NVIDIA AI Released DiffusionRenderer: An AI Model for Editable, Photorealistic 3D Scenes from a Single Video
Amnesty International -Working Video is improved at a breathtaking pace. In a short time, we moved from Blurry, and non -coherent clips to videos created with amazing realism. However, despite all this progress, the critical ability was missing: Control and liberation
While generating a beautiful video clip one thing, the ability to professionalize and realistic Restricting It is – to change the lighting from day to day, switching the object from wood to metal, or inserting a new element in the scene – shadow of a huge problem, and it has not been largely solved. This gap was the main barrier that prevents artificial intelligence from becoming a truly founding tool for film factories, designers and creators.

Even input DiffusionRanderindication
In a pioneering new paper, researchers at NVIDIA, University of Toronto, Vector Institute and Illinoi Urbana Chambine revealed a framework that addresses this challenge directly. DiffusionRander represents a revolutionary leap forward, exceeding just a generation to provide a uniform solution to understand 3D scenes and process it from one video. It fills the gap between generation and liberation effectively, and cancel the real creative capabilities of the content moved by artificial intelligence.
The old way versus the new road: The model is transformed
For decades, realism has been installed in PBR, which is a methodology that accurately emulates the flow of light. Although it produces amazing results, it is a fragile system. PBR depends on the presence of an ideal digital scheme for a scene – three -dimensional engineering, detailed material textures, and accurate lighting maps. The process of capturing this scheme from the real world, known as the name Reverse servingIt is very difficult and exposed to error. Even small defects in these data can cause catastrophic failure in the final offer, the neck of the main bottle that limits the use of PBR outside the controlled studio environments.
Previous nervous presentation techniques like NERFS, while a revolutionary to create fixed views, hit the wall when it comes to editing. They “bake” lighting and materials in the scene, which makes post -capture adjustments almost impossible.
DiffusionRander He treats “What” (the characteristics of the scene) and “How” (the show) in one unified framework based on the same structure of publishing a strong video that supports models such as publishing a stable video.
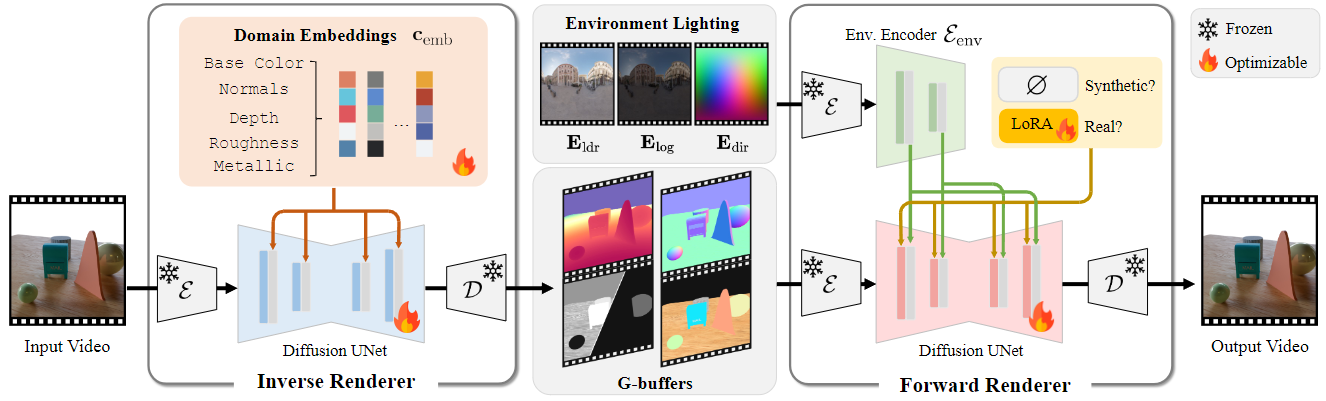
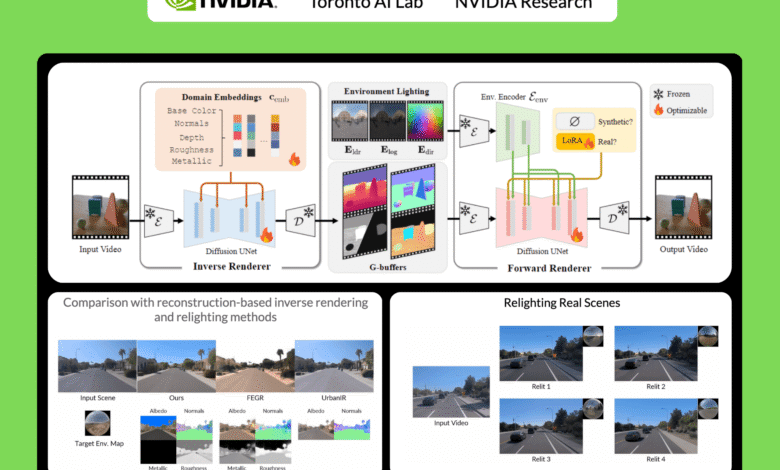
