
Deep Cogito v2 open source models have self-improving intuition
Want more intelligent visions of your inbox? Subscribe to our weekly newsletters to get what is concerned only for institutions AI, data and security leaders. Subscribe now
Deep Cogito, an emerging AI research company, has released its least well-known AI research in San Francisco, which was founded by former Sobuj, today four large new open linguistic models (LLMS) that are trying to do a few: learn how to think more effectively over time-and improved on them alone.
Models, It was released as part of the Cogito’s V2 family, It ranges between 70 billion to 671 billion teachers and is available for artificial intelligence developers and institutions for use in light of a combination of limited and fully open licensing. Includes:
- Cogito V2-70B (dense)
- Cogito v2-109b (Mixed Experts)
- Cogito V2-405B (dense)
- Cogito v2-671B (experts experts)
The Cogito V2 series includes both heavy and Mix of experts (MEE) Models, every occasion to meet different needs. Dense models, such as 70B and 405B variables, are active, all parameters on each pass, which makes them more predictable and easier to publish through a wide range of devices.
It’s perfect for Low applications, adjustment, and environments with limited graphics processing unit. MEE models, such as 109B and 671B versions, use a scattered guidance mechanism to activate a few sub -networks “experts” specialized at one time, allowing a lot The sizes of the largest total models Without relative increases in the cost of an account.
AI Impact series returns to San Francisco – August 5
The next stage of artificial intelligence here – are you ready? Join the leaders from Block, GSK and SAP to take an exclusive look on how to restart independent agents from the Foundation’s workflow tasks-from decisions in an actual time to comprehensive automation.
Ensure your place now – the space is limited: https://bit.ly/3Guupf
This makes it suitable High performance inference tasksResearch in complex thinking, or presentation The accuracy of the border level at the expense of the lower operating time. In Cogito V2, the 671B MEE model works as the best, and benefits from its efficiency and efficiency in directing to match or bypass the leading open models on the standards – with the use of thinking chains much shorter.
It is now available on Hugging Face for download and use by companies and Unloth for local use online, or for those who cannot host typical inferences on their own devices, through APIS) from together AI, Baseten and Runpod.
There is also a “FP8) 67B version, which reduces the volume of numbers used to represent the model parameters from 16 bits to 8 bits, which helps users to run huge models faster, cheaper and more easy-to-make devices-sometimes with justified performance of performance, 95-99 %. However, this It can be slightly degraded from the accuracy of the modelEspecially for tasks that require accurate accuracy (for example, some mathematics or thinking problems).
Every four cOgito V2 models are designed as hybrid thinking systems: they can respond immediately to inquire, or when needed, reflects internally before answering.
It is very important that this reflection is not only the time of operation – it bakes in the training process itself.
These models are trained to absorb their thinking. This means that the same paths that they take to reach answers – mental steps, if it is permissible to speak – are distilled again in the weights of the models.
over time, They learn any important thinking lines already and which no.
The Deep Cogito Blog, “Researchers”, also notice the form of “Meandering Moster” to be able to reach the answer, and instead, develop a stronger intuition for the correct research path for the thinking process. “
And the result, as you claim deep Kogito, is Faster thinking, more efficient and general improvement in performance, Even in the so -called “standard” situation.
Self -intelligence stimulation
While many in the artificial intelligence community face the company now, Deep Cogito is quietly built for more than a year.
The company came out of Stealth in April 2025 with a series of open source models trained on Lama 3.2 Meta. These early versions showed promising results.
like Venturebeat It was previously reported that the smallest Cogito V1 (3B and 8B) surpassed the Lama 3 counterparts through several criteria – sometimes with wide margins.
Deep Cogito CEO and co -founder Drishan Arora LLM engineer previously described in Google-The company’s long-term goal is to build Models that can cause and improve with every repetitionIt is very similar to how Alfago improved its strategy through self -play.
It replaces the basic method of Deep Cogito, refined distillation and amplification (IDA), handwritten or steady claims with advanced model visions.
What is “intuition”?
With Cogito V2, the team took this episode much wider. The central idea is simple: thinking should not be just a tool for inference time, but rather it should be part of the basic intelligence of the model.
So the company has implemented a system in which the model runs thinking chains during training – then it is trained in its intermediate ideas.
