Hugging Face Releases SmolLM3: A 3B Long-Context, Multilingual Reasoning Model
The embraced face was just released Smollm3The latest version of its “SMOL” models, designed to provide a strong multi -language thinking on long contexts using 3B structure 3B. Although most models capable of high context usually exceed 7B parameters, SMOLLM3 managed to provide the latest performance (SOTA) with much lower parameters-which makes them more costly efficient and viable on restricted devices, without compromising the capabilities of using tools, and diversifying the multi-step language.
Smallm3 overview
Smallm3 is highlighted Model and multi -language language model and long mode long mode Creating the sequences even 128k codes. He was trained on 11 trillion symbolPut it competitive against models such as Mistral, Llama 2 and Falcon. Despite its size, SMOLLM3 is amazingly strong in the use of tools and a few thinking on the shot-cars more commonly associated with double or three times.
SMOLLM3 has been released in two types:
Both models are available to the public under APache 2.0 license on Huging’s Model Hub.
Main features
1. Long context thinking (up to 128 kilos) symbols)
SMOLLM3 uses a modified attention mechanism to address very long contexts – raising efficiency. 128,000 symbols. This ability is decisive to tasks that include documents, records or organized records, as the length of context directly affects understanding and accuracy.
2. Thinking of dual mode
Support SMOLLM3-3B Instructions Thinking bilateral:
- Tracking instructions For tasks, such as chatting and tasks that are prepared for tools.
- Multi -language quality guarantee and generation For multiple languages.
This branching allows the model to excel in both the open generation and organized thinking, which makes it suitable for applications ranging from rag pipelines to the functioning of the agent.
3. Multi -language capabilities
Training on a multi -language collection, SMOLLM3 supports six languages: English, French, Spanish, German, Italian and Portuguese. It works well on criteria such as Xquad and MGSM, which indicates its ability to generalize across the linguistic border with the minimum level of performance.
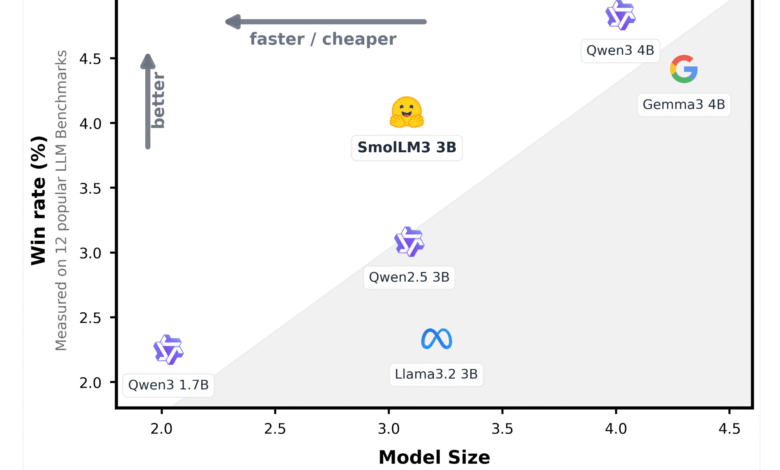
4. Compressed volume with SOTA performance
In the fair 3 billion teachersSMOLLM3 achieves performance near or equally with larger models such as Mistral-7B in multiple tasks. This is possible through the scale and quality of its training data (11T codes) and careful architectural control.
5. Use structured tools and outputs
The model shows an impressive performance in tools-all of the workflow-based workflow and structured output tasks. Correctly follows the restrictions of inputs and outputs that are well -based on the scheme with systems that require inevitable behavior, such as independent factors and API -based environments.
Technical training details
SMOLLM3 has been trained in an internal mixture with embrace sponsorship, consisting of high -quality web content, symbol, academic papers, and multi -language sources. Training 11T-Token has been done using multiple scattered training strategies on GPU groups, using improvements like Flash V2 V2 for long-efficient sequence training. Tokenizer is the 128k-Taken Referees model, shared across all subsidized languages.
To support the long context, the employee’s face embraces Linear and group attention mechanisms To reduce the sophisticated complexity while maintaining performance. This model enabled dealing with context lengths up to 128,000 during training and inference – without memory bottlenecks suffering from dense transformers on this scale.
the Smollm3-3B The further seized variable was trained using the Huging Face TRLX library to comply with chat instructions, thinking tasks, and demonstrations to use tools.
Performance standards
SMOLLM3 strongly works on multi -language and logic standards:
- xquad (qa multi -language)Competitive grades in all six -letter languages.
- MGSM (Mathematics at Multi -Language School)It exceeds several models in zero sets.
- Toolqa and Multihopqa: A strong, multi -steering thinking and context’s provision appears.
- Arch and mmlu: High accuracy in the areas of logical and professional knowledge.
Although it does not exceed the latest 7B and 13B models in each standard, the SMOLLM3 performance ratio to the teacher is still one of the highest percentage in its class.

Using cases and applications
Smollm3 is especially suitable for:
- Decrease in low -cost and multi -language artificial intelligence In Chatbots, Helpdesk systems and summary documents.
- Lightweight rag and retrieval systems This benefits from understanding the long context.
- Tool agents Adherence to the scheme and summons require the inevitable tool.
- Edge deployment and private environments Where the smaller models are necessary due to the limitations of privacy of devices or data.
conclusion
Smallm3 represents a new generation of small applicable models. Its mixture of multi-language support, long-context treatment, and strong thinking-all within the fingerprint of the parameter 3B-is a big step forward in the efficiency of the model and access to it. The Huging Face version explains that with the correct training recipe and architectural design, smaller models can still provide a strong performance in the traditionally dedicated tasks for LLMS much larger.
verify Smollm3-3B-Base and Smollm3-3B-Instruct. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitterAnd YouTube And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-07-09 01:04:00