This method uses two nervous exhibitors to process video:
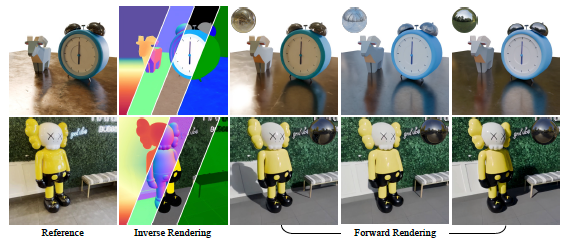
- The reverse symptom: This model behaves like a scene investigator. It analyzes the RGB video clip and is intelligently estimated by the fundamental characteristics, which generates the basic data stores (G-Buffers) that describe the scene engineering (normals, depth) and materials (color, roughness, metal) at a pixel level. Each feature is created in a dedicated pass to enable high quality generation.
- Nervous anterior bidder: This model works as an artist. It takes G-Buffers from the reverse bidder, and combines them with any required lighting (environment map), and a realistic video collection. It is important, trained to be strong, able to produce amazing and complex light transport effects such as soft shades and repercussions even when the inputs G of reverse crossbar are incomplete or “noisy”.
This self -correction synergy is the essence of penetration. The system is designed for the chaos of the real world, where the ideal data is legend.
Secret Sap: A new data strategy to bridge the reality gap
The smart model is not something without smart data. The researchers behind DiffusionRander have created a genius data strategy of two types to teach their model the nuances of both ideal physics and incomplete reality.
- A huge artificial world: First, they built a vast and high -quality artificial data collection of 150,000 video clips. Using thousands of 3D objects, PBR materials, and HDR lights, they created complex scenes and made them with a perfect track tracking engine. This reverse show model gave a flawless “school book” to learn from it, providing him with perfect data for the Earth.
- Auto real world naming: The team found that the reverse bidder, which was trained only on artificial data, was amazingly good in circulating on real videos. They unleashed her on a huge data collection of 10,510 real video clip (DL3DV10K). The model automatically created the G-Buffer stickers for these realistic shots. This created a huge data collection, 150,000 samples of real scenes with corresponding properties-and if it is incomplete-.
By training the front bidder on both the ideal artificial data and realistic data called the critical “gap” bridge. I learned the rules of the artificial world, the appearance and appearance of the real world. To deal with the inevitable inaccuracy in the data called automatically, the team merged the Lora unit (low -ranking adaptation), a smart technology that allows the model to adapt to the smaller real data without prejudice to the knowledge gained from the virgin artificial group.
