MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x Faster
Can open source MOE really support a proxy coding workflow at a fraction of the costs of the main model while maintaining long-term use of the tool across MCP, shell, browser, retrieval, and code? The MiniMax team has just launched Mini Max-M2a combination of the expert MoE model optimized for encryption and proxy workflow. The weights on Hugging Face are published under an MIT license, and the model is modeled for end-to-end use of the tool, multi-file editing, and long-term planning. It lists a total of 229 billion parameters with about 10 billion active per token, keeping memory and response time in check during proxy loops.
Structure and why does activation size matter?
Mini Max-M2 It is a consolidated MOE that addresses approximately 10 billion active parameters per token. Smaller activations reduce memory pressure and latency in the plan, act, and check loops, and allow more concurrent operation in the CI, browse, and retrieval threads. This is a performance budget that enables speed and cost claims compared to dense models of similar quality.
Mini Max-M2 It is a model of interwoven thinking. The research team encapsulated the internal logic
Standards targeting codecs and proxies
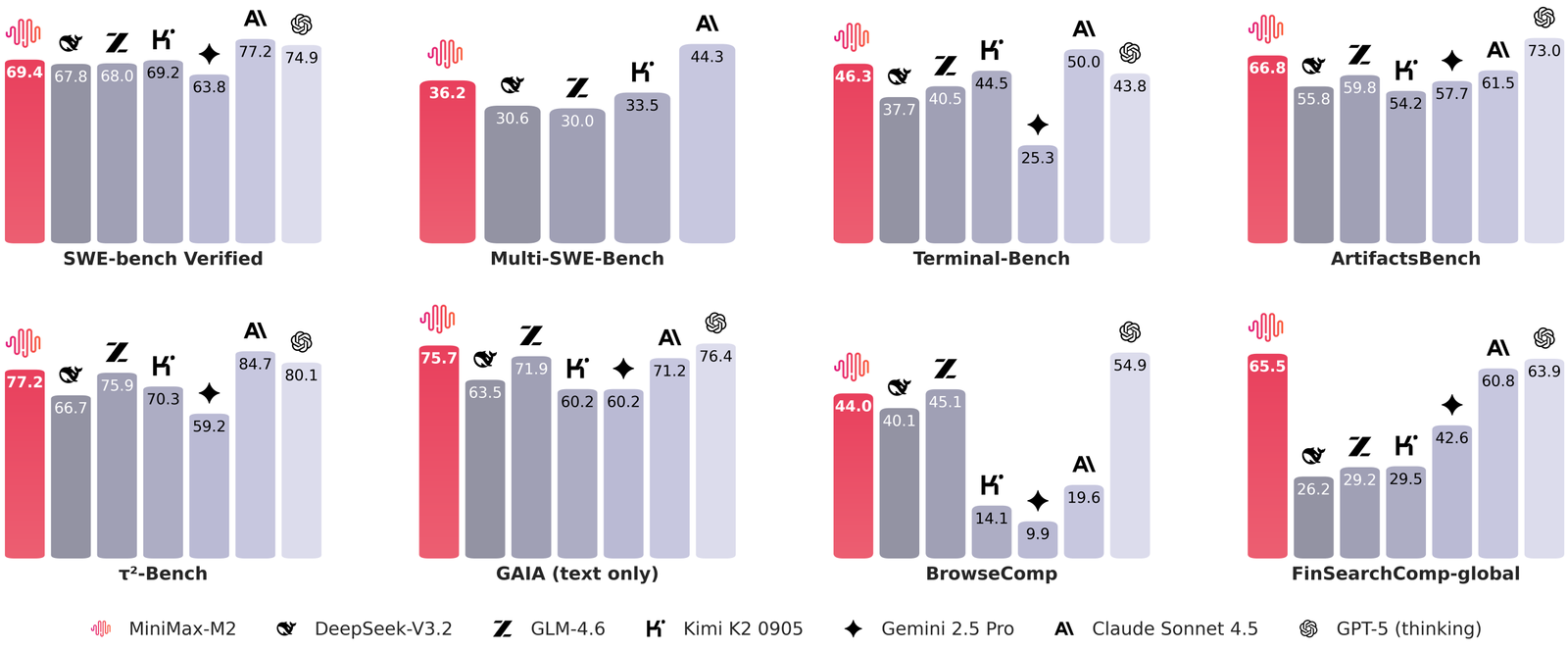
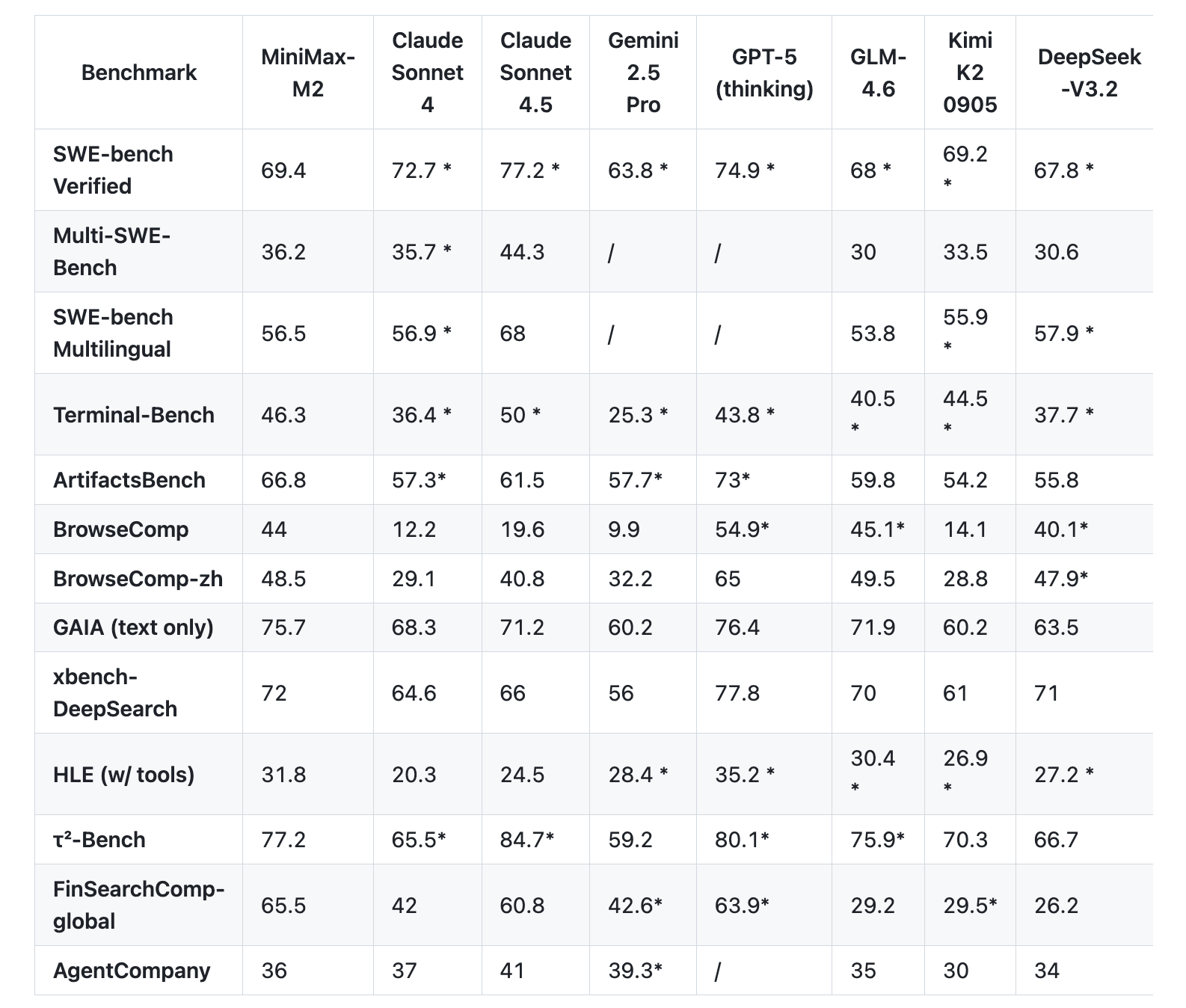
The MiniMax team reported a set of proxy and code evaluations closer to developer workflows than static QA. On the station bench, Table 46.3 is shown. On the Multi SWE Bench, it shows 36.2. In BrowseComp it shows 44.0. SWE Bench Verified is listed at 69.4 with scaffold details, and OpenHands with 128k100 context.
