
Incorrect Answers Improve Math Reasoning? Reinforcement Learning with Verifiable Rewards (RLVR) Surprises with Qwen2.5-Math
In the treatment of natural language (NLP), RL methods, such as reinforcement learning with human comments (RLHF), were used to enhance model outputs by improving responses based on counter -feeding signals. This specific variable approach expands, enhanced learning with verified bonuses (RLVR), through the use of automatic signals, such as sporty rightness or grammatical features, such as counter -feeding, allowing to adjust language models on a large scale. RLVR is particularly interesting because it promises to enhance the capabilities of thinking models without having a large -scale human supervision. The intersection of automated comments and thinking tasks is an exciting field of research, as developers aim to discover how to learn models to cause sports, logical or structural thinking using limited supervision.
The continuous challenge of machine learning is to build models that can actually cause minimal or incomplete supervision. In tasks such as solving mathematical problems, where the correct answer may not be immediately available, researchers are struggling with how to direct the form of the form. Models often learn from the terrestrial truth data, but it is not practical to nominate vast accurate data groups, especially in thinking tasks that require understanding complex structures such as proofs or software steps. Thus, there is an open question about whether the models can learn to think if they are exposed to loud, misleading or even incorrect signals during training. This problem is important because the excessive models on ideal comments may not be well circulated when this supervision is not available, which limits their benefit in the real world scenarios.
Many current technologies aim to enhance the capabilities of thinking about models through reinforcement learning (RL), with RLVR as a major axis. Traditionally, RLVR used “earthly truth” stickers, the correct answers that were verified by humans or automatic tools, to provide rewards during training. Some methods have resulted in the relaxation of this requirement using majority voting stickers or simple -based inferring, such as the reward answers that follow a specific output pattern. Other ways have tried random rewards, providing positive signals without looking at the correctness of the answer. These methods aim to explore whether the models can learn even with the minimum directives, but they often focus on specific models, such as QWEN, which raises concerns about generalization across different structure.
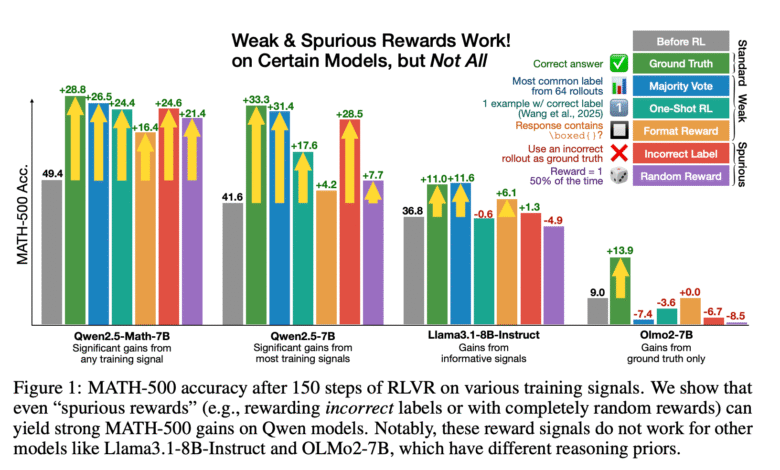
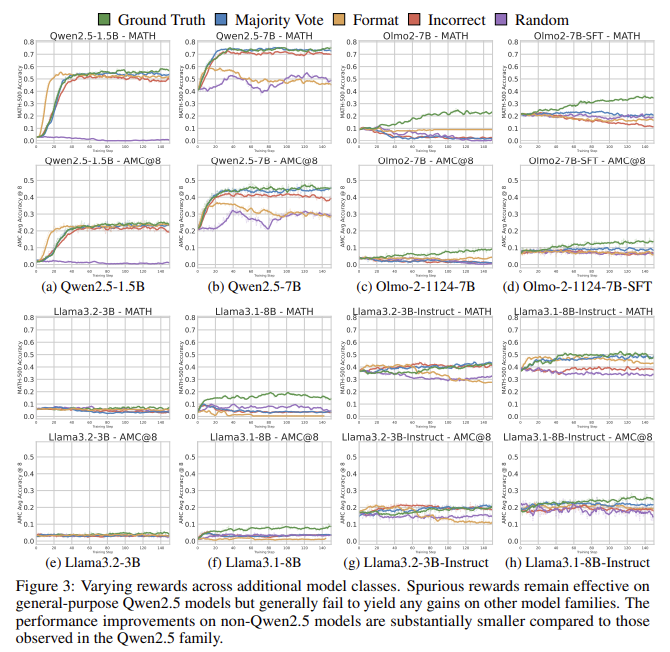
Researchers from the University of Washington, the Allen Institute in Artificial Intelligence, and UC Berkelegi are looking at this question by testing different rewards signals on QWEN2.5-Math, a family of large language models that were well seized for sports thinking. Test the bonuses of the earthly truth, the bonuses with majority voting, coordination bonuses based on bottled expressions, random rewards, and incorrect rewards. It is striking that they noticed that even completely false signals, such as random rewards and bonuses for wrong answers, can lead to great gains in performance in QWEN models. For example, QWEN2.5-Math-7B training resulted in Math-500 with ground truth bonuses from 28.8 % improvement, with incorrect stickers using 24.6 %. Random rewards still produce an increase of 21.4 %, and the coordination bonuses led to a 16.4 % improvement. The major voting bonuses provided 26.5 % accuracy. These improvements were not limited to one model; QWEN2.5-Math-1.5B also showed powerful gains: 17.6 % coordinated coordination bonuses, and incorrect signs by 24.4 %. However, the bonus strategies themselves have failed to provide similar benefits on other model families, such as Llama3 and Olmo2, which showed the minimum negative or negative changes when trained with false rewards. For example, Llama3.1-8B performance decreased to 8.5 % under certain false signals, highlighting the nature of the observed improvements.
