
MiniMax AI Releases MiniMax-M1: A 456B Parameter Hybrid Model for Long-Context and Reinforcement Learning RL Tasks

AI-models">Challenge long thinking in artificial intelligence models
Big thinking models are not only designed to understand the language, but they are also organized to think through multi -step processes that require long attention and understanding context. With the growth of expectations from artificial intelligence, especially in the environmental development environments and software, the researchers sought brown that can deal with longer inputs and maintain deep coherent thinking chains without overwhelming calculations.
Accounty restrictions with traditional transformers
The basic difficulty lies in expanding these thinking capabilities in excessive arithmetic load that comes with longer generation lengths. Traditional models based on transformers are used as a SoftMax attention mechanism, which is firm with the input size. This limits its ability to deal with the long input sequence or the intense intended thought chains. This problem becomes more urgent in areas that require actual time interaction or cost -sensitive applications, as infinite expenses are important.
Current alternatives and restrictions
Efforts to address this issue have resulted in a set of methods, including sporadic attention and linear attention variables. Some teams have tried state space models and frequent networks as alternatives to traditional attention structures. However, these innovations have seen a limited adoption in the most competitive thinking models due to architectural complexity or the inability to expand in the real world. Even large-scale systems, such as Tencent’s Hunyuan-T1, which uses the new MAMBA structure, remains closed source, thus restricting research participation and wider validation.
Minimax-M1 input: Open Development Form
The researchers at Minimax Ai Minimax-M1 presented a new model to open on a large scale, combining a combination of architectural engineering experts with rapid attention. Minimax-M1 is designed as a development of the Minimax-Text-01 model, and contains 456 billion teachers, with 45.9 billion of the distinctive symbol. It supports context lengths of up to one million symbols – eight times the Deepseek R1 capacity. This model treats expansion at the time of reasoning, and consumes only 25 % of the fluctuations required by Deepsek R1 with a length of 100,000 of the distinctive symbol. It was trained using a wide range of reinforcement on a wide range of tasks, from mathematics and coding to software engineering, which represents a shift towards AI’s practical models.
Hybrid attention with lightning attention and SoftMax blocks