Later
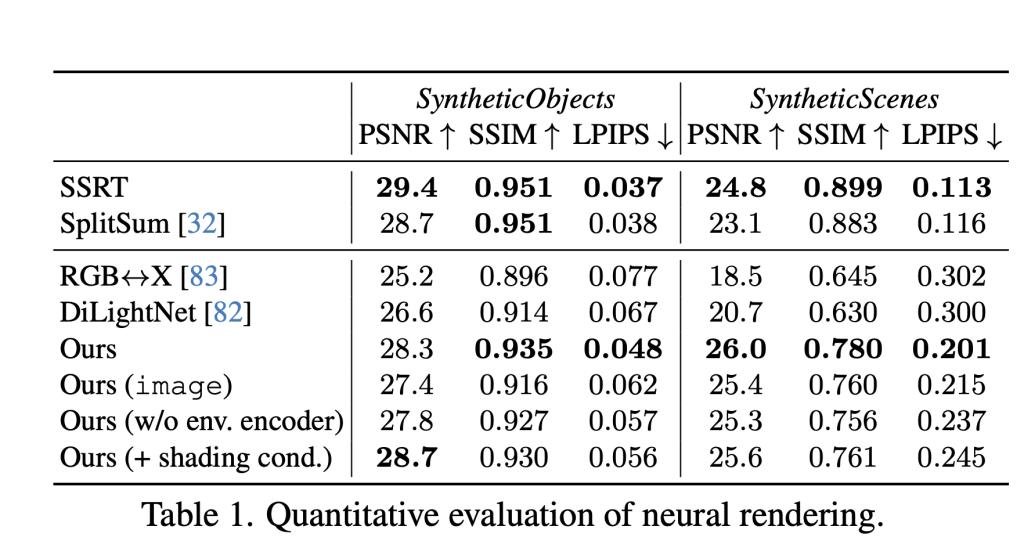
The results talk about themselves. In strict face -to -face comparisons against both classic and neurological methods, DiffusionRander has been constantly appeared in all the tasks that were evaluated with a wide margin:
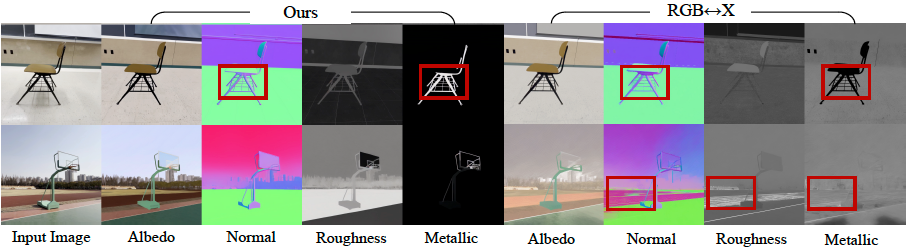
- Present forward: When creating images of G-Buffers and lighting, DiffusionRander has greatly outperformed the other neurological methods, especially in multi-object scenes where the implications and shades are very important. Nervous serving greatly outperformed other methods.

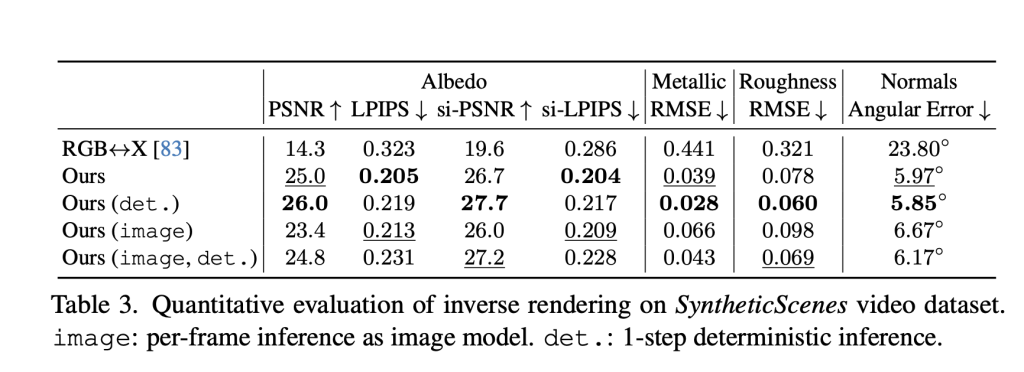
- Reverse serving: The model has proven superior in estimating the fundamental characteristics of the scene from a video, as it achieved a higher accuracy on eggs, materials and natural appreciation from all basic lines. It turns out that the use of the video model (versus one image model) is particularly effective, which reduces errors in metal prediction and roughness by 41 % and 20 %, respectively, as it enhances the movement to understand the effects that depend better.

