
DeepSeek R1T2 Chimera: 200% Faster Than R1-0528 With Improved Reasoning and Compact Output
TNG Technology Consulting revealed Deepseek-TNG R1T2 Chimera, a new model for expert collection (AOE) that mixes intelligence and speed through an innovative model integration strategy. It is designed from three models of high-performance parents-R1-0528, R1 and V3-0324-R1T2 showing how expert classes on the scale can open new competencies in LLMS models.
Expert Assembly: Forming an effective model on a large scale
Traditional LLM and polishing huge mathematical resources require. This TNG is treated with an expert assembly approach (AOE), and integrating Experience models on a large scale (MEE) level at the level of weight without re -training. This strategy allows the creation of new new time models that inherit the capabilities of parents. R1T2 brown combines experts from R1 with the V3-0324 base and selectively include improvements from R1-0528, which improves barter between the cost of reasoning and the quality of thinking.
Speed gains and exhibitors of intelligence
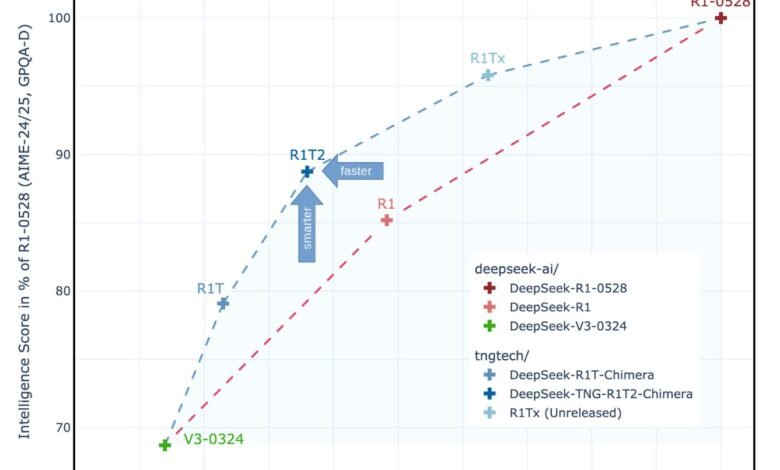
In standard comparisons, R1T2 exceeds 20 % of R1 and more than twice the R1-0528 speed. These performance gains are largely due to the low length of the distinctive symbol of the output and the integration of the selective expert tensioner. While it is just less than the R1-0528 in raw intelligence, it greatly outperforms R1 through high-level standards such as GPQA Diamond and Aime-2024/2025.
Moreover, the model maintains the effects of thinking … which only appears when the R1’s contribution to the integration of a specific threshold. This behavioral consistency is vital to applications that require step -by -step thinking.
The emerging characteristics in the teacher’s space
R1T2 confirms the results of the accompanying search paper that can combine the model into viable models throughout the completion space. Interestingly, the intelligence properties change gradually, but behavioral signs (such as consistent use) suddenly appear near the weight of 50 % R1. This indicates that some features are in distinctive sub -spaces from the LLM weight scene.
By merging the directed experts only and leaving other ingredients (for example, attention and shared mlps) from V3-0324 intact, R1T2 maintains a high level of thinking while avoiding action. This design leads to what TNG calls “consistency of thought”, which is a behavioral feature where not only the thinking is accurate, but also brief.
Early discussions of the Reddit Localllama community highlighting the practical impressions of R1T2. Users praise the form of the form, the efficiency of the distinctive symbol, and the balance between speed and cohesion. Note one of the users, “It is the first time that the Chimera felt like a real upgrade at both speed and quality.” Another indicated that he works better in heavy contexts in mathematics compared to previous R1 variables.
A few Redditors note that R1T2 displays a more anchoring personality, and avoid hallucinations more consistently than the R1 or V3 models. These emerging features are especially related to developers looking for a stable LLM background for production environments.
Open weights and availability
R1T2 is available to the public under the Massachusetts Institute of Technology in the face of embrace: Deepseek-tNG R1T2 Chimera. The version encourages the experimentation of society, including refining the final course and learning to reinforcement. According to TNG, internal publishing operations via the inferition platform without Chues make up approximately 5 billion symbols per day.

conclusion
Deepseek-tNG R1T2 Chimera displays the possibilities of building experts to generate LLMS performance and efficiency without the need for gradient-based training. Through the strategic combination between the possibilities of thinking in R1, the distinctive distinctive design of the V3-0324, and the improvements from R1-0528, R1T2 defines a new standard for the balanced model design. Its open -weight issuance under the Massachusetts Institute of Technology license ensures access, making it a strong candidate for developers looking for fast, capable and customized large language models.
With the combination of an applicable model even on the lexical 671b scale, the R1T2 of TNG may be a plan for future experiences in the teacher’s space fulfillment, allowing the development of LLM the most unit and interpretation.
verify Paper and weights open in the embraced face. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.

Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-07-03 11:39:00



