Falcon LLM Team Releases Falcon-H1 Technical Report: A Hybrid Attention–SSM Model That Rivals 70B LLMs

introduction
The Falcon-H1 series, developed by the Institute of Technology Innovation (TII), is a great progress in the development of large language models (LLMS). By integrating attention based on transformers with MAMBA (SSMS) spacecraft models in a hybrid parallel composition, Falcon-H1 achieves exceptional performance, memory efficiency, and expansion. Falcon-H1 models, which were released in multiple sizes (from 0.5b to 34b) and versions (basis, seized, quantity), are re-defined the comparison between the account budget and the quality of the output, providing a superior teacher efficiency on many contemporary models such as QWen2.5-72B and Llama3.3-70B.
Main architectural innovations
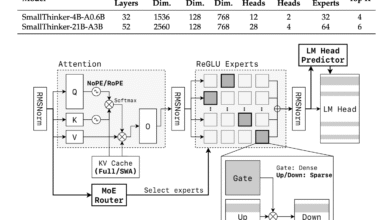
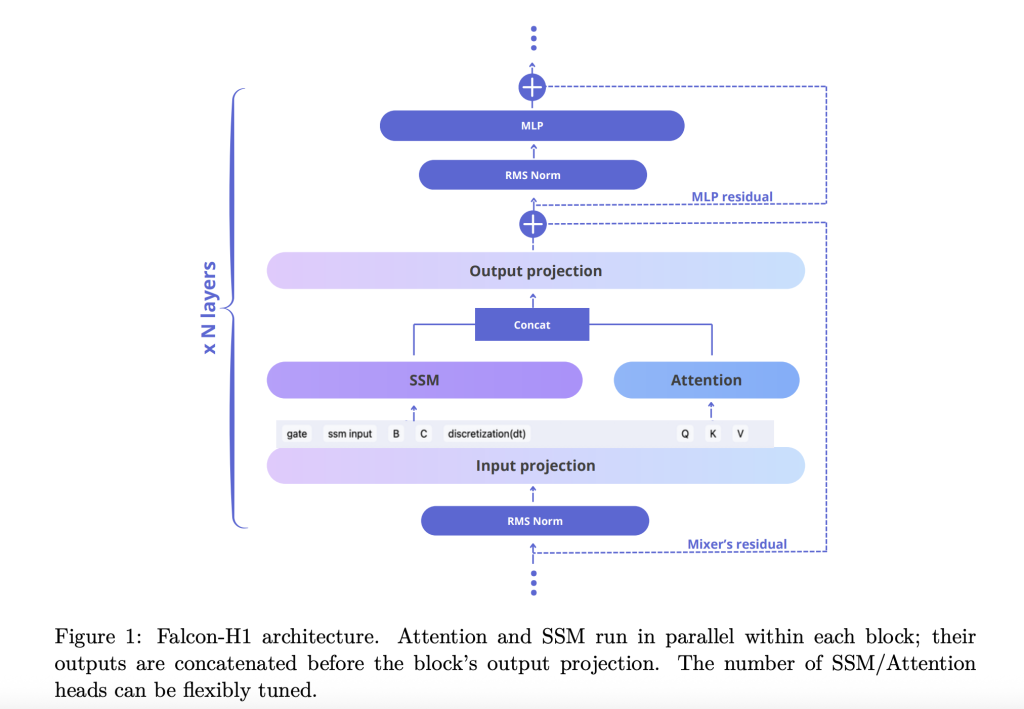
the Technical report Explain how Falcon-H1 adopts a novel Parally hybrid structure Where both the interest units and SSM work simultaneously, and the sequence of its outputs before projection. This design deviates from traditional serial integration and provides flexibility to control the number of attention and SSM channels independently. Virtual composition uses 2: 1: 5 for SSM, Lunting and MLP channels, respectively, which improves efficiency and learning dynamics.
 team-Releases-Falcon-H1-Technical-Report-A-Hybrid-Attention–SSM.png" alt=""/>
team-Releases-Falcon-H1-Technical-Report-A-Hybrid-Attention–SSM.png" alt=""/>To continue to improve the model, the Falcon-H1:
- Customize the channelAblution shows that the growing interest channels deteriorate performance, while the SSM and MLP budget make strong gains.
- Composition of a block: SA_M composition (semi -parallel with attention and SSM works together, followed by MLP) is the best in losing training and mathematical efficiency.
- Cord base frequencyUnusually highly high base frequency of 10^11 in the optimal topical inclusion (ROPE), and improving circular during training in the long context.
- View the preference depthExperiments show that deeper models outperform the broader models under the budgets of fixed parameters. Falcon-H1-1.5B-DEP (66 layers) outperforms many 3B and 7B models.
Distinguished symbol strategy
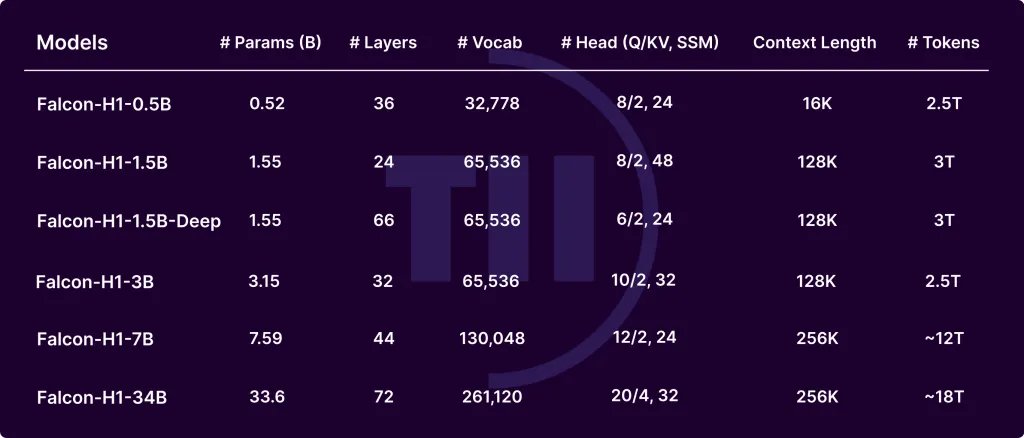
Falcon-H1 uses a suite dedicated to the bit of component with vocabulary sizes ranging from 32 thousand to 261 km. The main design options include:
- Divide numbers and numbering marks: Excellent performance in code and multi -language settings.
