
How Latent Vector Fields Reveal the Inner Workings of Neural Autoencoders
Automatic coding devices and the potential space
Nervous networks are designed to learn compressed representations of high -dimensional data, and Autoenders (AES) are a widespread example of these models. These systems are used with the purpose of coding coding to record data in a low -dimensional inherent space and then rebuild them to their original shape. In this inherent space, the input patterns and features become more interpretation, allowing the performance of various estuary tasks. Automatic coding devices have been widely used in areas such as the classification of images and obstetrics and the detection of anomalies thanks to their ability to represent complex distributions through more management representations.
Conservation against generalization in nerve models
There is an ongoing problem with nervous models, especially automatic factors, which is to determine how to achieve a balance between preserving training data and generalization on invisible examples. This balance is crucial: if the model is excessive, it may fail to perform new data; If you generalize too much, it may lose useful details. Researchers are particularly interested in whether these models are coding knowledge in a way that can be detected and measured, even in the absence of direct entry data. Understanding this balance can help improve the design of the design of the models and training strategies, and provide an insight into the nervous models that you keep from the data they process.
Current investigation methods and restrictions
The current techniques of investigating this behavior often analyze performance standards, such as reconstruction error, but these only scratch the surface. Other methods use modifications to the form or inputs to gain an insight into the internal mechanisms. However, they usually do not reveal how the model structure and training dynamics affect learning results. The need to represent the deepest research led to more fundamental and interpretative methods to study the behavior of the model that exceeds traditional measures or architectural modifications.
The Perspective of the Perspective Field: The dynamic systems in the inherent space
Researchers from IST Austria and Sapienza University presented a new way to interpret automatic coding devices as dynamic systems operating in the inherent space. By applying the coding coding function over and over again, they build an inherent vector field that reveals gravity-stable points in the inherent space where data representations stabilize. This field is inherently in any automatic encrypted and does not require changes on the form or additional training. Their way to visualize how data moves through the form and how these movements are linked to generalization and memorization. Test this through data collections and even basic models, which extend their visions beyond the artificial standards.
Repeating maps and contraction homes
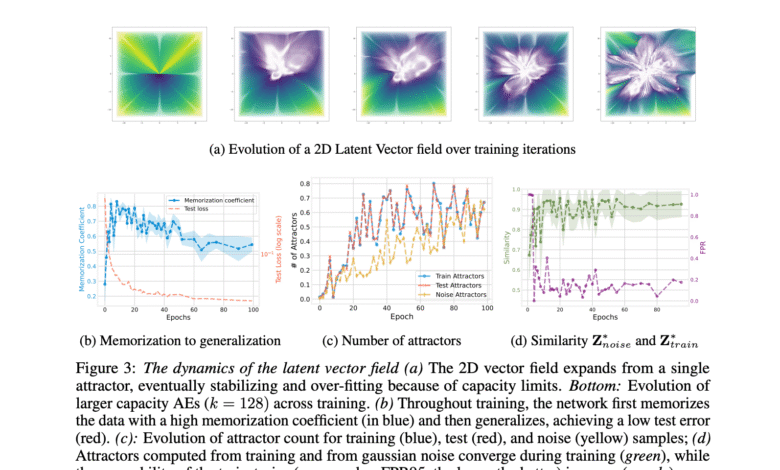
This method includes the frequent processing application to draw encryption and encryption maps as a separate differential equation. In this formula, any point is assigned to the inherent space frequently, which constitutes a path determined by the remaining vector between each repetition and its inputs. If the appointment is contracted – however, each application reduces the space – the system settles on a fixed or attractive point. The researchers have proven that common design options, such as weight decay, small bottleneck dimensions, and reinforcement -based training, reinforce this natural shrinkage. Consequently, the volatile field works as an implicit summary of the training dynamics, and reveals how and the place to learn the data encryption forms.
