DSRL: A Latent-Space Reinforcement Learning Approach to Adapt Diffusion Policies in Real-World Robotics
Introduction to learning -based robots
Automated control systems made great progress through the methods that replace the data -based -based learning guidelines. Instead of relying on explicit programming, you learn modern robots by monitoring and imitating procedures. This form of learning, which is often based on behavioral cloning, enables robots to actively work in organized environments. However, the transfer of these behaviors learned to realistic dynamic scenarios still represents a challenge. Robots not only need to repeat procedures, but also to adapt and refine their responses when facing uncommon tasks or environments, which is very important in achieving generalized independent behavior.
Challenges with traditional behavioral cloning
One of the basic restrictions to learn automatic policy is to rely on the pre -collected human demonstrations. These demonstrations are used to create preliminary policies through supervising learning. However, when these policies fail to generalize or perform accurately in new settings, additional offers are required to re -train, which is a dense resource process. The inability to improve policies using private robot experiences leads to ineffective adaptation. Reinforcement learning can facilitate independent improvement; However, the incompetence of the sample and the dependence on direct access to the complex policy models makes it not suitable for many publishing operations in the real world.
Restrictions of the current deployment integration
Various methods have tried to combine spreading policies with learning to enhance the refinement of robot behavior. Some efforts focused on adjusting the early steps of the spread or applying added adjustments to politics outputs. Others tried to improve the procedures by assessing the expected rewards during the judiciary steps. While these methods have improved results in simulator environments, they require intense account and direct access to politics parameters, which limits their practical organization of black or royal models. Moreover, they are struggling with instability that comes from BackProPaging through multiple -step proliferation chains.
DSRL: Frame Improving Esachement Policy
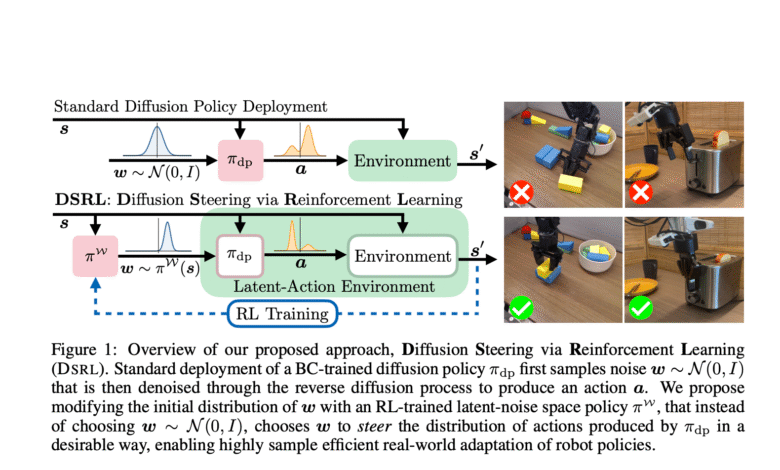
Researchers from the University of California in Berkeley, Washington University and Amazon presented a technique called deployment by learning to reinforcement (DSRL). This method turns the adaptation process from modifying policy weights to improving the underlying noise used in the proliferation model. Instead of creating procedures for a fixed Gaous distribution, DSRL is a secondary policy that chooses input noise in a way that directs the procedures resulting towards the desired results. This enhances enhancement of behavior light efficiently without changing the basic model or requires internal access.

Local optical space and policy disengagement
The researchers restructuring the learning environment by setting the original movement space to an underlying noise. In this transformer setting, the procedures are chosen indirectly by choosing the underlying noise that you will produce through the spread policy. By dealing with noise as a procedure variable, DSRL creates an educational framework that fully works outside the basic policy, using only its front outputs. This design makes adaptive to the real world’s automatic systems where only access to the black box is available. A policy that chooses the inherent noise can be trained using standard effects, thus avoiding the calculations for the rear translation through the steps of spread. The approach allows online learning through actual time reactions and learning without contact from the data collected in advance.
