
Apple Researchers Reveal Structural Failures in Large Reasoning Models Using Puzzle-Based Evaluation
Artificial intelligence has undergone a significant transition from basic language models to advanced models that focus on thinking tasks. These latest systems, known as LRMS, represent a group of tools designed to simulate human -like thinking by producing medieval thinking steps before reaching conclusions. The focus has moved from the generation of accurate outputs to understanding the process that leads to these answers. This shift raised questions about how these models are managed by class complex tasks and whether they really have thinking capabilities or they simply benefit from training patterns to guess the results.
Reorting the evaluation: exceeding the accuracy of the final answer
A frequent problem in assessing thinking in the machine is that traditional criteria often evaluate the final answer without examining the steps that are accessed to it. The accuracy of the final answer alone does not reveal the quality of internal thinking, and many criteria are contaminated with the data that may be seen during the training. This creates a misleading image of the real model capabilities. To explore actual thinking, researchers need environments where the problem can be controlled accurately and intermediate steps can be analyzed. Without such settings, it is difficult to determine whether these models can generalize solutions or just save patterns.
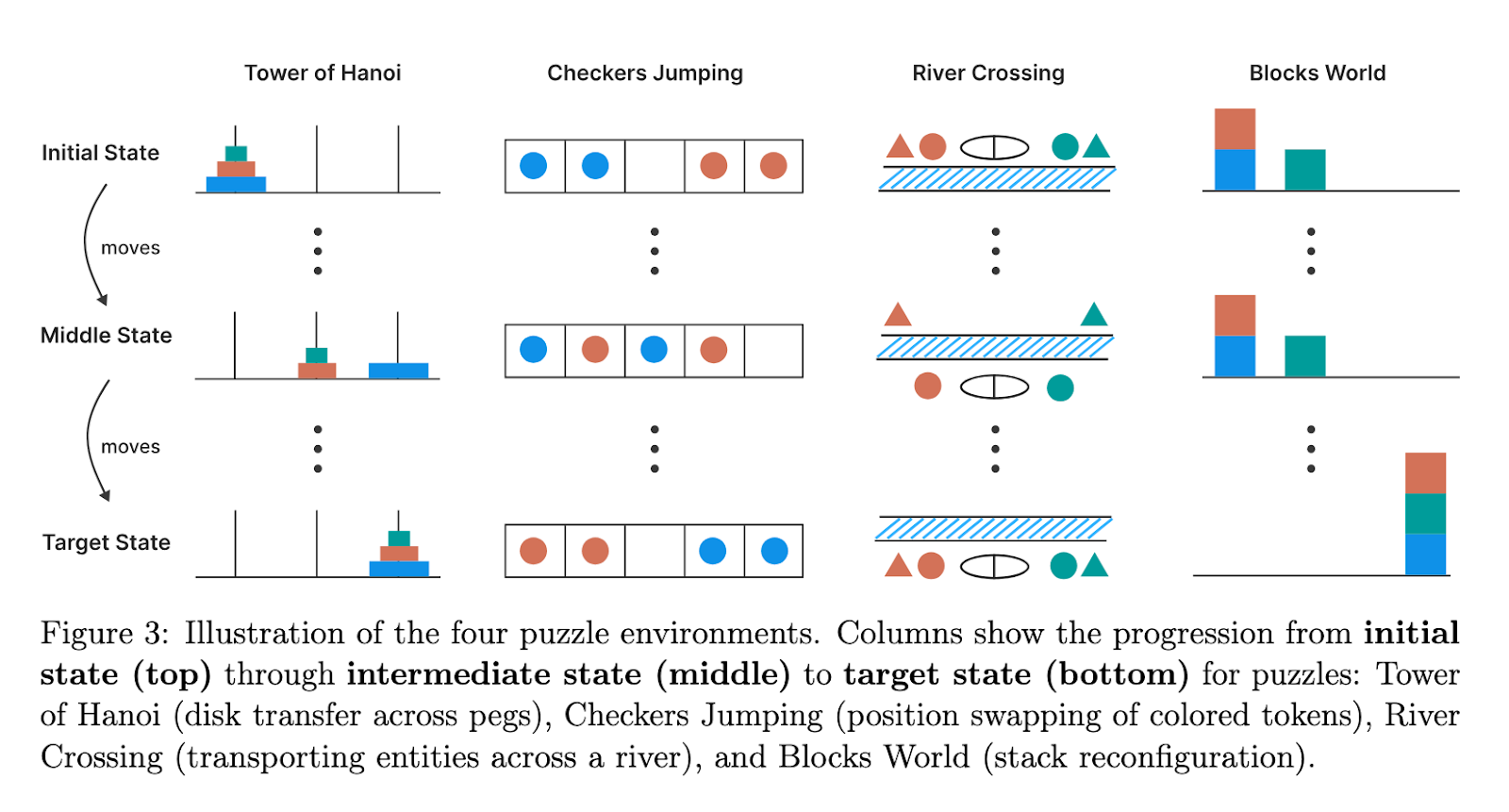
To evaluate thinking more reliably, the Apple research team designed a setting using four of the Tower of Hanoi, Crossing River, jumping, and world blocks. These puzzles allow accurate manipulation of complexity by changing elements such as the number of tablets, code or agents concerned. Each task requires different thinking capabilities, such as registration satisfaction and serial planning. More importantly, these environments are free of typical data pollution, which allows a comprehensive examination of both the result and the thinking steps between them. This method guarantees a detailed investigation on how models are disposed of through various tasks requirements.
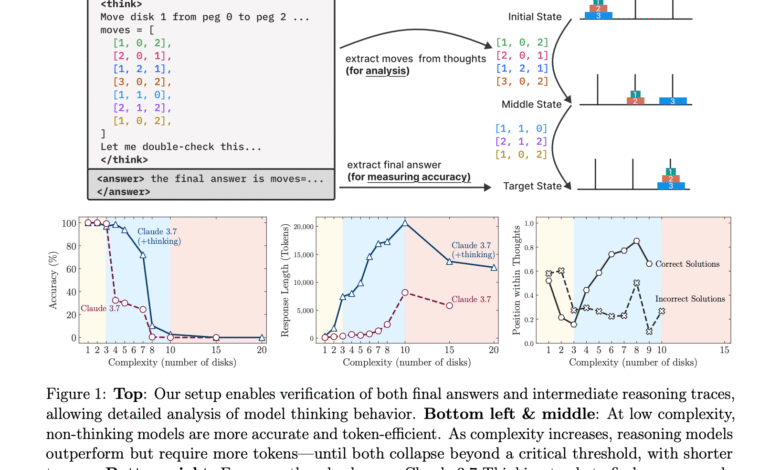
The research entered a comparative study using two groups of models: Claude 3.7 Sonnet and Deepseek-R1, along with “thinking” variables and standard counterparts in LLM. These models are tested through mystery under symbolic budgets similar to measuring both accuracy and efficiency. This helped to detect performance shifts through low, medium and highly complex tasks. One of the most noticeable notes was the formation of three performance areas. In simple tasks, models other than thinking surpassed logical variables. For medium complexity, thinking models have gained edge, while both types collapsed completely as the complexity reached its climax.
