
Muon Optimizer Significantly Accelerates Grokking in Transformers: Microsoft Researchers Explore Optimizer Influence on Delayed Generalization
Reconsidering the fragile challenge
In recent years, a phenomenon chase– Where deep learning models show a late but sudden transfer from preservation to generalization – have pushed to renew the investigation of training dynamics. It is initially observed in small algorithm tasks such as standard account, the nomination reveals that models can reach the accuracy of the almost ideal training while health verification remains weak for a long time. In the end, the model often begins to generalize. Understanding what governs this transition is important not only for interpretation, but also to improve the efficiency of training in deep networks. Previous studies have highlighted the role of weight and regulation. However, the specific effect of improved on this process has been canceled.
Investigate the effects of the improved cohesion
This artificial intelligence sheet is looking for Microsoft in the effect of the optimum choice of behavior. Specifically, it contradicts the performance of Adamw Optimizer on a large -scale adopted with MUON, which is the latest improvement algorithm that includes spectral standard restrictions and second -class information. The study is looking at whether these features enable MUON to accelerate the generalization phase.
Seven algorithm tasks – normative mathematical operations and equivalence – using a modern transformer structure. Each task is designed to show the decline reliably under the appropriate training conditions. The research also includes a comparative analysis of the SoftMax (SoftMax, Stablemax, and Sparsemax) to assess whether the output normalization plays a secondary role in adjusting the training dynamics. However, the basic investigation focuses on the benefactor.
Architectural design and improvement
The basic model structure adopts standard transformers components, which were implemented in Pytorch. It includes multi -head sclerosis, circle topical inclusion (rope), normalization of RMS, activation of the licks, and leakage regulation. Distinctive symbols of inputs – values or factors available – are coded through simple identity inclusion.
The main distinction lies in the behavior of the benefactor:
- AdamoIt is a basic line in the progress of contemporary deep learning work, which uses adaptive learning rates with separate weight decomposition.
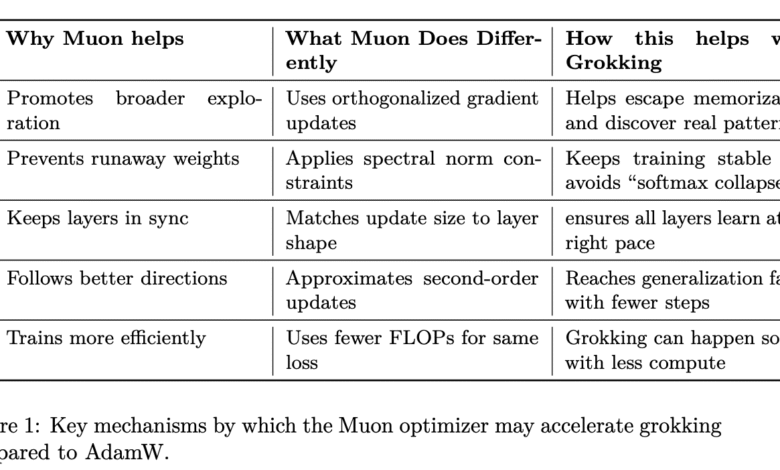
- TearIn contrast, the perpendicular gradients apply, and impose the restrictions of the spectrum standard to achieve stability in training, and bring a second -class curvature to more useful updates.
These mechanisms aim to enhance the wider exploration during improvement, reduce instability (for example, “SoftMax collapse”), and synchronization of learning across classes. MUON is the ability to regulate the size of the update according to the dimensions of the layer, especially related to avoiding ineffective memorization paths.
Three SoftMax – SoftMax, Stablemax and Sparsemax – to assess whether numerical stability or the interpretation of the output distribution affects fun. This helps to ensure that the monitored effects stem mainly from improved dynamics instead of the nuances to stimulate the output.
Evaluation and experimental results
The experimental protocol to study is designed systematically. Each improved group is evaluated for the important people through multiple seeds to ensure statistical durability. The operational filter is defined as the first era as the accuracy of health verification exceeds 95 % after the accuracy of the training.
The results indicate a consistent and statistically significant feature. On average, MUON reaches the nomination threshold in 102.89 era, compared to 153.09 era for Adamw. This difference is not only a numerical, but it is also statistically strict (T = 5.0175, P ≈ 6.33E – 8). In addition, MUON explains a more strict distribution than the nomination era in all circumstances, indicating more predictable training paths.
All tasks were made on NVIDIA H100 graphics units using a uniform code base and uniform configurations. Tasks include a normative addition, multiplication, division, prices, GCD, and a 10 -bit equal task. Data sets ranged from 1024 to 9,409 examples, while modifying the validation of training validation for each task to maintain consistency.
conclusion
The results provide strong evidence that improved engineering greatly affects the emergence of generalization in excessive models. By directing the improvement path through second -class perceived updates and spectral standard restrictions, MUON seems to facilitate a direct path towards discovering the infrastructure of the basic data, bypassing the excellent stages.
This study emphasizes the broader need to consider the improvement strategy as a first -class factor in nervous training design. Although the previous work emphasized data and organization, these results indicate that the improved structure itself can play a pivotal role in forming training dynamics.
verify paper. Also, do not forget to follow us twitter And join us Telegram channel and LinkedIn GrOup. Don’t forget to join 90k+ ml subreddit.
🔥 [Register Now] The virtual Minicon Conference on Agency AI: Free Registration + attendance Certificate + 4 hours short (May 21, 9 am- Pacific time)
Niegel, a trainee consultant at Marktechpost. It follows an integrated double degree in materials at the Indian Institute of Technology, Khargpur. Nichil is a fan of artificial intelligence/ml that always looks for applications in areas such as biomedics and biomedical sciences. With a strong background in material science, it explores new progress and creates opportunities to contribute.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-04-23 06:10:00



