
ether0: A 24B LLM Trained with Reinforcement Learning RL for Advanced Chemical Reasoning Tasks
LLMS enhances accuracy primarily by expanding pre -training data and computing resources. However, attention to alternative scale has turned due to the availability of limited data. This includes training at the time of testing and the reasoning account. Performing thinking models are enhanced by emitting thinking processes before answers, initially by Cot Prompting. Recently, reinforcement learning (RL) has been used after training. Scientific fields offer ideal opportunities for thinking models. The reason is that it involves “counter -problems” where the quality of the solution quality is clear, but the generation of solutions is still difficult. Despite the conceptual compatibility between organized scientific thinking and typical capabilities, current methods lack the detailed methods of scientific thinking beyond multiple selection criteria.
The technical development of the structure of thinking
Thinking models have evolved from bed -based early methods, Coter Zero shot, and thought tree. They have advanced to the complex RL curricula by improving the group’s relative policy (GRPO) and measuring the time of reasoning. Moreover, thinking models in chemistry focus on knowledge -based standards instead of complex thinking tasks. Examples include re -synthesis or molecular design. While data groups such as GPQA-D and MMLU assess chemical knowledge, they fail to assess complex chemical thinking capabilities. The current scientific thinking efforts remain fragmented. Limited attempts include the reverse science of public science, Med-R1 for the tasks of the medical vision language, and the vital season of genetic thinking. However, there is no comprehensive framework for training on the chemical thinking model on a large scale.
Principles of architecture and design ether0
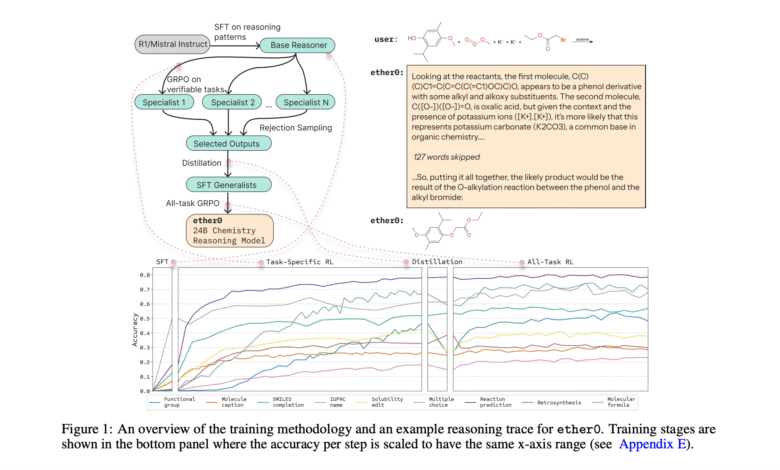
Researchers from the future suggested Ether0A new model that causes the natural language and comes out molecular structures as smiling chains. It explains the effectiveness of the models of thinking about chemical tasks. It surpasses Frontier Llms, human experts, and general chemistry models. Training approach uses many improvements to vanilla RL. This includes distillation of thinking behavior, dynamic curricula, and preparing experts model to enhance efficiency and effectiveness. Moreover, factors such as data efficiency, failure conditions, and thinking behavior are analyzed. This analysis allows a better understanding of the benefit of thinking about solving chemistry problems.
Training pipeline: distillation and integration GRPO
The model uses a multi -stage training procedure alternating between distillation stages and GRPO. Architecture offers four special symbols. These symbols paint the limits and response. SFT training begins on the long COT sequence resulting from Deepseek-R1. These are filtered to coordinate good smiles, and the quality of thinking. The RL specialist then improves the special task policies of different problems with GRPO. Then, distillation is integrated with specialized models in a general expert. This merger occurs through the SFT on the correct responses collected during the training. GRPO, the general expert, applies to the built -in model. This includes continuous quality liquidation to remove low -quality thinking and unwanted molecular structure.
Performance evaluation and comparative standards
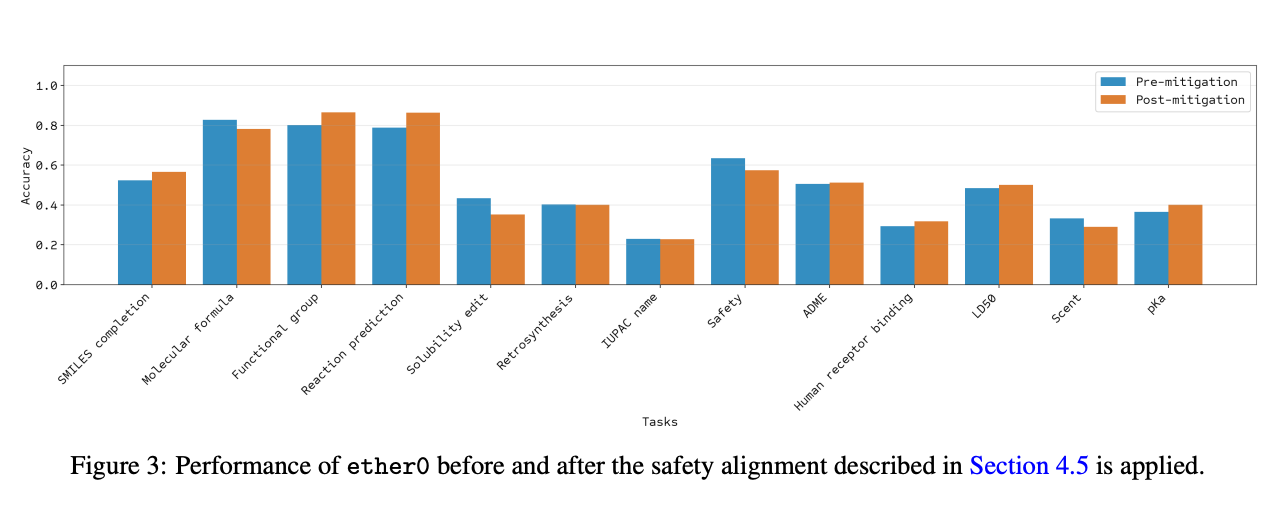
ETHER0 explains a superior performance against both LLMS for general purposes such as Claude and O1, and chemistry models, including Chemdfm and TXGEMMA. It achieves the highest accuracy in all open answer categories while maintaining competitive performance on multiple choice questions. For data efficiency, the model outperforms traditional molecular transformer models. It is trained on only 60,000 reaction compared to full USPTO data groups. ETHER0 achieves 70 % resolution after seeing 46000 training. Molecular transformers achieved 64.1 % on full data sets compared. Under the conditions of one shot, ETHER0 exceeds all the boundary models that have been evaluated. Safety alignment procedures successfully liquidate 80 % of unsafe questions without decomposing performance in basic chemistry tasks.
Conclusion: The effects of future LLMS scientific
In conclusion, researchers, ETHER0, a 24B teacher model who was trained in ten difficult molecular tasks. It greatly outperforms the LLMS border, domain experts and specialized models. This is achieved through the overlapping RL pipeline and distillation behavior. The model displays exceptional data and thinking capabilities. It excels in the tasks of open answer chemistry that includes molecular design, achievement, modification, and synthesis. However, restrictions include possible generalization challenges that exceed organic chemistry. Moreover, there is a loss in the follow -up of public instructions and the absence of tools. The release of the weight weights, standard data and reward functions determines mainly. This basis helps advance scientific thinking models through various fields.
Check out paper and technical details. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 99k+ ml subreddit And subscribe to Our newsletter.
▶ You want to promote the product/symposium/service to a million engineers/developers/from AI. Let’s partner ..

Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-10 19:33:00



