
Meta AI Introduces Perception Encoder: A Large-Scale Vision Encoder that Excels Across Several Vision Tasks for Images and Video

The challenge of designing vision symbols for general purposes
As artificial intelligence systems grow increasingly, the role of visual perception models becomes more complicated. The vision encoders are expected to recognize not only to identify organisms and viewers, but also to support tasks such as the illustrations, answer questions, carefully identify, analyze documents, and spatial thinking through both images and videos. Current models usually depend on various goals before training-diverse learning for retrieval, commenting on linguistic tasks, and methods that are self-supervised for spatial understanding. This retail holds the ability to expand and spread the form, and provides barters in tasks.
What still represents a major challenge is a unified vision encoding design that can match or overcome the task methods, and it works strongly in the world’s open world scenarios, and expand efficiently through methods.
AI-s-perception-encoder">Unified solution: Meta AI visualization
Meta AI offers Evolutionary perception (PE)The vision model family has been trained to use one goal that contradicts the language of vision and refinement with the techniques of alignment specifically designed for the estuary tasks. PE is launched from the pre -traditional multi -lead model. Instead, he explains that through a carefully controlled training recipe and appropriate alignment methods, contradictory learning alone can lead to highly generalized visual representations.
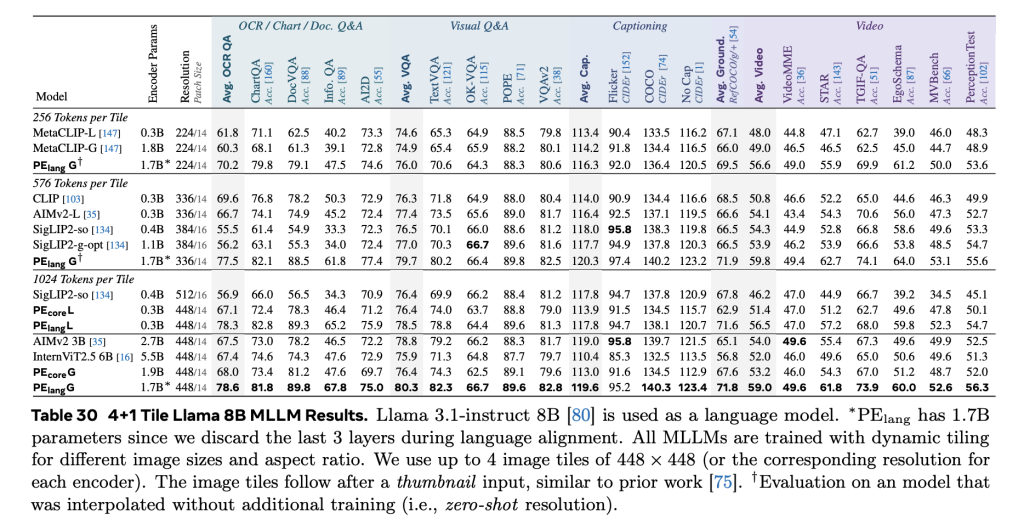
Craving works over three Mawazer PECOREB, Pecorel and Pecoreg-with the largest G-Scale model that contains 2B parameters. These models are designed to act as overall purposes for each of the introduction of images and videos, providing strong performance in classification, retrieval and multimedia thinking.
Training and architecture approach
PE training follows a two -stage process. The first stage includes a strong contradictory learning on a wide sponsorship text data collection (5.4B pairs), with many architectural improvements and training to improve both accuracy and durability. This gradual scaling includes accuracy, large batch sizes (up to 131 kb), the use of the sheep, the topical coding of the two -dimensional, increased control, and persuasive organization.
The second stage is presented to understand the video through the benefit Video data engine This connects high -quality video text pairs. This pipeline includes illustrations of the perception language model (PLM), descriptions at the frame level, and descriptive data, which are then summarized using Llama 3.3. These synthetic illustrations allow the image encryption of the same video tasks to be adjusted via the average frame.
Although one contradictory goal is used, PE features representations for general purposes distributed across intermediate layers. To reach this, Meta offers two alignment strategies:
- Language alignment For tasks such as answering visual and naming questions.
- Spatial alignment To detect, track, and appreciate depth, using self -monotheism and distillation of spatial correspondence via Sam2.
Experimental performance across methods
PE shows a strong grade circular through a wide range of vision standards. In the classification of photos, Pecoreg matches or exceeds the ownership models trained to large private data collections such as JFT-3B. Achieve:
- 86.6 % On imagenet-val,
- 92.6 % On imagenet-adversarial,
- 88.2 % On the entire set of objects,
- Competitive results on accurate granules data collections including non -resume, Food101 and Oxford.
In video tasks, PE achieves modern performance on zero classification and retrieval standards, outperforms internal performance 2 and Siglip2-G-Opt, while they are trained at 22 meters of synthetic video piston pairs. The use of simple intermediate assembly through the tires-from chronological interest-puts that the architectural simplicity, when it is well associated with alignment training data, can still have high-quality video representations.
The eradication study shows that each component of video data engine components contributes to a useful performance. +3.9 % improve in classification and +11.1 % in restoring the foundation lines only the image only highlights the benefit of artificial video data, even on a modest scale.
conclusion
ENPROCEPT ENCODER provides a technically convincing demonstration that a single contrast goal, if carefully implemented and packed with thoughtful alignment strategies, is sufficient to build vision symbols for general purposes. PE only matches the specialized models in their fields, but they do so with a unified and developmental approach.
The PE version, along with the Codebase database and the PE video data collection, provides a repetitive and effective research community. As optical thinking tasks grow in complexity and scope, PE provides a way forward towards a more integrated and powerful optical understanding.
verify Paper, model, symbol and data collection. Also, do not forget to follow us twitter And join us Telegram channel and LinkedIn GrOup. Don’t forget to join 90k+ ml subreddit.
🔥 [Register Now] The virtual Minicon Conference on Agency AI: Free Registration + attendance Certificate + 4 hours short (May 21, 9 am- Pacific time)
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-04-18 15:23:00



