LLMs Can Now Reason in Parallel: UC Berkeley and UCSF Researchers Introduce Adaptive Parallel Reasoning to Scale Inference Efficiently Without Exceeding Context Windows
LLMS models have made great steps in thinking possibilities, which were embodied by penetration systems such as Openai O1 and Deepseekr1, which use test time calculation to learn research and reinforcement to improve performance. Despite this progress, current methodologies face critical challenges that impede their effectiveness. The methods of the series generate the thought of long sequences, increased cumin and pushing against the restrictions of the context window. On the other hand, parallel methods such as the best N and self -agreed suffer from bad coordination between the paths of reasoning and lacking comprehensive improvement, which leads to mathematical inefficiency and limited improvement capabilities. Also, time research techniques such as trees, such as thought trees, depend on handmade research structures, which greatly restricts their flexibility and their ability to expand through various inference tasks and fields.
Several ways to address the mathematical challenges in thinking in LLM have emerged. The scaling methods at the time of reasoning improved the performance of the task in the direction of the river course by increasing the test time calculation, but usually generate a much longer output sequences. This creates higher time models and is forced to fit the entire thinking chains in the window of one context, which makes it difficult to attend relevant information. Parallel strategies such as the band tried to mitigate these problems by making multiple independent language model calls simultaneously. However, these methods suffer from poor coordination through parallel strands, which leads to excess account and ineffective resources. Fixed parallel thinking structures are suggested, such as tree thinking systems and multi -agent thinking, but manually designed research structures limit flexibility and expansion. Other curricula, such as pasta, decompose tasks in parallel sub -tasks, but eventually reintegrate the full context into the main reasoning path, and failed to reduce the use of context effectively. Meanwhile, Hogwell! Inference uses parallel factor threads, but it depends exclusively on the claim without improving from one side to tip.
Researchers from the University of California in Berkeley and UCSF suggested Parallel parallel thinking (April). This strong approach provides language models from distributing a dynamic inference account across both serial and budget processes. This methodology generalizes the existing thinking curricula-including the series of sequences, the thought, and the inference parallel with self-consistency, and organized research-through training forms to determine when and how to paralleon the inferences instead of imposing fixed research structures. APR provides major innovations: a mechanism for parenting and child interconnection and improves learning reinforcement from comprehensive to finish. The interconnection mechanism provides indicators of the interconnectedness of the inference parents to delegate sub -tasks to the multiple children’s threads through the process of spawning (), which allows the parallel exploration to the distinctive thinking paths. The children’s threads then return the results of the assets interconnection through the Join () process, allowing the father to continue to decipher this new information. Built on the SGLANG model framework, APR dramatically reduces the actual time arrival time by performing inferring in children’s threads simultaneously through inclusion. The second-ranching innovation of pressure through a comprehensive reinforcement learning-determines the success of the task in general without the need for pre-defined thinking structures. This approach provides three important advantages: higher performance within fixed context windows, superior scaling with increased account budgets, and improving performance in equivalent cumin compared to traditional methods.