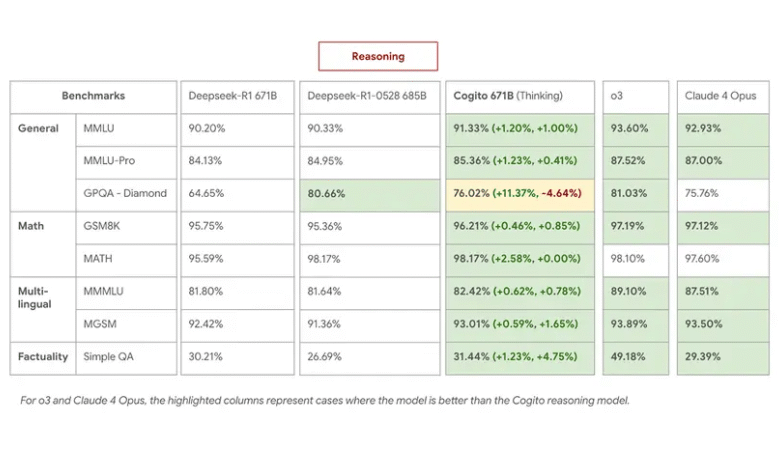
This process gives concrete improvements, according to internal standards. The Milpstion 671B model (MIE) is outperforming the deep performance of R1 in thinking tasks, matching or overcoming the latest 0528 with the use of shorter thinking chains by 60 %.
On MMLU, GSM8K and MGSM, Cogito 671b MEE was equal to the best open styles such as QWEN1.5-72B and Deepseek V3, and went to the level of closed models performance such as Claude 4 OPUS and O3.
especially:
- Cogito 671B MEE (Thinking Mode) Deepseek R1 0528 matching via multi -language QA and general knowledge tasks, and outperformed it in the strategy and logical discount.
- In a non -seasonal positionDEPSEK V3 0324, indicating that distilled intuition carries a real weight even without the extended thinking path.
- The ability of the model to complete the thinking of less steps was also the effects of the river course: low inference costs and faster response times on complex claims.
Arora explains this as a difference between searching for a path in exchange for knowing where the destination lies.
“Since Cogito models develop a better intuition for the path that must be taken while searching at the time of reasoning, they have 60 % shorter thinking chains than Deepseek R1”, written in a thread on X announced the new V2 models.
What are the types of tasks that new Deep Cogito models outperform when using their device intuition?
Some of the most persuasive examples of the internal test of Cogito V2 are exactly how this appears in use.
In a heavy mathematics claim, the user asks whether the train that travels at 80 miles per hour can reach a city 240 miles in less than 2.5 hours.
While many models mimic the account step by step and sometimes make the unit conversion errors, Cogito 671B reflects internally, determines that 240 ÷ 80 = 3 hours, and it is properly concluded that the train is Not possible It arrives in time. It does it with a short interior thinking – under 100 icons – compared to 200+ used by Deepsek R1 to reach the same answer.
In another example that includes legal thinking, the user asks whether the US Supreme Court ruling will apply to a virtual issue that includes research and seizure. The thinking position in Cogito highlights the logic of two steps: determining whether the default floor matches the previous, then explain the reason or not. The model reaches an accurate answer with a clear justification – a type of interpretative thinking that many LLMS are still fighting.
Other tasks show improvements in dealing with mystery. In a classic multi-law question-“If she is not the mother of Bob, and Bob is Charlie’s father, what is not for Charlie?” The models often intertwine in the pronouns. Cogito V2 models correctly introduce Alice as Charlie’s grandmother, even in the changes that are slightly formulated as other open models stumble.
Wide efficiency
Despite the huge size of the new models, Deep Cogito claims to have trained all eight Cogito models – including smaller V1 checkpoints – with less than $ 3.5 million, compared to $ 100 million that have been reported for some of Openaii’s leading models.
This includes data generation, synthetic enhancement, infrastructure, and more than 1,000 training experiments. Compared to the nine numbers budgets for other border models, they are part of typical spending.
ARORA attributes this asset to the company’s basic thesis: the most intelligent models need better control devices, not more symbols.
By teaching the model to overcome excess or misleading thinking paths, Cogito V2 provides stronger performance without recycling time.
This is a meaningful barter for users who operate models on infrastructure or API devices where cumin and costs are.
What is the following for Deep Cogito and V2?
The Cogito V2 version is not a final but a repetitive product. Arora describes the company’s road map as “climbing the hill” – the models you make, learn from the effects of thinking, distillation, and repeat the episode. Over time, each style becomes a stone to move for another.
Every DEP COGITO model is open source, and the company says this will remain correct for future repetitions.
Indeed, her work attracted attention and support from supporters like Eric Vishria from Benchmark and South Park Commons Agarwal.
Hugging Face, Togetter AI, Runpod, Baseten, Meta’s Llama Team and Unloth.
For developers, researchers and institutions teams, Models are now available. Developers It can be operated locally, compare the conditions, or get rid of specific cases of use.
For the broader open-source society, Cogito V2 offers more than just a new winner-suggests a different way to build intelligence. Not by thinking hard, but by learning how to think better.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-31 21:58:00