Comparison visions: Thinking against non -demonstration models under pressure
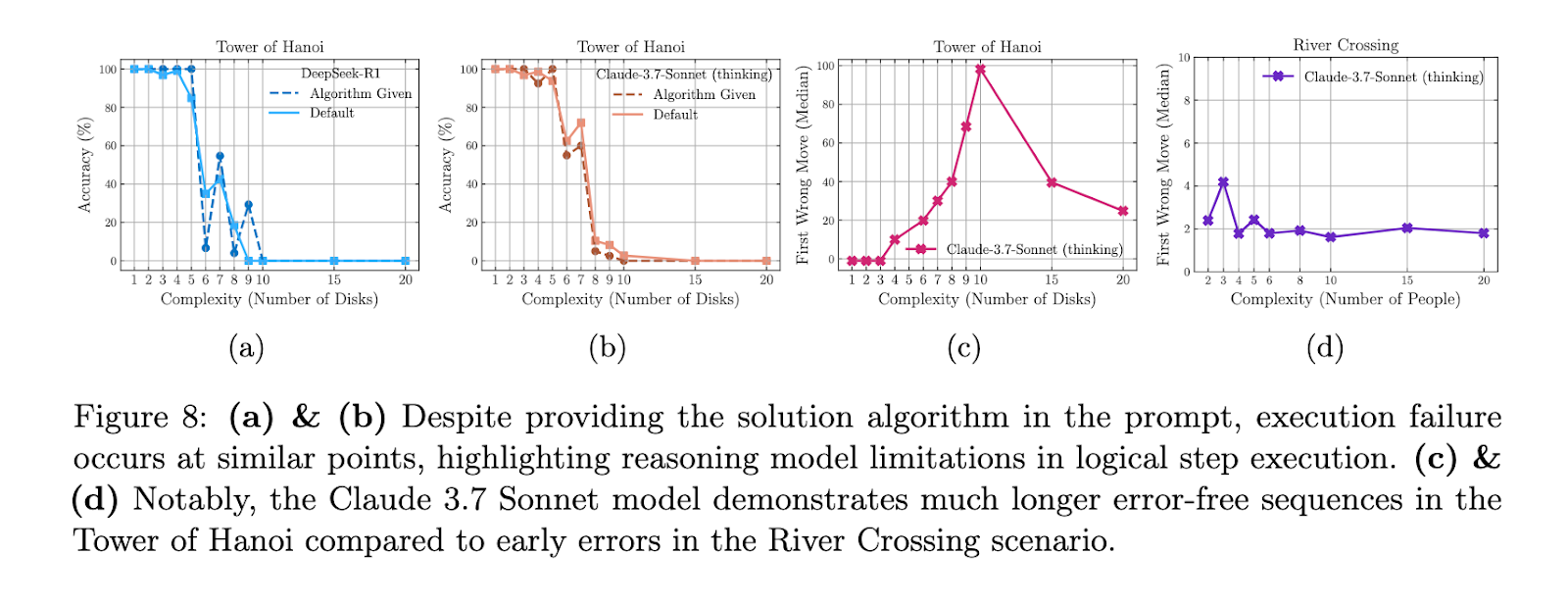
An in -depth analysis revealed that the thinking voltage increased with the difficulty of the task to a certain point, but then it decreased despite the availability of resources. For example, in the Hanoi Tower, the Claude 3.7 Sonnet (Thinking) is highly accurate until the complexity reached a certain extent, after which the performance decreased to scratch. Even when these models were provided with explicit solution algorithms, they failed to implement steps that exceed the levels of the selected complexity. In one cases, Claude 3.7 can properly 100 -step management for Hanoi, but he could not complete the simple river transit tasks that require only 11 movements when $ N = $ 3. This contradiction revealed serious restrictions in symbolic manipulation and careful account.
The performance collapse also also how LRMS deals with the internal thinking process. The models are frequently involved in “thinking about thinking”, generating correct intermediate solutions early in the process, but they continue to explore incorrect paths. This led to the inefficiency of the use of symbols. At medium complexity levels, models began to find the correct answers later in thinking chains. However, at high levels of complexity, they failed to produce accurate solutions. The quantitative analysis confirmed that the accuracy of the solution decreased to nearly zero with an increase in the complexity of the problem, and the number of symbols designated for thinking began to decline unexpectedly.
The limits of scaling and the collapse of logic
This research provides a realistic evaluation of how current learning resources management systems (LRMS) work. Research from Apple shows that despite some progress, thinking models today are still far from achieving generalized thinking. The work determines how performance standards fail, as it collapses, and why excessive dependence on standard accuracy fails to capture deeper thinking behavior. The controlled puzzles have proven to be a powerful tool to detect hidden weaknesses in these systems and emphasize the need for more powerful designs in the future.
verify paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 99k+ ml subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-06-13 04:32:00