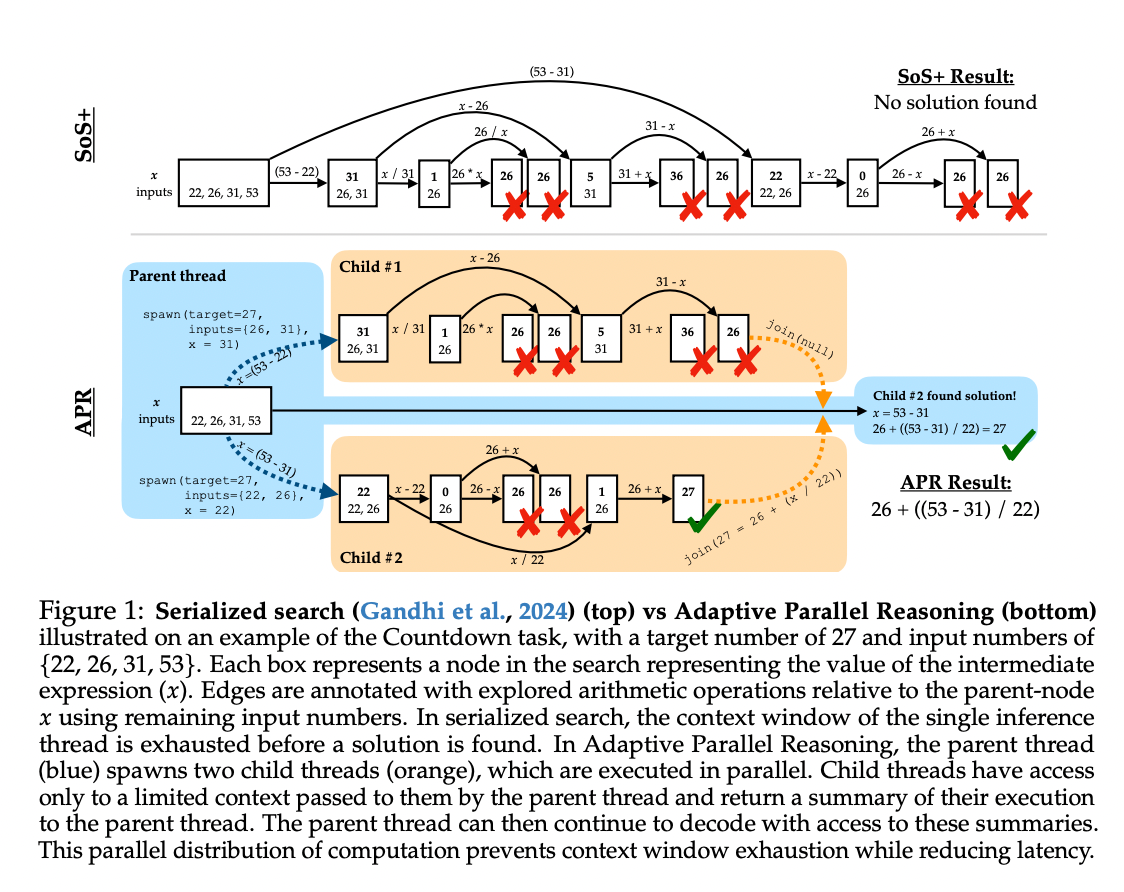
The APR structure is carried out by a multi -threaded mechanism that enables language models to organize a dynamically parallel inference. APR addresses the restrictions of the thinking methods by distributing the account through parents ’interconnected indicators, which reduces cumin while improving performance in context restrictions. Architecture consists of three main components:

Firstly , The multi -yarch inference system The origins of the origin are allowed to empty multiple children’s threads using the MSGS process. Each indicator of the interconnection of a child receives a distinguished context and implements the inference independently, but simultaneously using the language model itself. When the child’s interconnection index completes its mission, it restores the results to the parent through the Join (MSG) process, and it selectively continues only the most relevant information. This approach greatly reduces the use of the distinctive symbol by maintaining the effects of intermediate research confined to the baby’s threads.
secondly , Training methodology It uses two phase approaches. Initially, the APR uses the learning subject to supervision with automatic illustrations that include the first and first -depth search strategies, creating mixed search patterns. Syldic Solver creates demonstrations with parallel, analyzing searches in multiple ingredients that avoid the window of context window during training and inference.
Finally, the system is implemented Improving reinforcement reinforcement With GRPO (improvement policy improved). During this stage, the model learns to determine when and how widely to call children’s strands, improve mathematical efficiency and effectiveness. The model repeats the effects of thinking, evaluates its health, and adjusts the parameters accordingly, in the end, learning to balance the parallel exploration with the restrictions of the context window to achieve maximum performance.

Compare the evaluation parallel logic adaptive with the methods of thinking series series, discharge and self -consistency using only the Mosskha language model with 228 meters built on Llama2 structure and support for a window of 4,096. All models are prepared through learning subject to supervising 500,000 tracks of symbolic solutions. To evaluate the direct account, the team implemented the budget restrictions method with the air conditioning of the context of the SOS+ models and the adaptation of the number of interconnected indicators of APR models. The Sglang frame was used for reasoning due to its support for continuous assembly and Radix attention, allowing effective APR.