To improve this architecture, Minimax-M1 uses a hybrid diagram as each seventh transformer mass uses a traditional SoftMax, followed by six blocks using lightning attention. This greatly reduces arithmetic complexity while maintaining performance. The attention of lightning itself is I/O-Love, quoted from linear attention, and is especially effective in limiting the lengths of thinking into hundreds of thousands of symbols. In order to enhance the efficiency of learning, the researchers presented a new algorithm called CISPO. Instead of the distinctive symbol updates as traditional methods do, Cispo cuts weights to the importance of samples, providing stable training and consistent symbolic contributions, even in updates outside of quality.
Cispo algorithm and RL training efficiency
Cispo algorithm is necessary to overcome the instability of the training facing hybrid structures. In comparative studies using the QWEN2.5-32B foundation, CISPO achieved 2x acceleration compared to DAPO. Take advantage of this, the fully enhanced learning course for Minimax-M1 has been completed in only three weeks using 512 H800 GPU, at a rental cost of about $ 534,700. The model has been trained in a variety of data collection that includes 41 logical tasks created through the Synlogic framework and software engineering environments in the real world derived from the SWE seat. These environments used implementation bonuses to direct performance, which led to stronger results in practical coding tasks.
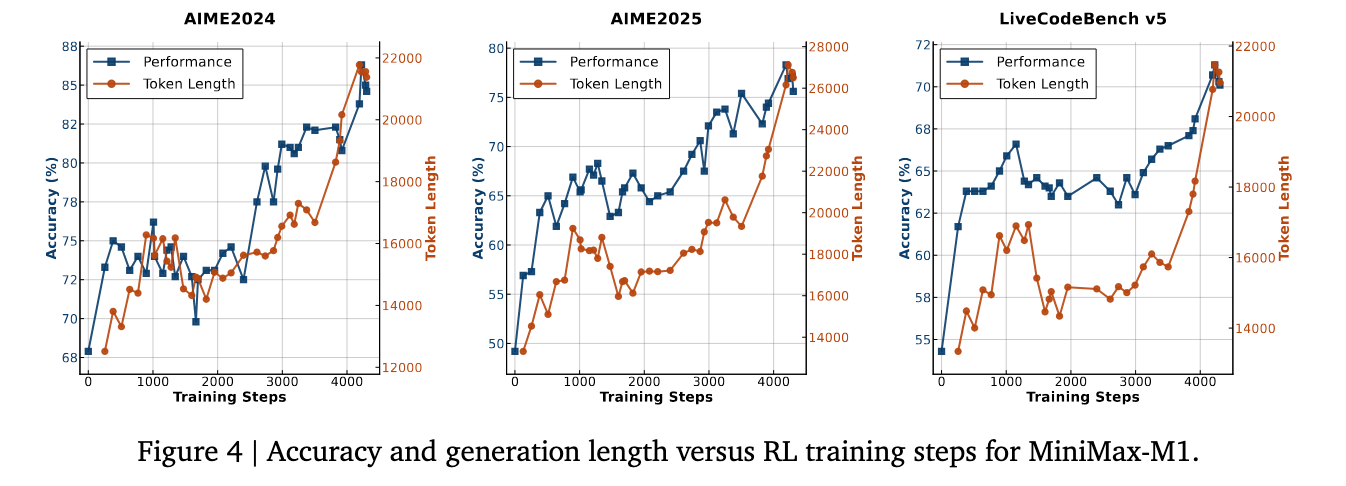
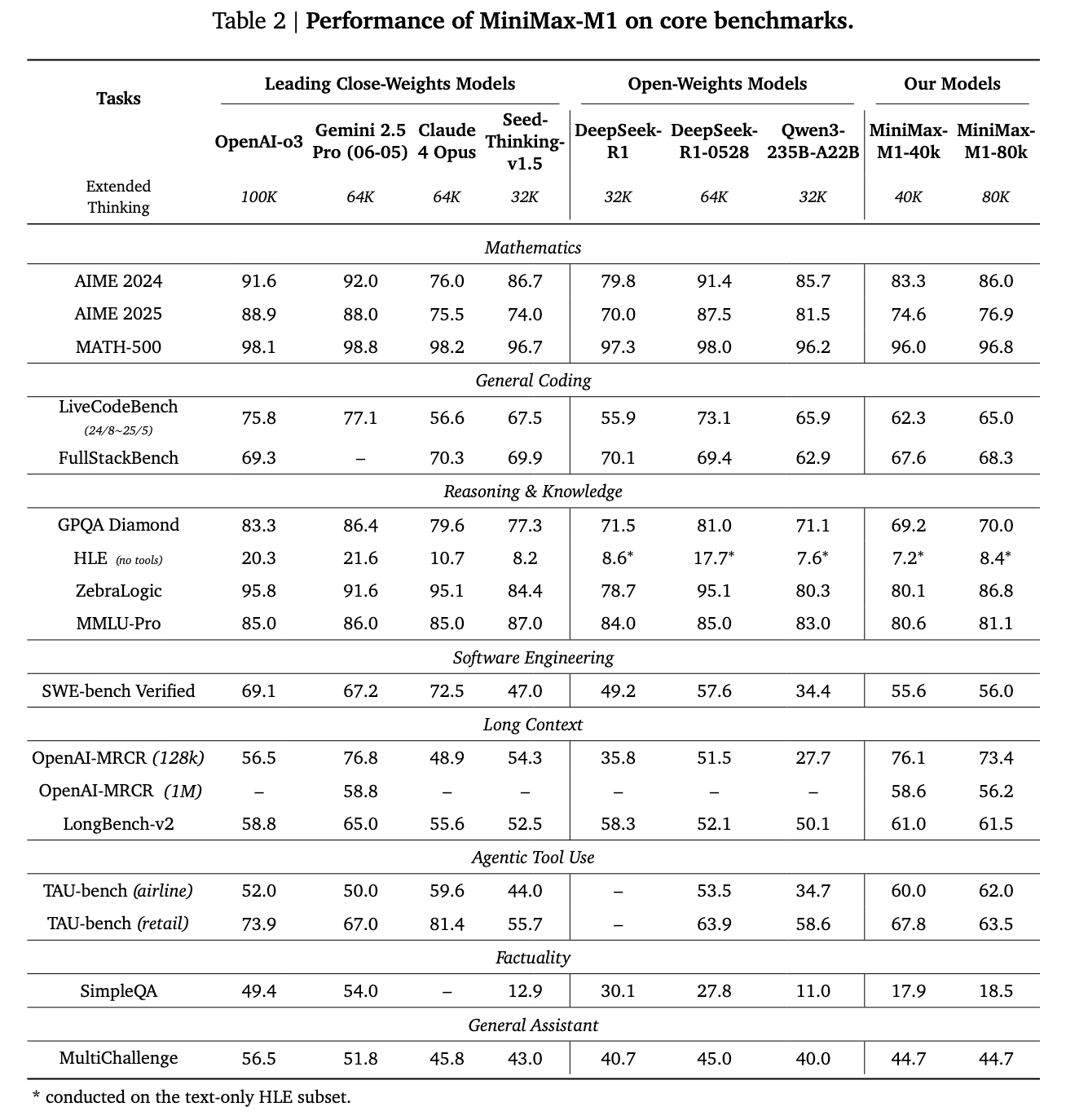
Standard results and comparative performance
Minimax-M1 provided convincing retrospective results. Compared to Deepseek-R1 and QWEN3-235B, it has been distinguished in software engineering, long-context processing and the use of the agent tool. Although he is late for the latest Deepseeek-R1-0528 in mathematics and coding competitions, both Openai O3 and Claude 4 OPUS have exceeded the long-term understanding standards. Moreover, it outperformed Gueini 2.5 Pro in the Tau-Bench tool.
Conclusion: A developmental and transparent model for a long context treatment
Minimax-M1 offers a big step forward by introducing both transparency and expansion. By addressing the dual challenge of the efficiency of reasoning and complexity of training, the Minimax AI team has put a precedent for open -weight thinking models. This work not only brings a solution to calculating restrictions, but also provides practical ways to expand the intelligence of the language model in the real world applications.
verify Paper paper and model and github. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-19 17:40:00