The research team’s approach involves the use of RLVR training to adjust the models with these various rewards signals, to replace the need to supervise the truth on the ground with random or random reactions. They found that QWEN models, even without reaching the right answers, still learn how to produce high -quality thinking outputs. The main insight was that the QWEN models tend to show a distinct behavior called “thinking about the code”, which generates structured mathematics solutions such as the code, especially in snake -like formats, regardless of whether the reward signal is meaningful. This symbol thinking has become more frequent on training, increasing from 66.7 % to more than 90 % in QWEN2.5-Math-7B when training with false rewards. The answers that included code thinking showed higher accuracy rates, often about 64 %, compared to only 29 % for answers without such logical patterns. These patterns have emerged constantly, indicating that false rewards may open the underlying capabilities that were learned during training instead of introducing new thinking skills.
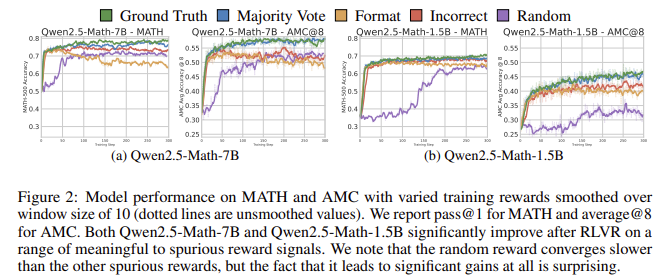
Performance data confirmed the durability of the amazing QWEN models. RAM gains (21.4 % on Math-500) and incorrect stickers (24.6 %) approximately 28.8 %. Similar trends have appeared in tasks, such as AMC, where coordination and wrong and random rewards are produced about 18 % improvement, slightly less than 25 % improvement of the earthly truth or majority bonuses. Even in Aime2024, false rewards such as coordination (+13.0 %), incorrect (+8.7 %), and random (+6.3 %) have led to meaningful gains, although the feature of the Earth’s reality stickers (+12.8 %) remained clear, especially for Aime2025 questions that were created after cutting the pre -form.
Many main meals include:
- QWEN2.5-Math-7B has gained 28.8 % accuracy on Math-500 with ground truth bonuses, but also 24.6 % with incorrect bonuses, 21.4 % with random bonuses, 16.4 % with coordination bonuses, 26.5 % with majority bonuses.
- The symbol thinking patterns appeared in QWEN models, increasing from 66.7 % to 90 %+ under RLVR, which reinforced the accuracy from 29 % to 64 %.
- Change models, such as Llama3 and Olmo2, have not appeared similar improvements, with Llama3.1-8B with 8.5 % of the performance on false rewards.
- Fakes from false signals appeared in 50 training steps in many cases, indicating a quick deduction of thinking capabilities.
- The research warns that RLVR studies should avoid generalizing results based on QWEN models alone, because the effectiveness of the false reward is not universal.
In conclusion, these results indicate that although QWEN models can take advantage of false signals to improve performance, the same thing is not true for other model families. Change models, such as Llama3 and Olmo2, showed changes in flat or negative performance when they were trained with false signals. The research emphasizes the importance of verifying the validity of RLVR methods in various models instead of relying only on the results that focus on QWEN, as many modern papers did.
Check the paper, the official version, and the Jaithb page. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 95K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-28 20:31:00



