
Google’s Sensible Agent Reframes Augmented Reality (AR) Assistance as a Coupled “what+how” Decision—So What does that Change?

The reasonable factor is the framework of artificial intelligence research and the initial model of Google who chooses both of them the an act The augmented reality agent (AR) must take and Reaction To deliver/confirm this, conditional on multimedia context in actual time (for example, whether hands are busy, surrounding noise, social preparation). Instead of dealing with “what you suggest” and “how to ask” as separate problems, it calculates it jointly to reduce friction and social embarrassment in the wilderness.
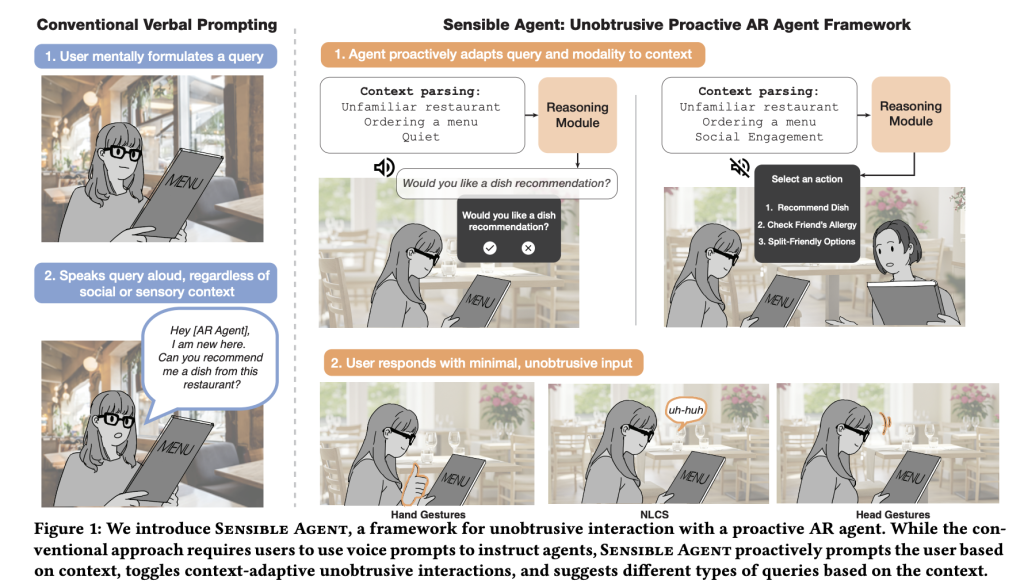
What are the conditions of the failure of the reaction you target?
The first audio transformation is fragile: it’s slowly under time pressure, unused with crowded hands/eyes, and embarrassed in public places. The main bet of the reasonable agent is that the high -quality proposal is presented through the wrong channel is an effective noise. Explicit working framework Joint decision From (a) What The agent suggests (recommends/directs/reminds/automated) and (b) how It is presented and confirmed (optical, audio or both; inputs via Nod/Shake/Tilt, look analgesic, finger modes, short rhetoric, or non -strong conversation sounds). By linking the content content to the feasibility of the method and social acceptance, the system aims to reduce the perceived effort while maintaining interest.
How is the system archived at the time of operation?
The initial model is carried out on the I Android headphones pipeline with Three major stages. Firstly, Context analysis Selfish images (the conclusion of the vision language of the scene/activity/familiarity) with the surrounding sound workbook (Yamnet) to discover conditions such as noise or conversation. Second, a A proactive inquiry generator It calls for a large multimedia model with few models to determine an actand Inquiry structure (Bilateral / multi -chart / code), and Display. Third, Reaction Only the methods of entry compatible with the availability of the input/sensor directing, for example, enables the head gesture to “yes” when the whisper is not acceptable, or inhabits the view when occupying hands.
Where do the few policies-instinct or data come from?
The team planted two policy spaces: Expert workshop (n = 12) For the census when pre -emptive assistance is useful and any small inputs are socially acceptable; and Study of the authenticity of the context (n = 40; 960 entries) Through daily scenarios (for example, gym, grocery, museum, mobility, cooking) where the participants have identified the required agent procedures and chose a favorite Type query and road Looking at the context. These appointments accumulate on a few models used at the time of operation, and convert the choice of “What + How” from the devoted inference to the patterns derived from data (for example, the multiple choice in unhelpful environments, two -time pressure, and + optical icon in socially sensitive settings).
What are the concrete interaction techniques that the initial model supports?
to bilateral The assurances, the system is recognized Head/shaking; to Multi -chart, Head Left maps chart/right/return to options 1/2/3. finger Hymmetries support digital choice and thumb up/down; Look to live It raises visual buttons as Raycast’s marking will be difficult; Short short speech (For example, “Yes”, “No”, “One”, “Two”, “Three”) provides the path of minimal dictation; and Sounds of the non -strong conversation (“MM-HM”) covers only noisy contexts or whisper. It is important, the pipeline only provides possible cord with the current restrictions (for example, suppressing sound demands in calm spaces; avoiding the view if the user does not look at HUD).
