
EPFL Researchers Introduce MEMOIR: A Scalable Framework for Lifelong Model Editing in LLMs
The challenge of updating knowledge LLM
LLMS has shown a distinguished performance of various tasks through large -scale prior training on wide data sets. However, these models often create old or inaccurate information and can reflect biases during publication, so their knowledge must be updated continuously. Traditional seizure methods are expensive and vulnerable to catastrophic forgetfulness. It motivated the editing of models for life, which updates the typical knowledge efficiently and localized. To create correct predictions, it requires all reliability, generalization and localization. Methods like non -Parameter make accurate local adjustments but a weak generalization, while border methods provide a better generalization but suffer from catastrophic forgetfulness.
Little former models editing techniques
Previously, previously neural activation works have explored continuous learning, with methods such as Packnet and SuperMasks-in-Suposition, customizing sub-groups for each task. Rating -based methods such as GPM and Sparcl improve efficiency through orthogonal updates, but are limited to continuous learning contexts. Parameter methods such as Rome, Mimite are modified, and wise weight modification strategies through location identification strategies or additional units, but they suffer from forgetting the extended editing sequence. Non -Parameter methods such as Grace and Loka Store externally to preserve the original weights, allowing accurate local adjustments. However, these methods depend on accurate input matches, which limits generalization capabilities.
Providing notes: an organized approach to editing models
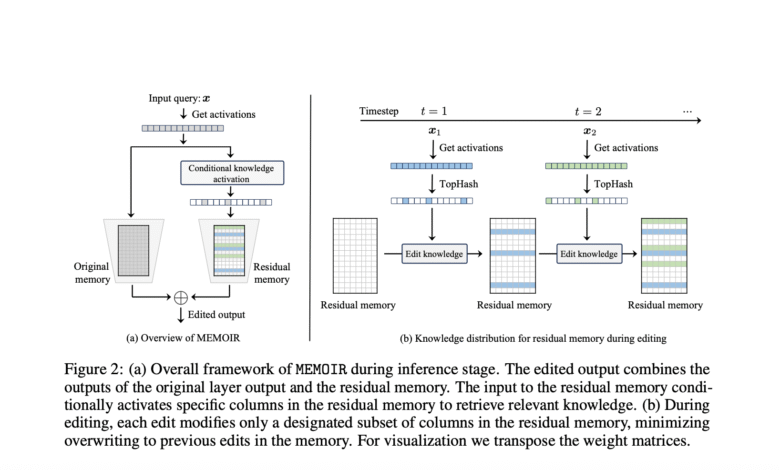
EPFL researchers, Lausanne, Switzerland, suggested notes (models editing with minimal writing and enlightened retention), which achieves an ideal balance between reliability, circular and local for large -scale liberators. It offers a memory unit consisting of a fully connected layer within one converter block where all adjustments occur. The catastrophic notes are solved by allocating distinguished sub -groups for each teacher for each editing and recovery during the inference to stimulate the relevant knowledge only for specific demands. Moreover, the method uses the interpretation of organized contrast with masks based on the sample during the liberation, and the activation of only special parameters. Distributing new knowledge through the space of the teacher, which reduces writing above and reduces catastrophic forgetfulness.
Evaluation and experimental results
Memoir works through the remaining memory frame during inference, as the modified output combines the outputs of the original layer with the remaining memory outputs. It is evaluated against basic lines such as Grace to store external knowledge, postpone to direct inference time, causal tracking methods such as Rome, Mimite, Alphaedit, and memory -based methods such as wisdom. Direct adjustment acts as an additional basic comparison. Experiments are conducted on four self-linguistic models: Llama-3b-Instruct, Mistral-7B, Llama-2-7B, and GPT-J-6B, providing a comprehensive evaluation through various models and standards to show the effectiveness and generalization of Momoir.
On the ZSRE data collection to cancel questions, average average scale notes of Llama-3 with 1000 modifications, outperform all previous methods of 0.16 margin. Similar results are seen with Mistral, as this method again achieves the highest average degree, highlighting its durability and effectiveness across the various LLMS. Moreover, Memoir maintains the optimal balanced performance with an increase in editing sizes to correct hallucinations using the SelfcheckGPT data collection. Notes maintain saturated local grades in light of the most challenging scenario of 600 modifications, with a scale of confusion by 57 % and 77 % of the sage, the second best performance method, on Lama-3 and Mistral, respectively.
Conclusion and future trends
In conclusion, Memoir is a developmental framework for lifelong models and effectively balanced reliability, generalization and location using innovative contrast techniques. The method recovers relevant updates by comparing the sporadic activation pattern, allowing the adjustments to circulating to re -drafting queries while maintaining the behavior of the unrealistic claims. However, there are some restrictions, such as modifying only single linear layers, which may restrict the tall or knowledge modifications that require wider model changes. Future trends include expanding the scope of multiple layers, hierarchical editing strategies, applying to multimedia models or encoding coding outside the concentration of the current transformer only.
verify paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.

Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-06-17 04:41:00