Experimental results and practical benefits
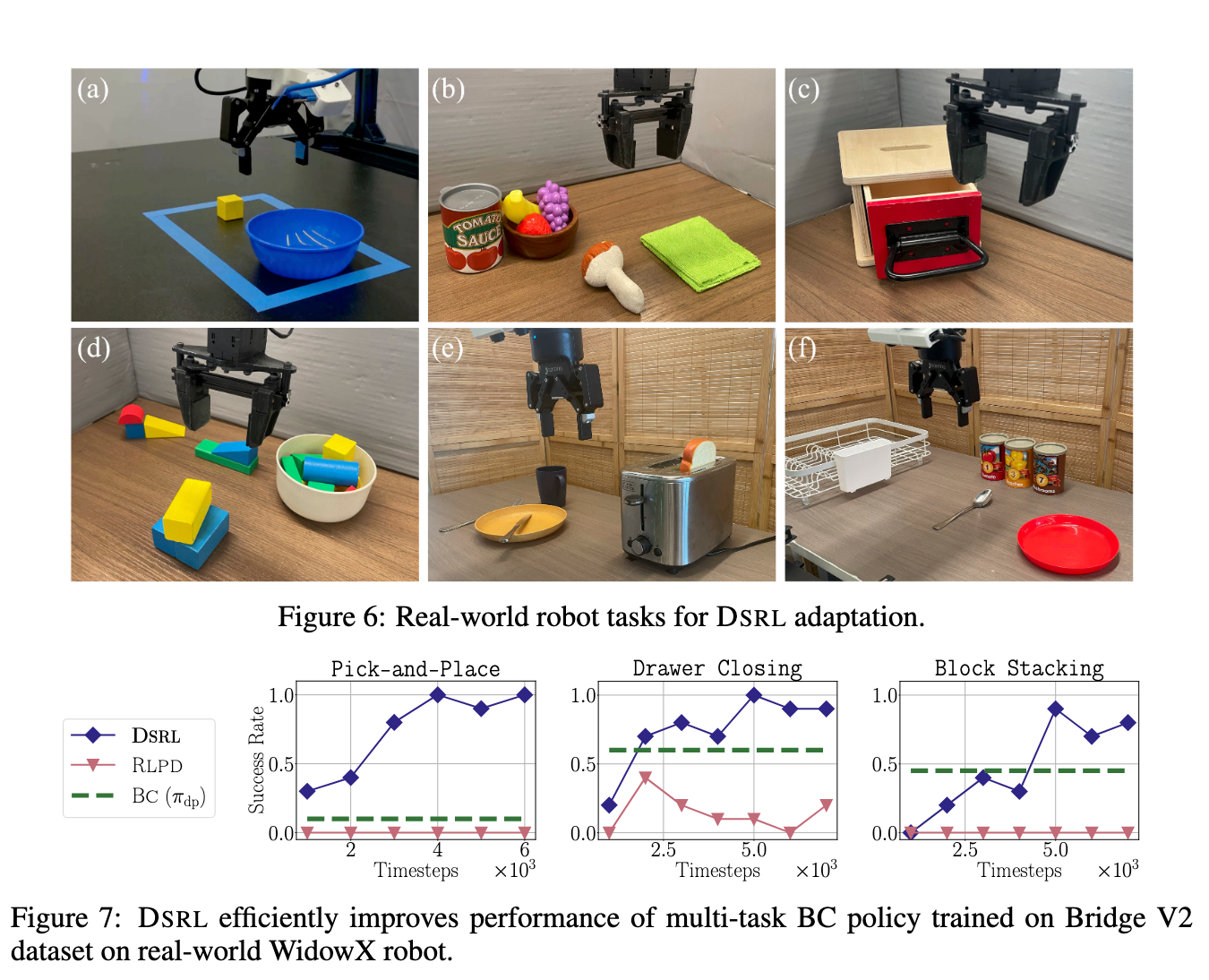
The proposed method showed clear improvements in performance and data efficiency. For example, on a real -world robotic mission, DSRL has improved the mission success rates from 20 % to 90 % in less than 50 episodes of online interaction. This represents an increase in performance with more than four times with minimal data. This method was also tested on an expert robotic policy called π₀, and DSRL was able to effectively enhance publishing behavior. These results were achieved without modifying the basic proliferation policy or accessing their parameters, and displaying the practical application of the method in restricted environments, such as only API.
conclusion
In short, the research dealt with the main issue of adapting the automatic policy without relying on wide re -training or direct access to the form. By entering a harmful noise guidance mechanism, the team has developed a strong but powerful tool to learn robot in the real world. The strength of the method lies in its efficiency, stability and compatibility with the current proliferation models, which makes it a big step forward in spreading adaptable automatic systems.
verify Paper and project page. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-30 07:06:00