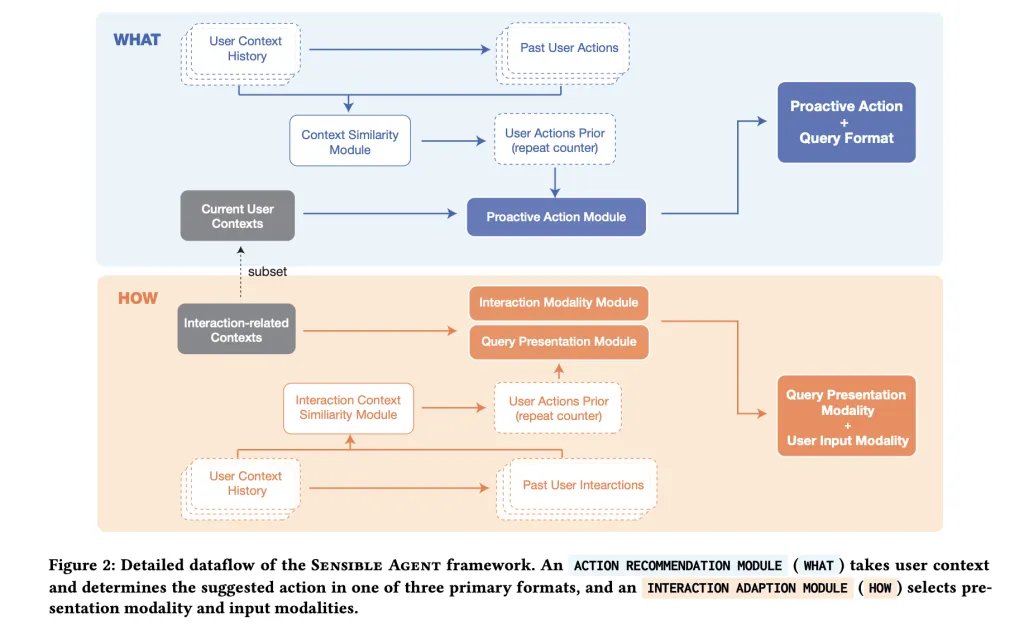
Does the joint decision already reduce the cost of interaction?
Initial user study within the topic (N = 10) Comparing the frame with the audio line via AR and 360 degrees VR Low reaction voltage imagined and Low intervention While maintaining the ability to use and preference. This is a typical small sample to verify early HCI health; It is a directional evidence rather than evidence of the product level, but it is compatible with the thesis that the intention and the way it reduces from public expenditures.
How does the audio side work, and why do you wish?
Yamnet is a lightweight audio work, Mobilenet-V1, based on Mobilinite, a Google’s voice coach, and is expected 521 categories. In this context, it is a practical option to reveal the harsh surrounding conditions – music presence, music, or crowd noise – sufficiently for sound or bias towards visual interaction/gestures when the speech is embarrassing or unreliable. The prevalence of the model at the Tensorflow and Edge center makes it easy to post on the device.
How can you integrate it into an AR or ASPORT Assistant?
The lower adoption plan appears to be like this: (1) a lightweight context analysis tool (VLM on Eugenetric + surrounding signs) to produce a compact state; (2) Building a A few table Context → (procedure, query type, method) appointments from internal pilots or user studies; (3) LMM demand for emission both of them “What” and “How” at the same time; (4) Express only maybe Entering methods for each state and maintaining assertions bilateral By default (5) record records and results for the Internet Learn politics. Reasonable artifacts show that this is possible in WeBXR/Chrome on Android android devices, so deportation until the time of the original HMD or even HUD is often based on the phone is a geometric exercise.
summary
The reasonable Agent runs an AR proactive as a associated political problem – select an act and Reaction In a single-air-conditioned decision-the verification of the approach is valid through the primary model of the WeBXR and the study of a small user from N shows the interaction voltage lowly for the audio foundation. The contribution of the frame is not a producer but rather a repetitive recipe: a set of data from the context → (what/how) appointments, demands for a few shots to link them at the time of operation, and low input restrictions that respect social restrictions and input/output.
verify Paper and technical details. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.

Michal Susttter is a data science specialist with a master’s degree in Data Science from the University of Badova. With a solid foundation in statistical analysis, automatic learning, and data engineering, Michal is superior to converting complex data groups into implementable visions.
🔥[Recommended Read] Nvidia AI Open-Sources VIPE (Video Forms)
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-09-19 16:46:00



