
Kyutai Releases 2B Parameter Streaming Text-to-Speech TTS with 220ms Latency and 2.5M Hours of Training
Kyutai, an Amnesty International Open Lab, has released a major model for broadcasting in TTS with about a billion teachers. This model is designed to respond in the actual time, and provides a very devastating sound generation (220 mm) while maintaining high sincerity. It is trained on unprecedented 2.5 million hours of sound and is licensed under CC -By-4-4.0 allowed, which enhances Kyotai’s commitment to openness and reproduction. This progress re -defining the efficiency and accessibility of large -scale speech generation models, especially to spread the edge and AI Agenic.
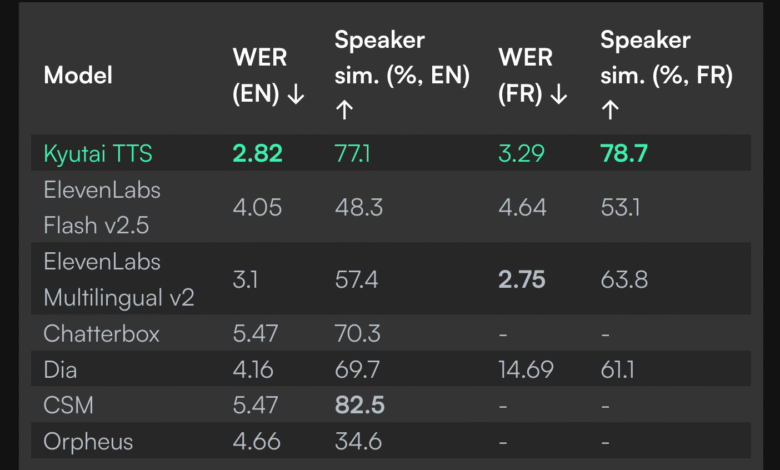
Performance empty
The ability of the model flow is a more distinctive feature. On the single NVIDIA L40 graphics unit, the system can serve up to 32 simultaneous users while maintaining cumin below 350 mm seconds. For individual use, the model maintains the time of the transmission of a generation of up to 220 mm, which allows almost actual time applications such as conversation agents, sound aides and live narrative systems. This performance is enabled by the late modeling approach in Kyutai’s novel, which allows the model to gradually create speech with the arrival of the text.
Main technical standards:
- Form size: ~ 2B teachers
- Training data: 2.5 million hours of speech
- cumin: 220MS user, <350MS with 32 users on the one L40 graphics processing unit
- Language SupportEnglish and French
- license: CC -By-4.0 (Open Source)
Modeling delay: actual time response education
Kyutai’s innovation is installed in the modeling of late tables, which is a technique that allows the synthesis of speech before the full input text is available. This approach is specifically designed to balance the quality of prediction with the response speed, allowing the highly productive TTS TTS. Unlike the traditional automatic models that suffer from the delay in response, this structure maintains temporal cohesion while achieving a faster synthesis than time.
CodeBase and Trarain recipe for this architecture is available at the GitHub warehouse in Kyutai, which supports complete reproduction and societal contributions.
Availability of open research form and commitment
Kyutai has released typical weights and embrace inference texts, making it accessible to researchers, developers and commercial teams. The CC-Dy-4-44 license is allowed to adapt and integrate unrestricted in applications, provided that the appropriate support is maintained.
This version supports both impossibility and broadcasting, making it a multi -use basis for sound cloning, actual time chat tools, access to tools, and more. With pre -models in English and French, Kyutai paves the way for multi -language TTS tubes.
The effects of artificial intelligence applications in real time
By reducing the time of the transition of speech to 200MS, the Kyutai model narrows the human delay of human intent and speech, which makes it viable:
- Artificial intelligence conversationHuman -like audio facades with a low shift
- Auxiliary technologyReaders of the screen faster and audio feedback systems
- Media production: Audio with rapid repetition courses
- Edge devices: The optimum inference of low energy environments or the device
The ability to serve 32 users on the one L40 graphics processing unit without quality deterioration makes it attractive to expanding speech services efficiently in cloud environments.
Conclusion: open, fast and ready to publish
The Kyutai TTS version is a milestone in AI. Thanks to high -quality synthesis, actual time cumin, and generous licensing, it addresses the important needs of both researchers and product teams in the real world. The reproduction of the model, the multi -language support, and the developmentable performance makes it a prominent alternative to property solutions.
For more details, you can explore the formal model card, the technical interpretation of the Kyutai website, and the implementation details on GitHub.
SANA Hassan, consultant coach at Marktechpost and a double -class student in Iit Madras, is excited to apply technology and AI to face challenges in the real world. With great interest in solving practical problems, it brings a new perspective to the intersection of artificial intelligence and real life solutions.
 streaming-Text-to-Speech-TTS-with-220ms-Latency.png" alt=""/>
streaming-Text-to-Speech-TTS-with-220ms-Latency.png" alt=""/>Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-05 08:24:00