- Latex symbol injectionIt enhances the accuracy of the model on mathematics standards.
- Multi -language supportIt covers 18 languages and standards to 100+, using fertility and bright/distinctive code standards.
Pre -strategy and data strategy group
Falcon-H1 models are trained on up to 18T symbols from a symbolic set carefully carefully, which includes:
- High quality web data (FILEDEWEB) Refinery)
- Multi -language data sets: Common crawl, Wikipedia, Arxiv, OpenSubtitles, and 17 languages.
- Corpus code: 67 languages, are processed by canceling Minhash data, Codebert quality filters, and rubb
- Mathematics data groups: Mathematics, GSM8K, and improved crawls in the latex at home
- Artificial dataRe -writing from Raw Corpora using a variety of LLMS, as well
- Long context serials: It was strengthened through the tasks of thinking about the center, rearrangement, and artificial logic, up to 256 thousand symbols
Infrastructure and systematic training
Use the training for maximum update (µP), and to support smooth scaling through models sizes. Models use advanced parallel strategies:
- Parallel mixer (MP) and Parallel context (CP): Enhancing productivity to address the long context
- Quantity: It was released in BFLOAT16 and 4 -bit variables to facilitate edge post
Evaluation and performance
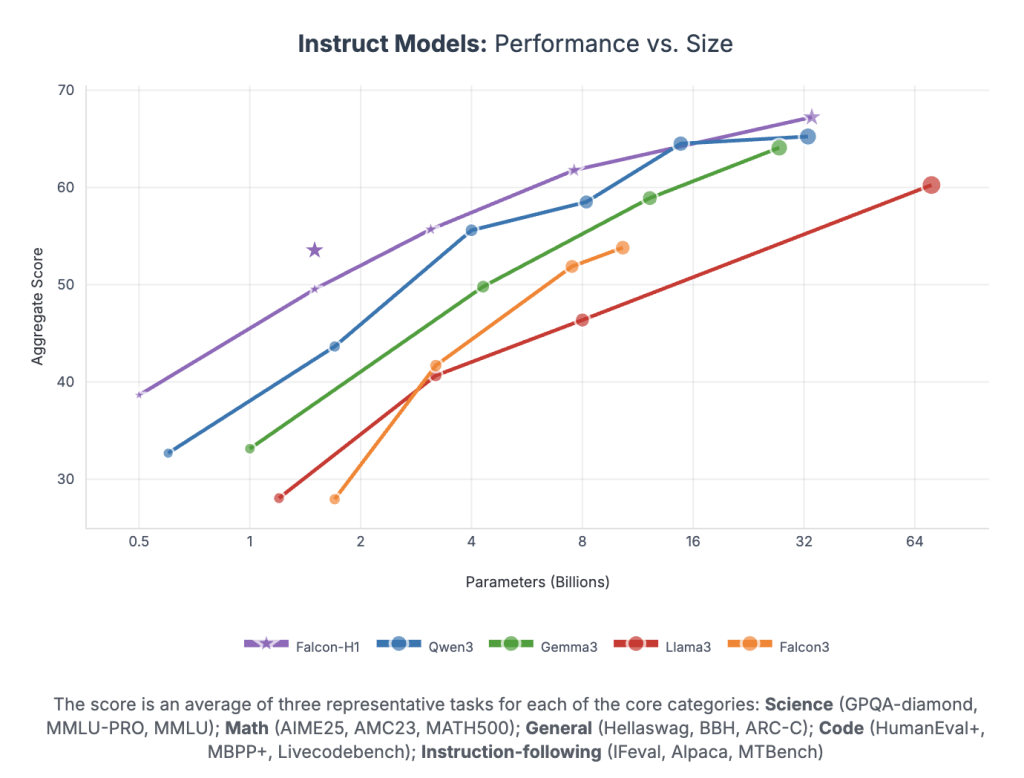
Falcon-H1 achieves an unprecedented performance for every teacher:
- Falcon-H1-34B-Instruct It exceeds or matches 70B models on a scale such as QWEN2.5-72B and Llama33.3-70B across logic, mathematics, follow-up education, and multi-language tasks
- Falcon-H1-1.5B-Deep Models of its competitors from 7b -10b
- Falcon-H1-0.5B It offers 7B performance for the age of 2024
Standard standards MMLU, GSM8K, Humaneval, and long context tasks. The models show strong alignment via SFT and improve direct preference (DPO).
conclusion
Falcon-H1 sets a new standard for open-weight LLMS by integrating the parallel hybrid structure, flexible distinctive symbol, effective training dynamics, and powerful multi-language capacity. Its strategic blend of SSM and attention allows unparalleled performance in account budgets and practical memory, making it ideal for research and publication through various environments.
verify Paper and models embracing. Do not hesitate to Check our educational programs page on AI Agen. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.

Michal Susttter is a data science specialist with a master’s degree in Data Science from the University of Badova. With a solid foundation in statistical analysis, automatic learning, and data engineering, Michal is superior to converting complex data groups into implementable visions.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-08-01 08:36:00