MiniMax-M1 is a new open source model with 1M TOKEN context
Join the event that the leaders of the institutions have been trusted for nearly two decades. VB Transform combines people who build AI’s strategy for real institutions. Learn more
The Chinese company Ai Minimax, which may be known in the West, has released a realistic male video model, Hailuo, the latest large linguistic model, Minimax-M1-and in the wonderful news of institutions and developers, it is completely open source under the Apache 2.0 license, which means that companies can take them and use them for their commercial applications and amend them to dispose of them without restoring or batch.
M1 is an open -weight display that determines new criteria in long thinking in context, use the agent tool, and performing an effective account. It is today available on the Code Code Code Community Face and Microsoft Code Conducts Community GitHub, which is the first version of what the company called “Minimaxweek” from its social account on X – with the expectation of additional products ads.
Minimax-M1 distinguishes itself with a window of context of one million input symbols and up to 80,000 icons in the output, which puts it as one of the most expansion models available for long thinking tasks in the context.
The “context window” indicates in the large language models (LLMS) to the maximum number of symbols that the model can treat simultaneously – including both inputs and outputs. Symbols are the basic units of the text, which may include complete words, parts of words, numbering marks, or code symbols. These symbols are converted into digital carriers used by the model to represent the meaning through parameters (weights and biases). They are, in essence, the mother tongue llm.
For comparison, the GPT-4O of Openai has a context window of only 128,000 symbols-enough to exchange the novel information between the user and the model in one reaction back and forth. At a million icons, the minimax-m1 can exchange a small exchange group Or book series information. Google Gemini 2.5 Pro offers the upper limit for the distinctive code context of a million, also, with a two -million -millionaited window in business.
But the M1 has another trick of her possession: it has been trained using reinforcement learning in innovative, resourceful, highly efficient technology. The model is trained using a hybrid sewn (MEE) combination with lightning attention mechanism designed to reduce the costs of inference.
According to the technical report, Minimax-M1 consumes only 25 % of the floating point operations (Flops) required by Deepsek R1 with a length of 100,000 symbols.
Architecture and variables
The model comes in two types-minimax-m1-40K and minimax-m1-80K-indicating “thinking budgets” or output lengths.
Architecture is designed on the former Minimax-Text-01 company and includes 456 billion teachers, with 45.9 billion activations for each symbol.
A prominent feature of the version is the cost of training the form. Minimax reports that the M1 model was trained using a large -scale reinforcement learning (RL) efficiently seen in this field, at a total cost of $ 534,700.
This efficiency is attributed to a dedicated RL algorithm called CISPO, which cuts the weights of importance for samples instead of symbolic updates, and a hybrid attention design that helps to simplify scaling.
This is an amazing “cheap” amount for Frontier LLM, where Deepseek trained the successful R1 thinking model at a cost of an amount from it from 5 to 6 million dollars, while the cost of training Openais GPT-4-is more than two years old now-is more than $ 100 million. This cost comes from both the price of graphics processing units (GPU), which are largely parallel computing devices that were mainly manufactured by companies such as NVIDIA, which can cost 20,000-30,000 dollars or more per unit, and from the energy required to operate these chips continuously in large data centers.
Standard performance
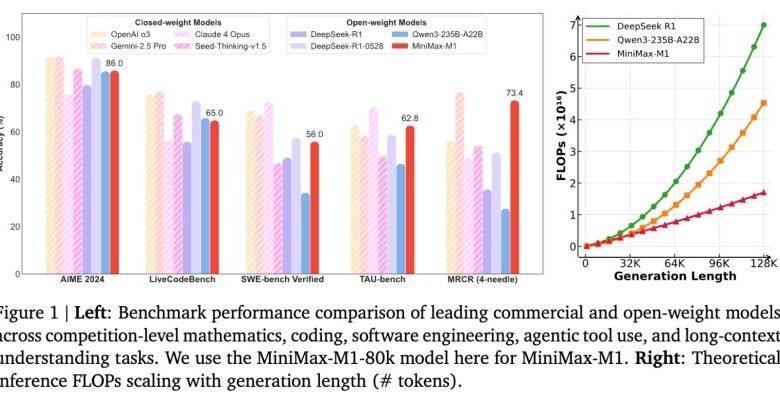
Minimax-M1 was evaluated through a series of in place that test advanced thinking, software engineering and tool use capabilities.