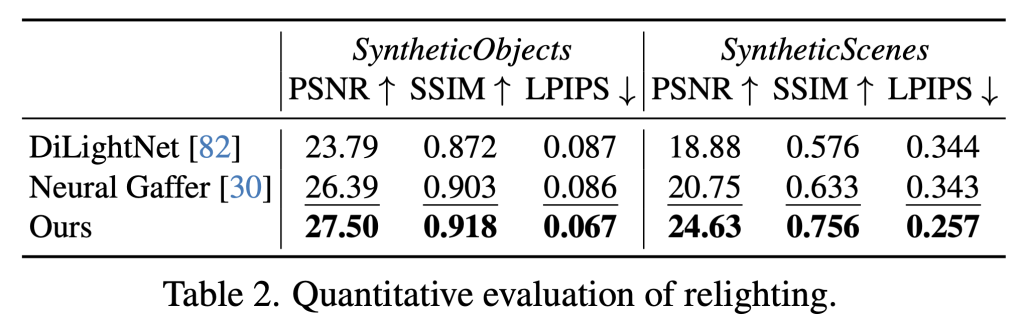
- Relaxation: In the final test of the standard pipeline, DiffusionRander has produced superior comfort and substance compared to leadership methods such as DilightNet and nervous gaffer, which generates more accurate repercussions and high -resolution lighting.
What you can do with Diffusionrender: Strong Edit!
This research opens a set of practical and powerful editing applications that work from one daily video. The workflow is simple: The model first performs a reverse view to understand the scene, and the user edits the characteristics, then the model leads to a video forward to create a new realistic video.
- Dynamic comfort: Change the time of the day, switch the studio lamps for sunset, or change the mood of the scene completely by providing a new environment map. The frame is realistic re -viewing the video with all the shadows and the corresponding repercussions.
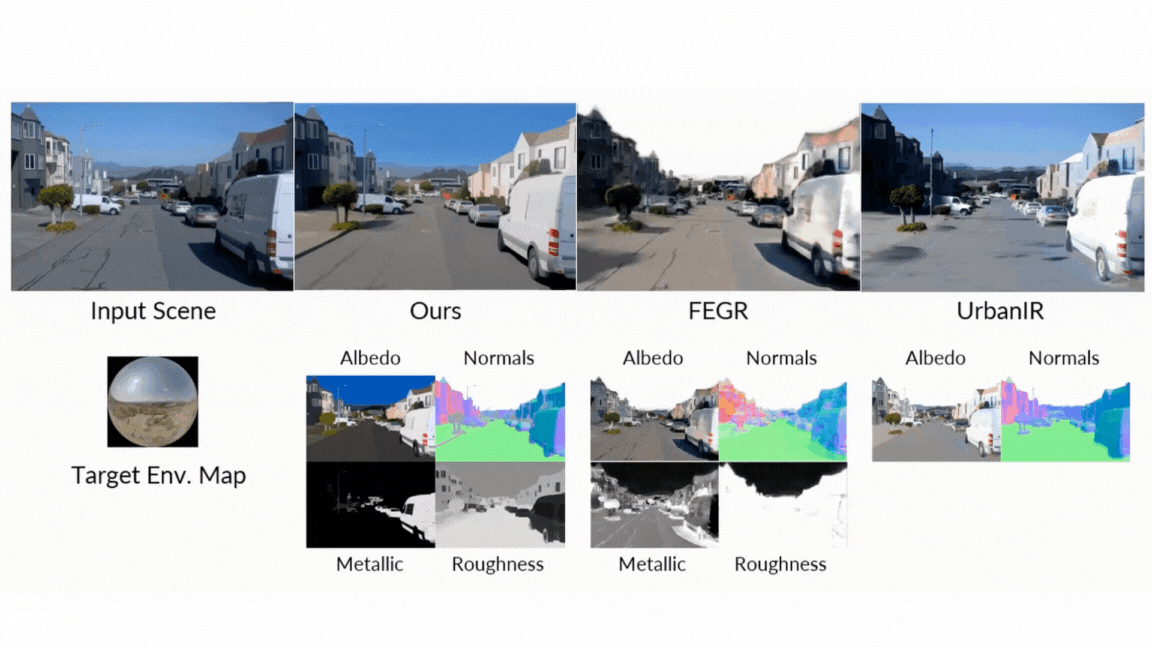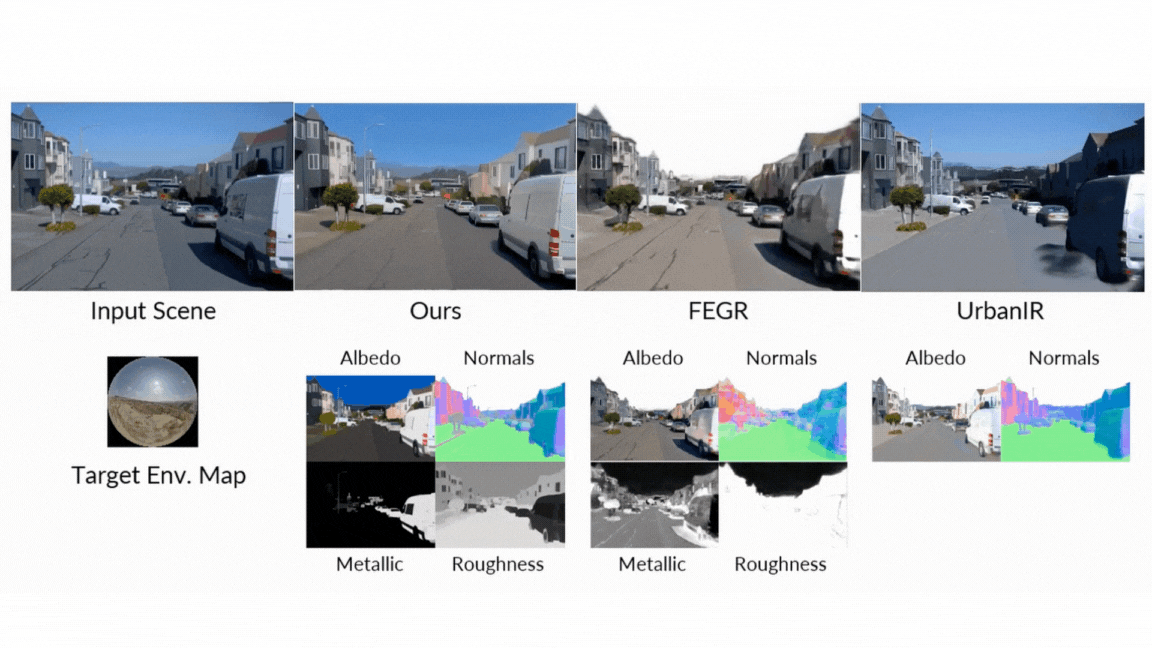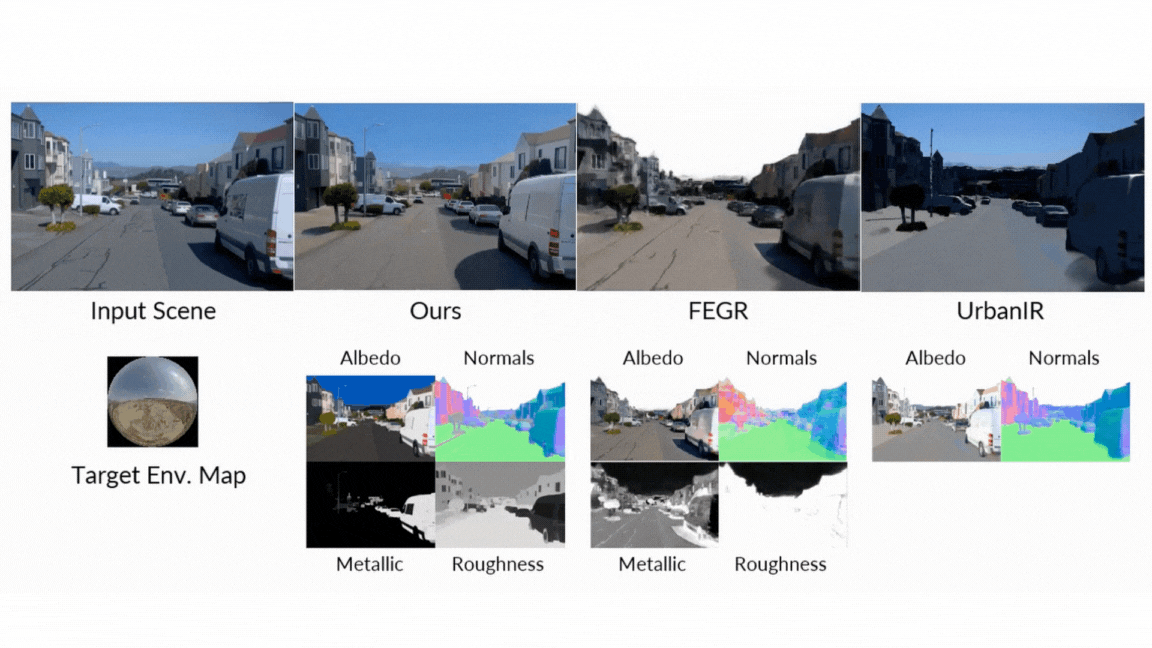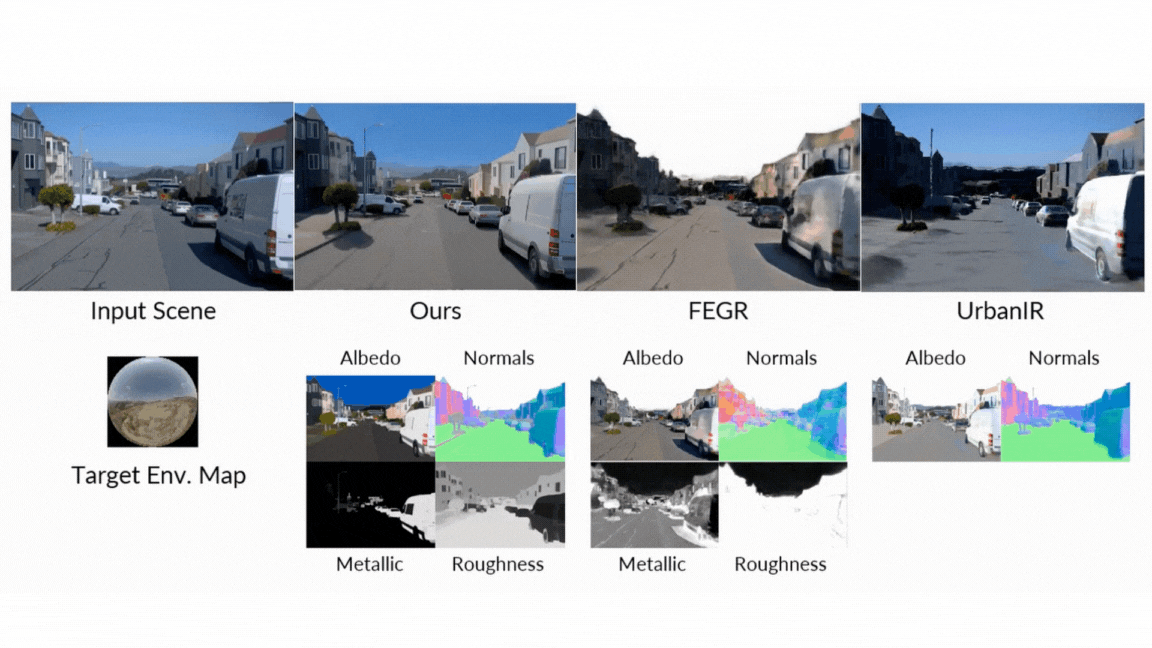
