DeepReinforce Team Introduces CUDA-L1: An Automated Reinforcement Learning (RL) Framework for CUDA Optimization Unlocking 3x More Power from GPUs
Reading time: 6 minutes
I have opened artificial intelligence three times three times of graphics processing units – without human intervention. Deepreinforce team Provide a new framework called Cuda-L1 This provides an average 3.12 x acceleration Even 120 x rush to the peak Through 250 GPU tasks in the real world. This is not just an academic promise: each result can be reproduced with an open source symbol, on the widely used NVIDIA devices.
Horization: Learn to reinforce the contrast (contrast)
In the heart of Cuda-L1 lies a big leap in the learning strategy Amnesty International: Learning to reinforce contrast (contrast) RL. Unlike the traditional RL, AI simply creates solutions, receives digital bonuses, and its model parameters are blindly, reserve-rl The scores of performance and previous variables feed directly in the next generation router.
- Performance and symbol variables are offered to artificial intelligence In every improvement round.
- Then the model must Write “performance analysis” in the natural language– Any code was broken faster, WhyWhat are the strategies that led to this acceleration.
- Every step that forces complex thinkingDirecting the model to synthesize is not just a new symbol variable but it is a more generally generalized mental model that makes the Cuda code fast.
The result? artificial intelligence Not only does he discover known improvementsBut also Uninterrupted tricks Human experts are even ignored – including sports shortcuts that completely go beyond the account, or memory strategies set for specific devices.

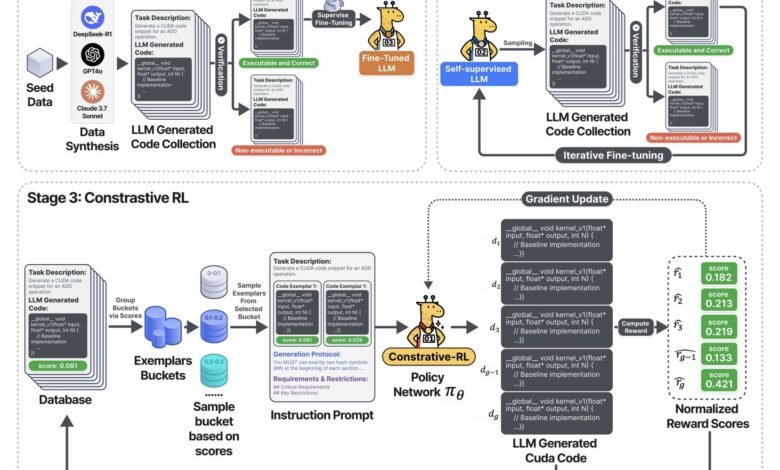
The above chart is captured Training pipeline from three stages:
- Stage 1: LLM was set using the verified Cuda code-collected by taking samples from the leading foundation models (Deepseek-R1, GPT-4O, Claude, etc.), but keeping the correct and implementable outputs only.
- Stage 2: The model is entered into a self -trained ring: it generates a lot of Cuda code, not only maintains functionality, and is used for learning. The result: a rapid improvement in the health of the code and coverage – all without placing manual signs.
- Stage 3: in The contrast phase rlThe system determines multiple symbol variables, and each of them appears with its measuring speed, and challenges artificial intelligence to discuss, analyze and overcome previous generations before producing the next round of improvements. This reversal and improvement ring is the main budget wheel that provides huge speeds.
How quality is Cuda-L1? Difficulty data
Hurry up in all fields
kernelbench-The Standard Standard for GPG code (250 pytorch works in the real world)-CUDA-L1 measurement:
| Model/stage | middle. acceleration | The maximum speed | middle | Success rate |
|---|---|---|---|---|
| Vanilla Lama -3.1-405 B | 0.23 x | 3.14 x | 0 x | 68/250 |
| Deepseek-R1 (RL Tune) | 1.41 x | 44.2 x | 1.17 x | 248/250 |
| Cuda-L1 (all stages) | 3.12 x | 120 x | 1.42 x | 249/250 |
- 3.12 x average accelerationArtificial intelligence has found improvements in almost every task.
- 120 x maximum acceleration: Some of the ineffective computers and symbols (such as the complications of the Qatari matrix) have been transformed with mainly superior solutions.
