
Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models

The artificial nervous networks (AnNS) revolutionized the computer vision with great performance, but its nature “Black Box” creates great challenges in areas that require transparency, accountability and organizational compliance. Attracting these systems impedes their adoption in critical applications, where understanding of decision -making processes is necessary. Scientists are curious to understand the internal mechanisms of these models and want to use these ideas for effective correction, improve models, and explore potential similarities with neuroscience. These factors motivated the rapid development of interpretative artificial intelligence (XAI) as a dedicated field. It focuses on the interpretation of AnNS and bridge the gap between the intelligence of the machine and human understanding.
Concepts -based methods are strong business frameworks between XAI approaches to detect visual concepts clear in the complex activation patterns of AnNS. Modern research distinguishes the concept extract as problems in learning the dictionary, as activations plan a more interpretation “concept space”. Techniques such as non-negative matrix factors (NMF) and K-Mean are used to accurately rebuild the original activation, while the SAES automatic coding devices (SAES) recently gained strong alternatives. Saes achieves an impressive balance between spacing and the quality of reconstruction, but it suffers from instability. SAES training on the same data can result in different concept dictionaries, which limits its reliability and interpretation of the glorious analysis.
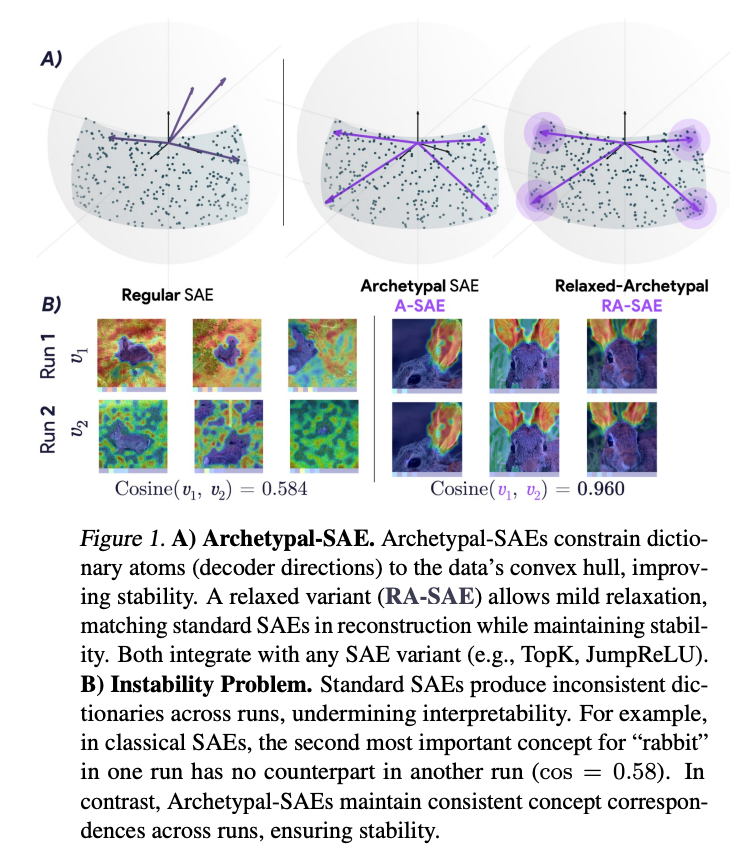
Researchers from Harvard University, York University, CNRS and Google DeepMind suggested two new types of sporadic automatic coding devices to address instability issues: Sae (A-SAE) and its comfortable counterpart (Ra-SAE). These methods are based on analyzing the original model to enhance stability and consistency in concept extraction. The A-SAE model restricts each dictionary of residence dictionary within a convex body of training data, which imposes an engineering restriction that improves stability through various exercises. RA-SAE extends this framework more by integrating a small relaxation term, allowing slight deviations of convex body to enhance modeling elasticity while maintaining stability.
Researchers evaluate their approach using five vision models: Dinov2, Siglip, Vit, Convnext, and Resnet50, all obtained from the Timm Library. It builds equivalent dictionaries of five times the feature of the feature (for example, 768 x 5 for Dinov2 and 2048 x 5 for persuasion), providing sufficient ability to represent the concept. Models are undergoing training in the entire Imagenet data collection, as they processing approximately 1.28 million pictures that generate more than 60 million icons for each era for persuasion and more than 250 million symbols of Dinov2, continuing at 50 pm. Moreover, Ra-SAE is based on the Topk Sae structure to maintain a varied varied levels through experiments. The matrix account includes the K-Means assembly for the entire data collection to 32000 Centroids.
The results show significant differences in performance between traditional methods and proposed methods. The classic and standardized dictionary algorithms show a comparable but struggle to restore real obstetric factors in accurately tested data sets. On the other hand, RA-SAE achieves a higher accuracy in recovering the categories of basic objects across all artificial data collections used in the evaluation. In qualitative results, RA-SAE reveals meaningful concepts, including features based on shadow associated with depth thinking, concepts that depend on context such as “barber”, and the capabilities of detecting fine edges in flower petals. Moreover, he learns a more organized discrimination within the Topk-SAES category, separating features such as rabbits, faces and jaws in distinct concepts instead of mixing them.
In conclusion, the researchers provided two types of sporadic automatic coding devices: A-SAE and its comfortable counter-counter. A-SAE lies the dictionary atoms on a convex body of training data and enhances stability while maintaining emoji. Next, RA-SAE effectively balances the quality of reconstruction with a meaningful concept discovery in large-scale vision models. To assess these methods, the team has developed new standards and standards inspired by identity theory, providing a systematic framework for measuring the quality of the dictionary and the dismantling of the concept. Besides your computer’s vision, A-SAE is established as a basis for discovering a more reliable concept over broader ways, including LLMS and other structured data areas.
Payment The paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 80k+ ml subreddit.

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.
2025-03-17 05:47:00