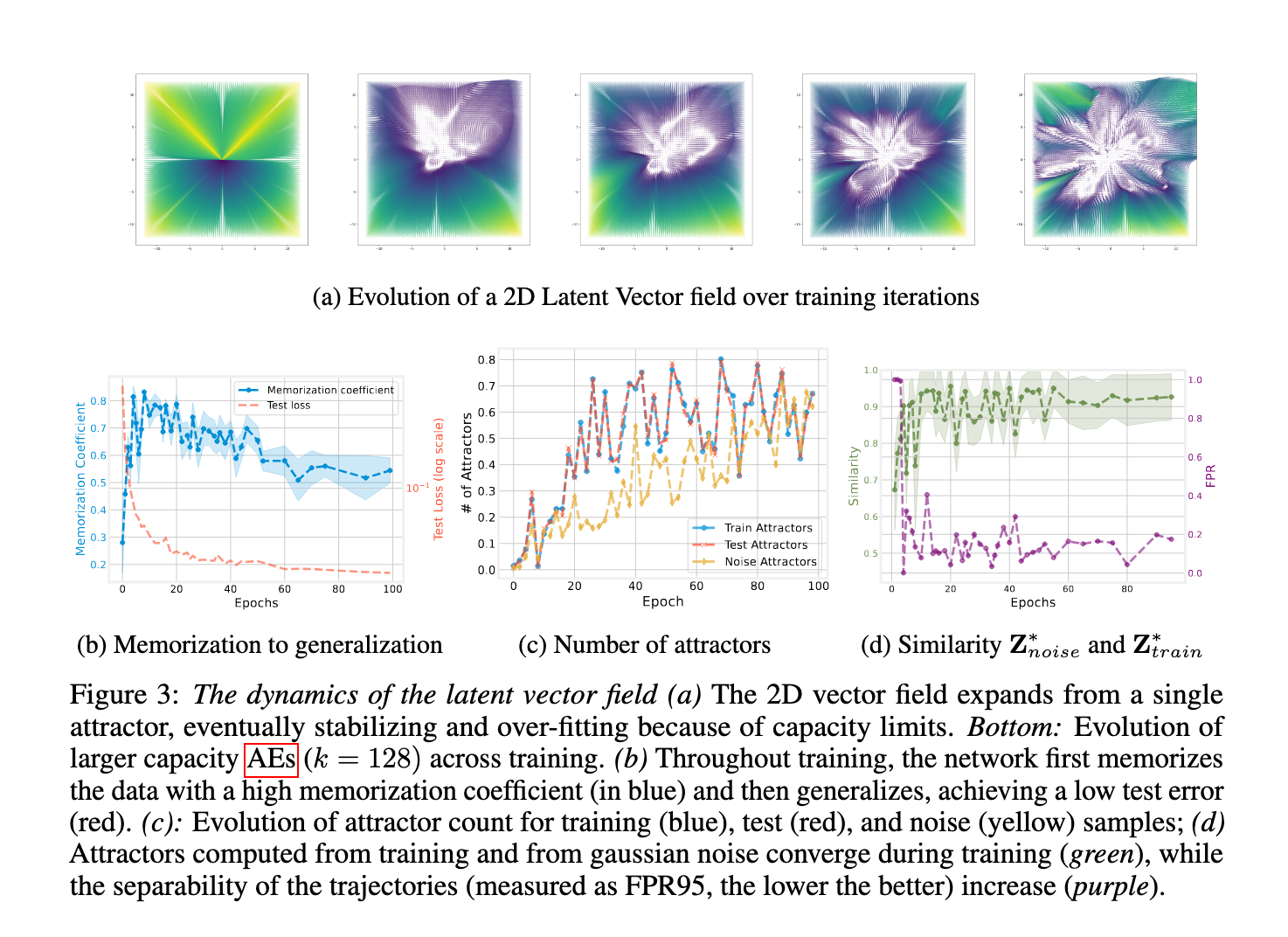
Experimental results: gravity encodes the behavior of the model
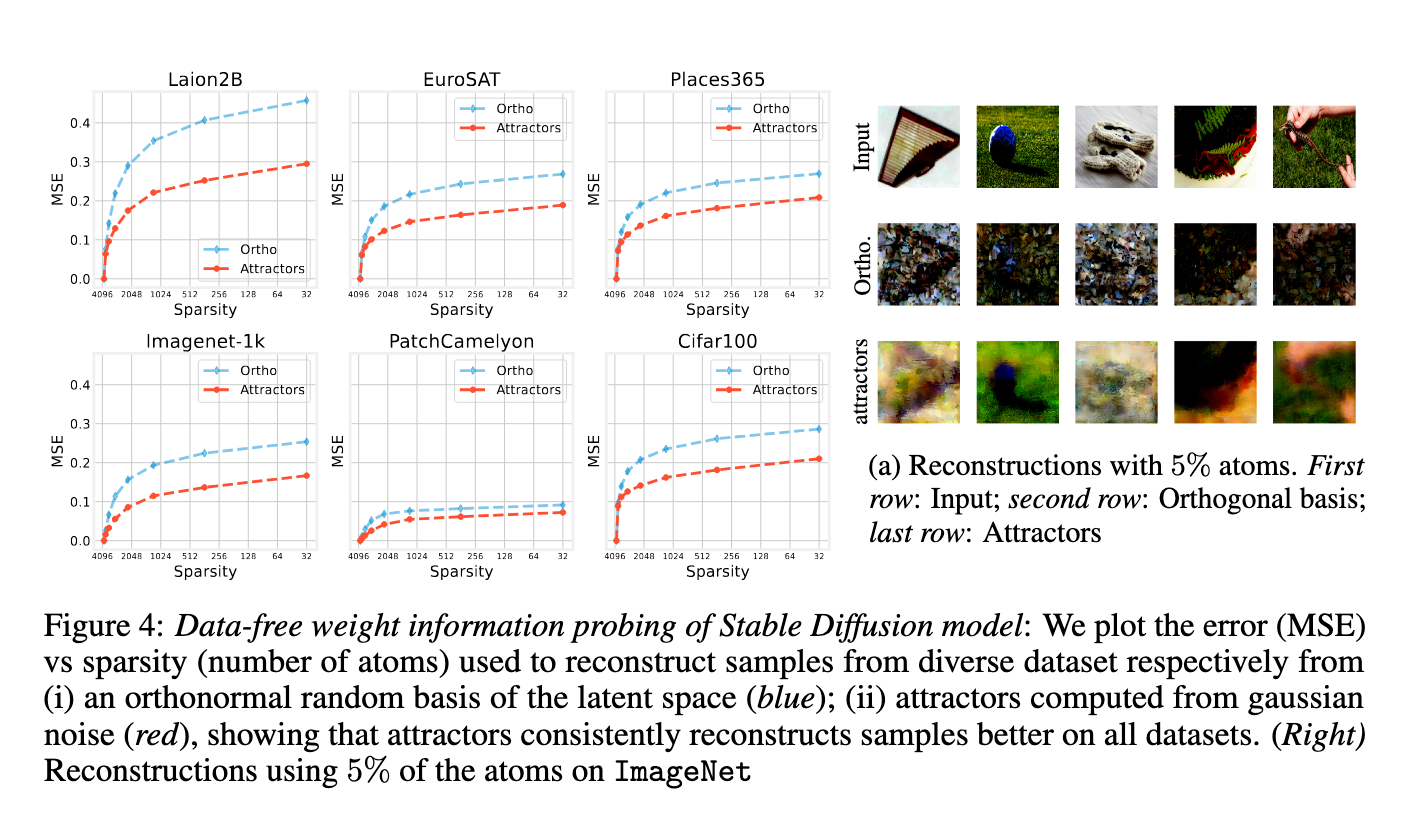
Performance tests have shown that this gravity codes the main characteristics of the behavior of the model. When the AES tafphic training on MNIST, CIFAR10 and FashionMnist, it was found that the dimensions of the low bottle (2 to 16) dimensions led to high memorization transactions above 0.8, while the higher dimensions support the circular by reducing test errors. The number of attractions increased with the number of training age, starting from one and stability with the progress of training. Upon investigation of the pre -vision institution on Laion2B, the researchers rebuked data from six various data groups using the attracted from the goat noise. In 5 % harshly, construction was much better than those in a random orthogonal basis. The medium Spring error was constantly less, indicating that the attractors form a compressed and effective dictionary.
Importance: Form Explanation of Interpretation
This work highlights a new and strong way to inspect how to store nervous models and use information. The researchers from IST Austria and Sapienza revealed that those who are attracted within the inherent vector fields provide a clear window in the model’s ability to generalize or save. Their results show that even without input data, the inherent dynamics can reveal the structure and restrictions of complex models. This tool can greatly help develop interpretative and powerful AI systems by revealing what these models learn and how they behave during and after training.
verify paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-18 08:37:00