- Works across devicesWheel symbols on NVIDIA A100 GPU preserved Great gains It was transferred to another structure (L40, H100, RTX 3090, H20), with moderate speeds of 2.37 x to 3.12 xThe average gains are constantly higher than 1.1 x across all devices.
Case Study: Discovering 64 x and 120 x hidden
Diag (a) * B – Matrix beating with Qatari
- Reference (inaccurate):
torch.diag(A) @ BIt builds a complete Qatari matrix, which requires O (N²m) account/memory. - Cuda-L1 improved:
A.unsqueeze(1) * BIt requires broadcasting, and complexing O (NM) only –This led to the acceleration of 64 x. - WhyAmnesty International has preceded that a complete Qatari allocation was unnecessary; This insight was unparalleled through the brute force mutation, but it appeared through a comparative reflection through the created solutions.
3D transfer – 12 x faster
- The original code: Full wrapping, assembly, and activation – even when the input or excessive excessive sporty is guaranteed to all zeros.
- The optimal code: Use the “short sports circle”-the given is appointed
min_value=0The output can be adjusted immediately on scratch, Except each account and allocate memory. This one vision is delivered Size orders Speed up more than accurate improvements at the level of the devices.
Work effect: Why is this concern
For business leaders
- Direct cost savings: Each speed speed in GPU’s work burden translates into 1 % less than the cloud gpusecons, low energy costs, and more typical productivity. Here, I delivered artificial intelligence, on average, More than 200 % additional account of the same investment in the devices.
- Product courses fasterAutomated improvement reduces the need for Cuda experts. The teams can open performance gains in hours, not months, focus on features and search speed instead of adjusting the low level.
For artificial intelligence practitioners
- It can be verified, open source: All improved cuda 250 open beads. You can test the speed gains yourself via A100, H100, L40 or 3090 graphics processing units – there is no required confidence.
- Black magic is not requiredThe process does not depend on the secret sauce, the royal translators, or the control of the human in the episode.
For artificial intelligence researchers
- Logic schemeContrastive-RL provides a new approach to training artificial intelligence in areas where right and performance-not just a natural language-.
- PiracyThe authors divert how artificial intelligence discovered hidden exploits and “cheating” (such as treating the simultaneous flow of wrong speeds) and clarifying strong procedures to detect and prevent this behavior.
Technical visions: Why does the contrast win RL
- Performance notes now in the contextUnlike Vanilla RL, you can learn artificial intelligence not only by experimenting and error, but by Logical Self -logical.
- Self -improving budget wheelThe reversal episode makes the model strong to reward games and outperform both the evolutionary approach (the fixed parameter, and the learning of contrast within the context) and the traditional RL (blind political gradient).
- It depends and discovers the basic principlesAI can combine the main improvement strategies, their ranks and their application such as charcoal in memory, formation of interconnection indicators, fusion of operation, reusing common memory, discounts at the level of distorted, and sporty par …
Table: The higher techniques discovered by Cuda-L1
| Improvement technique | Typical acceleration | An example of vision |
|---|---|---|
| Improving memory layout | Consistent reinforcements | Memory/storage adjacent to the efficiency of cache |
| Memory arrival (coalscing, joint) | Moderate to high | It avoids banking disputes, and increases the supply of the frequency range |
| Footage process | High w/ operating pipelines | A multi -Ob core fused from the readings/writing memory |
| Sports short circle | Very high (10-100 x) | It is discovered when the account can be completely skipped |
| Topic block/parallel training | moderate | The sizes/forms of sizes are adapted to the devices/task |
| Discounts at the level of Al -Shawahi/without a branch | moderate | Reduces the difference and coincides with synchronization |
| Registration/improvement of common memory | High moderate | Table storage memory repeated data close to the account |
| Intellectual implementation, minimal synchronization | Different | I/O interferes, and can calculate pipes |
Conclusion: Amnesty International is now its improvement engineer
With Cuda-L1, his artificial intelligence Be his performance engineerAccelerate research productivity and return devices – without relying on rare human experience. The result is not just higher, but planned artificial intelligence systems They teach themselves how to harness the full potential of the devices they work on.
Artificial intelligence is now building its budget wheel: more efficient, more insightful, and more able to increase the resources we offer to them – for science, industry and beyond.
verify paperand Symbols and Project page. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-08-03 05:56:00