- Editing of intuitive materials: Do you want to see how this leather chair looks like in the chrome? Or made a metal statue that seems to be made of raw stone? Live users can adjust the G-Buffers-modified roughness, metal properties and colors-and will make the form changes in the form of images.
- Insert a smooth object: Put new virtual objects in a real scene. By adding the properties of the new object to the Go-Buffers in the scene, the front exhibitor can synthesize a final video where the object is naturally integrated, represents realistic shades and captures accurate repercussions of its surroundings.


A new basis for graphics
DiffusionRander is a final breakthrough. By a completely opposite solution and to the front of one strong frame that depends on data, it tears long -term barriers of traditional PBR. It weakens democrats realistic progress, transferring it from the exclusive field of VFX experts with strong devices to a more easy tool for creators, designers and AR/VR developers.
In a modern update, the authors increase the improvement of video lighting and re -lighting by taking advantage of NVIDIA Cosmos and arranging improved data.
This explains the direction of promising scaling: since the primary video posting model is increasing, the quality of the output improves, which leads to more accurate and more accurate results.
These improvements make technology more convincing.
The new model is released within APache 2.0 and NVIDIA Open Model and IS Available here
sources:
Thanks to the NVIDIA team to lead/ the thought resources for this article. The NVIDIA team has supported and sponsored this content/article.

Jean-Marc is a successful CEO of Amnesty International’s business. He leads and speeds up the growth of artificial intelligence solutions and has started a computer vision company in 2006. He is a recognized spokesman for artificial intelligence conferences and has a MBA from Stanford.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-10 21:25:00