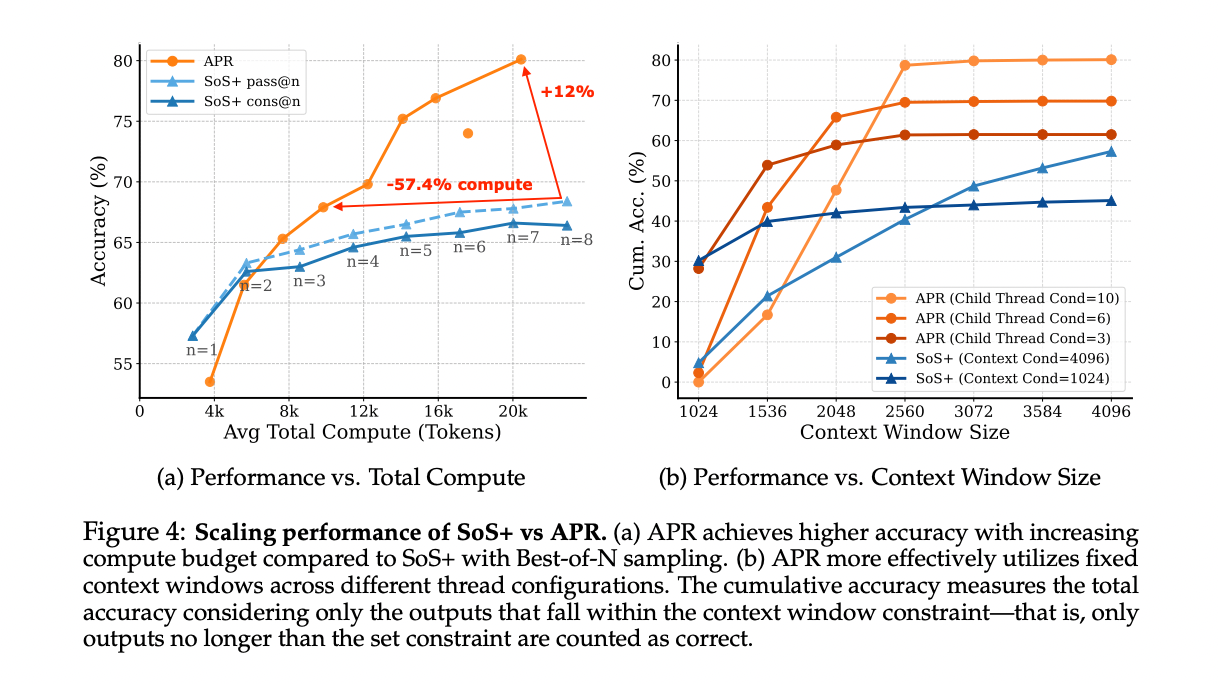
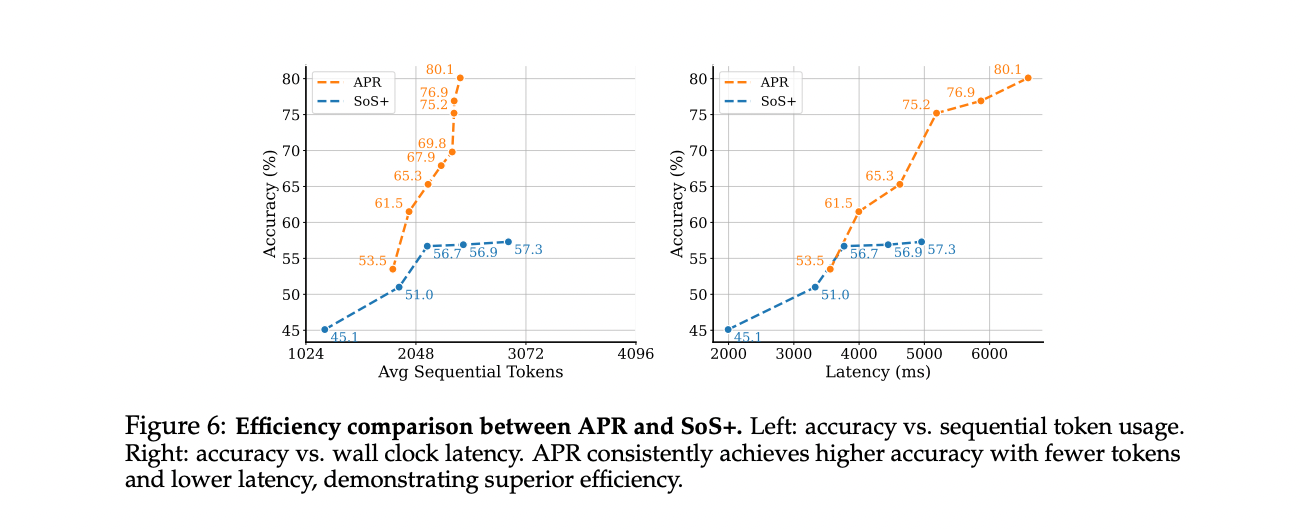
Experimental results show that APR is constantly outperforming serial methods in multiple dimensions. When expanding with a higher account, the APR initially has set up in low computer systems due to parallel public expenditures but greatly outperforms SOS+ with an increase in the account account, which achieves an improvement of 13.5 % at 20 thousand codes and exceeds the performance of SOS+@8 with use of 57.4 % less. For the expansion of the window of context, APR is more efficiently exploited, as 10 indicators have reached about 20 % higher accuracy by 20 % in the maximum 4K by distributing thinking through parallel interconnection indicators instead of containing complete effects within one context window.
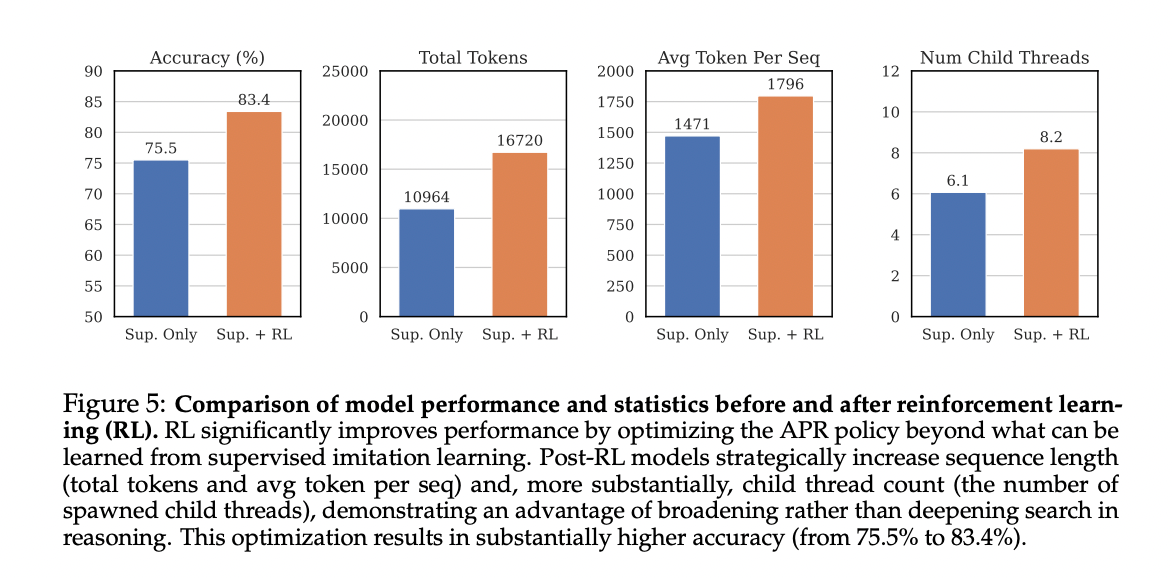
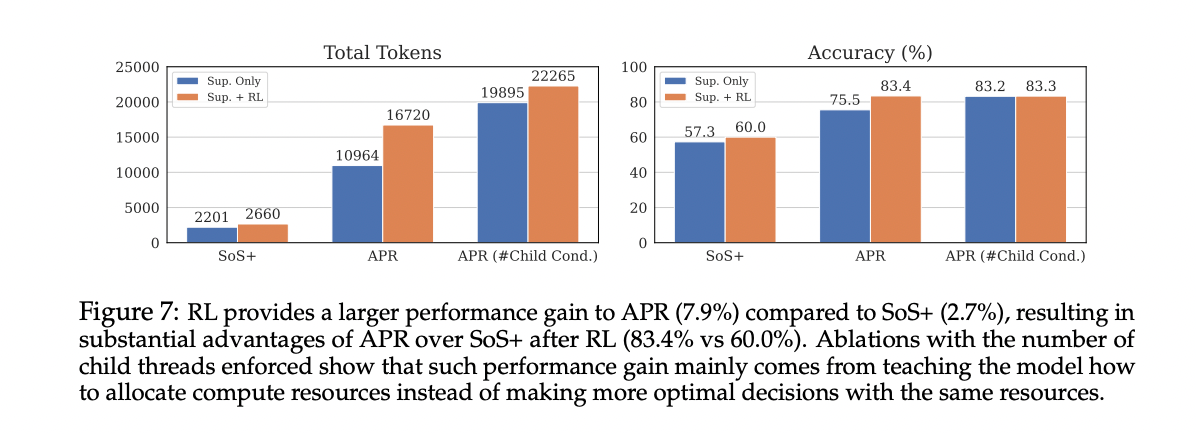
The learning to the tip to the tip significantly enhance the performance of APR, which enhances the accuracy from 75.5 % to 83.4 %. RL models show significantly different behaviors, which increases the length of the sequence (relative increase 22.1 %) and the number of children’s threads (34.4 % relative increase). This reveals