
Hidden costs in AI deployment: Why Claude models may be 20-30% more expensive than GPT in enterprise settings

It is a known fact that different model families can use different features. However, there was a limited analysis on how practical “Distinguished symbol“ Sim The same through these features. Do all features lead to the same number of distinctive symbols of a specific entry text? If not, how much is the different codes? How important is the differences?
In this article, we explore these questions and study the practical effects of fluctuating the distinctive symbol. We offer a comparative story for two FRANAI’s Chatgpt Vs Anthropic’s Clade families. Although the cost numbers that are announced through the competition are highly, experiments reveal that human models can be 20-30 % more expensive than GPT models.
API-Claude 3.5 Sonnet VS GPT-4O
As of June 2024, the pricing structure of these two advanced border models is very competitive. Both Claude 3.5 Sonnet and Openai’s GPT-4O have identical costs for output symbols, while Claude 3.5 Sonnet provides a 40 % lower cost for input symbols.

Source: Vantage
Hidden “The Distinguished Symbol”
Although the input code rates for the human model are low, we have noticed that the total costs of running experiences (on a certain set of fixed claims) with GPT-4O is much cheaper compared to Clauds Sonnet-3.5.
Why?
The human distinguished tends to destroy the same inputs into more distinctive symbols compared to Openai. This means that for identical demands, human models produce much more than their Openai. As a result, while the cost of Claude Cleude 3.5 may be less Sonnet inputs, the growing distinctive symbol can compensate for these savings, which leads to high total costs in practical cases of use.
This hidden cost stems from the way to cod the information from the Anthropor, and often use more symbols to represent the same content. The enlargement of the distinctive symbol has a significant effect on costs and the use of context window.
The unique symbol depends on the field
Various types of field content are designed differently through the distinctive symbol of the anthropologist, which leads to varying levels of increasing symbolic charges compared to Openai models. The artificial intelligence research community has noticed similar symbolic differences here. We have tested the results we reached on three famous areas, namely: English articles, Python and Mathematics.
| specialization | Enter the form | GPT codes | Claude symbols | % Distinguished symbol |
| English articles | 77 | 89 | ~ 16 % | |
| Peton Code | 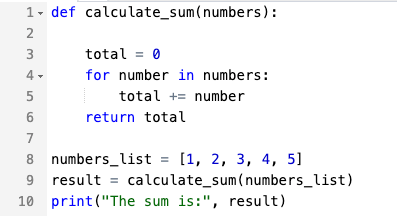 | 60 | 78 | ~ 30 % |
| mathematics | 114 | 138 | ~ 21 % |
% Distinctive symbol from Claude 3.5 Sonit the distinctive symbol (relative to GPT-4O) Source: Lavania Gupta
When comparing the Claude 3.5 Sonnet to GPT-4O, the degree of inefficiency of the distinctive symbol varies greatly through the contents of the content. For English articles, Clauds’s Tokeenizer produces about 16 % of the distinctive GPT-4O symbols for the same text text. This public expenditures increase sharply with more organized or technical content: for mathematical equations, the size of the general expenditures is 21 %, and by the brightness symbol, Claude generates 30 % of the distinctive symbols.
This difference arises because some types of content, such as technical documents and the symbol, often contain patterns and symbols. Fragments of human symbols are a smaller pieces, which leads to the number of distinctive symbols higher. In contrast, more natural language content tends to show low symbolic expenses.
Other practical effects of the lack of efficiency of the distinctive symbol
In addition to direct inclusion of costs, there is also an indirect effect on the use of context window. While human models claim a window of a larger context of 200 kilometers, unlike the distinctive symbols of Openai 128K, due to the separators, the effective effective symbol space may be smaller in human models. Thus, there can be a small or large difference in the “declared” context window sizes in exchange for the “effective” context window sizes.
Implementation of features
GPT models use a BIT pair coding, which often merges the pairs of letters that occur frequently to form the symbols. Specifically, the latest GPT models use O200K_Base Open Source. Here the actual symbols used by GPT-4O (in Tiktoken Tokeenizer) can be found here.
JSON
{
#reasoning
"o1-xxx": "o200k_base",
"o3-xxx": "o200k_base",
# chat
"chatgpt-4o-": "o200k_base",
"gpt-4o-xxx": "o200k_base", # e.g., gpt-4o-2024-05-13
"gpt-4-xxx": "cl100k_base", # e.g., gpt-4-0314, etc., plus gpt-4-32k
"gpt-3.5-turbo-xxx": "cl100k_base", # e.g, gpt-3.5-turbo-0301, -0401, etc.
}
Unfortunately, it is not possible to say much about human features because the distinctive symbol is not directly available and easy like GPT. Anthropor released the symbolic counting interface in December 2024. However, it was soon interpreted in 2025 releases later.
Latenode notes that “Anthropor uses a unique symbol with only 65,000 symbolic differences, compared to symbolic changes 100,261 from Openaii for GPT-4.” This Collap notebook contains a biton icon to analyze symbolic differences between GPT and Claude models. Another tool that allows communication with some common features available to the public that achieve our results.
The ability to estimate symbolic charges in a proactive manner (without calling the actual model programming interface) and budget costs is extremely important for artificial intelligence institutions.
Main meals
- The competitive pricing of the anthropoor comes with hidden costs:
While Claude 3.5 Sonnet of Anthropology provides 40 % lower input code costs compared to the GPT-4O of Openai, this clear cost feature can be misleading due to the differences in how to represent the entry text. - Hidden “Non -Efficiency in the Distinguished Code”:
Human models are more in nature lengthy. For companies that deal with large amounts of text, understanding this contradiction is crucial when assessing the real cost of publishing forms. - The discriminatory symbol dependent on the field:
When choosing between Openai and human models, Evaluate the nature of your input text. For normal language tasks, the cost difference may be minimal, but technical or organized areas may lead to much higher costs with human models. - Effective context window:
Due to the death of Tokeenizer’s Tokeenizer, the declared 200K window may provide a less useful space than Openai, which leads to a possible The gap between the window of the context announced and actual.
Antarbur did not respond to Venturebeat requests to comment at the time of the press. We will update the story if they respond.

Don’t miss more hot News like this! Click here to discover the latest in Technology news!
2025-05-01 20:14:00

