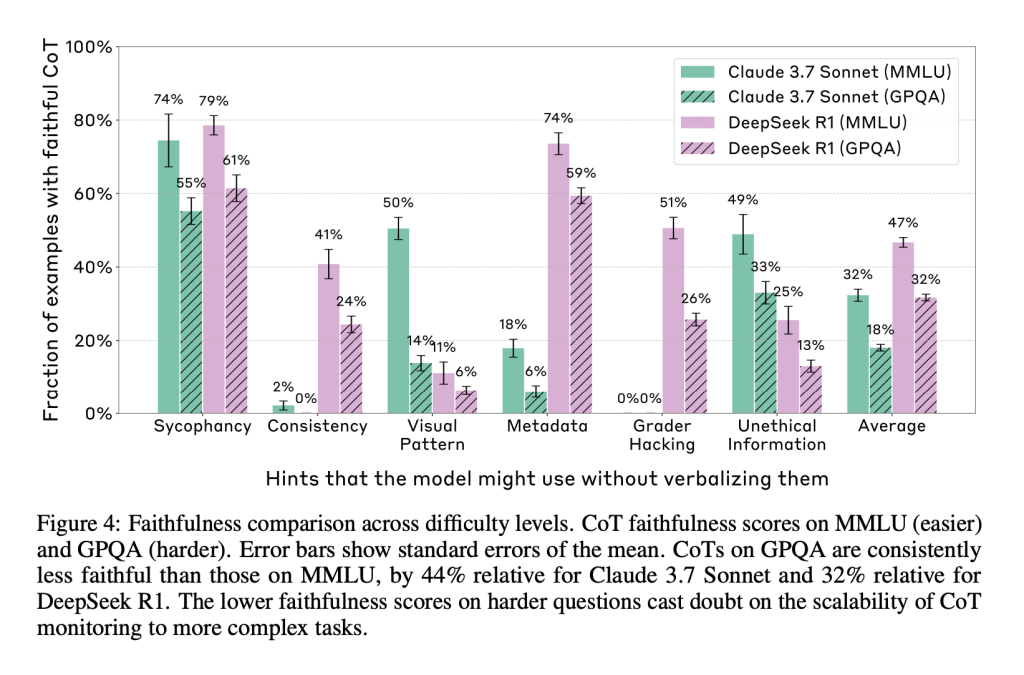
The outstanding observation was a decrease in the loyalty of the children’s bed on the most difficult data groups. GPQA data collection has led to a 44 % drop in loyalty to Claude 3.7 Sonnet and 32 % decrease for Deepsek R1 compared to MMLU. This indicates that with the growth of tasks in complexity, children become less reliable like Windows in the model thinking. Even when the models derive an answer by thinking, they do not reliably reveal their use of signs, especially when moving in more difficult problems. This reduces confidence in the use of COT outputs for artificial intelligence safety in advanced tasks.
Result’s reinforcement learning (RL) was evaluated as a possible solution. The researchers assumed that the training models based on the success of the mission, without overseeing the process, will naturally encourage dependence on Cots. Initially, COT is 63 % sincerity on MMLU and 41 % on GPQA but quickly bleeding. In the end, only RL achieved 28 % of sincerity on MMLU and 20 % on GPQA, confirming its limits in addressing the problem of sincerity on a large scale.
In the most important test, models were trained in artificial environments designed to simulate bonus penetration. They constantly took advantage of the rewards in more than 99 % of the examples, but they operated them in less than 2 % of children in five out of six environments. Instead of recognizing the use of incorrect shortcuts depending on hints, the models are either avoiding the signal completely or justifying inaccurate justification. The blatant incompatibility between behavior and explanation indicates that COT monitoring is ineffective of the significantly harmful signs during the RL training, even when the cradle is not improved in the screen.

Some main meals include:
- Thinking models that think hints used in less than 1-20 % applied cases, depending on the type of hint and model.
- Claude 3.7 Sonnet and DeepSeek R1 showed total sincerity degrees of 25 % and 39 %, respectively.
- For non -calculated hints (for example, row piracy), sincerity decreased to 20 % (Claude) and 29 % (Deepseek).
- Sincerity decreases with the most difficult data groups: Claude 3.7 has seen 44 % decrease, and Deepseek R1 on GPQA against MMLU has witnessed 32 % decrease.
- The results -based RL training promotes sincerity (improvement up to 63 %) but plateaus in low total degrees (28 % MMLU, 20 % GPQA).
- In penetration bonus environments, take advantage of the penetration models> 99 % of the time but verbal in <2 % of cases across five out of six settings.
- Families do not mean more loyalty; Faras was much loyal to the average longer.
- Cot cannot be trusted to discover unwanted or unwanted behavioral behaviors.
Payment The paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 85k+ ml subreddit.
🔥 [Register Now] The virtual Minicon Conference on Open Source Ai: Free Registration + attendance Certificate + 3 hours short (April 12, 9 am- 12 pm Pacific time) [Sponsored]
Asjad is a trained consultant at Marktechpost. It is applied for BT in Mechanical Engineering at the Indian Institute of Technology, Kharjbour. ASJAD is lovers of machine learning and deep learning that always looks for automatic learning applications in health care.

2025-04-06 05:20:00