MiniMax’s official announcement confirms 8% off Claude Sonnet prices, nearly 2x speed, plus a free entry window. The same note provides the prices of the specific symbols and the trial deadline.
Compare M1 vs M2
| face | Mini Max M1 | Mini Max M2 |
|---|---|---|
| Total parameters | Total 456 b | 229B In the form card metadata, the form card text indicates that the total is 230B |
| Active parameters for each token | 45.9 billion active | 10B active |
| Basic design | A hybrid mix of experts with a lightning interest | A scattered mix of experts targeting coding workflows and agents |
| Thinking formula | Thinking about the 40k and 80k budget variants In RL training, the thinking tag protocol is not required | Interwoven thinking with |
| Standards highlighted | AIME, LiveCodeBench, SWE Bench Verification, TAU Bench, MRCR Long Context, MMLU-Pro | Terminal Bench, SWE Multi Bench, SWE Bench Verified, BrowseComp, GAIA Text Only, Artificial Analysis Intelligence Suite |
| Inference defaults | Temp 1.0, highest p 0.95 | Model card shows temp 1.0, top p 0.95, top k 40, launch page shows top 20 k |
| Guidance service | vLLM is recommended, and the adapter path is documented | Using vLLM and SGLang is recommended, and a tool invocation guide is provided |
| Primary focus | Long Contextual Reasoning, Efficient Measurement for Testing Time Calculation, and Reinforcement Learning for CISPO | Native agent and code workflow via shell, browser, loopback and code drivers |
Key takeaways
- The M2 is shipped as open weights on Hugging Face under MIT, with safeties in F32, BF16 and FP8 F8_E4M3.
- The model is an embedded MOE with a total of 229 billion parameters and about 10 billion actives per token, which the card associates with lower memory usage and more consistent latency in the planning, acting, and checking loops typical of agents.
- Outputs encapsulate internal thinking
... - Reported results cover Terminal-Bench, (Multi-)SWE-Bench, BrowseComp, and others, with key observations for reproducibility, and day 0 service for SGLang and vLLM is documented with concrete deployment evidence.
Editorial notes
Available in open weights under MIT, MiniMax M2 is a combination of design experts with a total of 229 bytes of parameters and about 10 bytes per token, which targets proxy loops and coding tasks with less memory and more stable latency. Hugging Face ships in security tools in FP32, BF16, and FP8 formats, and provides deployment notes as well as a chat template. The API documents humanized endpoints and lists prices with a limited free window for evaluation. vLLM and SGLang recipes are available for local provisioning and benchmarking. Overall, the MiniMax M2 is a very solid unlocked version.
verify API doc, weights and repo. Feel free to check out our website GitHub page for tutorials, codes, and notebooks. Also, feel free to follow us on twitter Don’t forget to join us 100k+ mil SubReddit And subscribe to Our newsletter. I am waiting! Are you on telegram? Now you can join us on Telegram too.

Michel Sutter is a data science specialist and holds a Master’s degree in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michelle excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as a favorite source on Google.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-10-28 22:21:00