In AIME 2024, Mathematics Competitions, the M1-80K 86.0 % is taught. It also provides strong performance in the tasks of coding and long context, and achieving:
- 65.0 % on LiveCodebench
- 56.0 % on SWE seat
- 62.8 % on the seat
- 73.4 % on Openai MRCR (version 4-era)
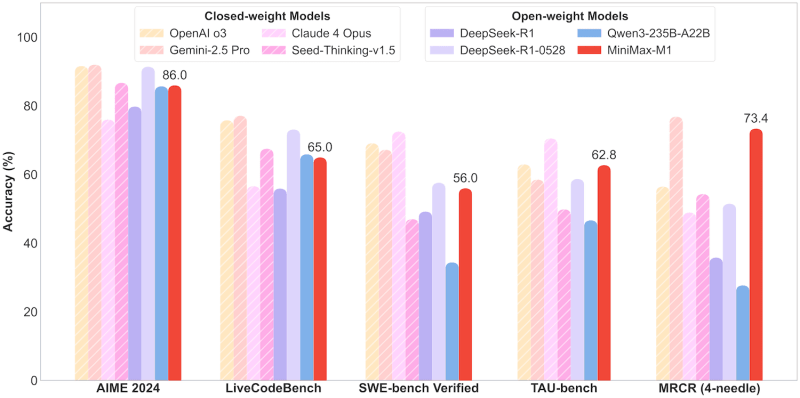
These results put Minimax-M1 before their competitors in open weight such as Deepseek-R1 and QWEN3-235B-A22b on several complex tasks.
While closed weight models such as Openai’s O3 and Gemini 2.5 Pro still topped some criteria, Minimax-M1 greatly narrows the performance gap while continuing to reach it freely under the Apache-2.0 license.
For publication, Minimax VLLM recommends as the background interface, citing the improvement of large model work burdens, memory efficiency, and payment of payment request. The company also provides publishing options using the Transformers Library.
The Minimax-M1 includes the potential for setting up structured jobs and is filled with API Chatbot, which includes online search, video and pictures generation, speech synthesis, and audio cloning tools. These features aim to support the wider behavior in agents in realistic applications.
The effects of technical decision makers and institution buyers
The open access to Minimax-M1, the capabilities of long context, and the efficiency calculation of many frequent challenges for technical professionals responsible for managing artificial intelligence systems on a large scale.
For engineering, the LEGINERING is responsible for the LLMS full life cycle-such as improving the performance of the model and publishing in the framework of narrow time schedules-MINMAX-M1 provides a lower operating cost file with support for advanced thinking tasks. The long context window can significantly reduce the pre -processing efforts of the institution’s documents or registry data that extend tens or hundreds of thousands of symbols.
For those who manage artificial intelligence synchronous pipelines, the ability to adjust and publish Minimax-M1 using fixed tools such as VLM or Transformers supports the easiest integration in the current infrastructure. The hybrid enrollment structure may help simplify the scaling strategies, and the competitive performance of the model provides multi -steps and engineering standards for software high as a high level of settlement or the agent -based systems.
From the perspective of the data platform, the teams responsible for maintaining effective and developed infrastructure can benefit from the support of the M1 to connect the organized functions and its compatibility with the automatic pipelines. Its open source provides the difference to customize performance with its staple without locking the seller.
Safety threads may also find value in assessing M1 capabilities for local safe publishing for a highly unable to transfer sensitive data to third -party end points.
Combined, Minimax-M1 offers a flexible option for institutions that look forward to an experience or expand the scope of advanced artificial intelligence possibilities while managing costs, survival within operational limits, and avoiding special restrictions.
The version indicates the constant focus of Minimax on practical and developmental artificial intelligence models. By combining open access, advanced architecture and account efficiency, the minimum M1 may be a key model for developers who build the following generation applications of the depth of thinking and understanding long -term inputs.
We will track other Minimax versions throughout the week. Stay followers!

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-16 22:46:00