that, for the count of countdown, the RL improved models prefer a wider research patterns over deeper patterns, indicating the ability of the algorithm to discover optimal research strategies independently.
APR shows an extreme efficiency in both theoretical and practical assessments. When measuring the use of the distinctive serial symbol, APR greatly enhances accuracy with the minimum additional serial symbols that exceed 2048, rarely exceeding 2500 symbols, while SOS+ only shows marginal improvements despite the approach of 3000 symbols. The real world’s cumin test is revealed on the 8-GPU, APR is largely better, with a large-scale accuracy, with a resolution of 75 % at 5000ms per sample-an absolute improvement of 18 % on SOS+57 %. These results shed light on the parallel of the effective APR devices and the ability to perform improvement in publishing scenarios.
Parallel parallel thinking represents a great progress in the possibilities of thinking about the language model by enabling the dynamic distribution of the account through the chain and parallel paths through the mechanism of parents ’interconnection. By combining training for supervision and augmented to one side, APR eliminates the need for manually designed structures while allowing models to develop optimal parallel strategies. Experimental results on the count of countdown APR are large: the highest performance within fixed context windows, superior expansion with increased account budgets, and significantly improving success rates in equivalent cumin restrictions. These achievements highlight the potential of thinking systems that stimulate the dynamic inferences to achieve the ability to expand and enhance the tasks of solving complex problems.
verify paper. Also, do not forget to follow us twitter And join us Telegram channel and LinkedIn GrOup. Don’t forget to join 90k+ ml subreddit. For promotion and partnerships, Please talk to us.
🔥 [Register Now] The virtual Minicon Conference on Agency AI: Free Registration + attendance Certificate + 4 hours short (May 21, 9 am- Pacific time)
Asjad is a trained consultant at Marktechpost. It is applied for BT in Mechanical Engineering at the Indian Institute of Technology, Kharjbour. ASJAD is lovers of machine learning and deep learning that always looks for automatic learning applications in health care.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-05-03 06:00:00