
NVIDIA AI Releases Nemotron Nano 2 AI Models: A Production-Ready Enterprise AI Model Family and 6x Faster than Similar Sized Model
NVIDIA has unveiled the NAMONON NANO 2 family, where a group of large LLMS models (LLMS) presented that not only pays modern logical accuracy, but also provides up to 6 x production higher than models of similar size. This version is highlighted with unprecedented transparency in data and methodology, as NVIDIA provides most of the training and recipes group in addition to the typical checkpoints of society. It is very important that these models maintain a huge context capacity of 128,000 on the unit of medium -term graphics processing, which greatly reduces barriers to think about the long context and spread the real world.
The most prominent major landmarks
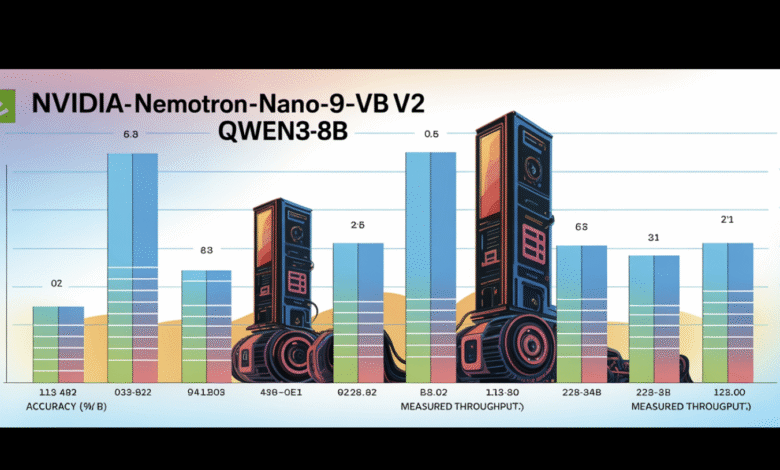
- 6 x productivity against models of similar size: NAMOTRON NANO 2 offers up to 6.3 x speeds of generating the distinctive symbol for models such as QWEN3-8B in heavy thinking scenarios-without sacrificing accuracy.
- A super accuracy of thinking, coding and multi -language tasks: The criteria show results at the level or better versus competitive open models, especially bypassing their peers in mathematics and symbols, using tools and long context tasks.
- The length of context 128K on the one graphics processing unit: Effective pruning and hybrid architecture allows 128,000 symbolic inferences on the NVIDIA A10g graphics unit (22GIB).
- Open data and weights: Most of the pre -training and post -training data sets are released, including code, mathematics, multi -language SFT data, communications, and thinking data, with a lagging -faced license.
Hybrid architecture: Mamba meets the transformer
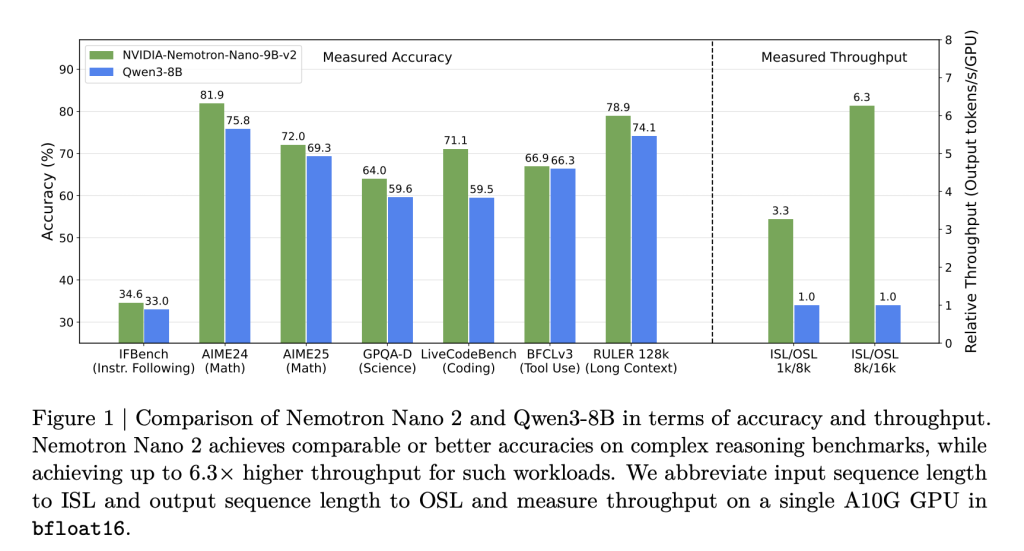
NAMOTRON NANO 2 was built on Mamba-Transformer, inspired by the Nemotron-H brown. Most traditional self-enrollment layers are replaced by effective MAMBA-2 layers, with only about 8 % of the total layers using self-interest. This architecture is carefully designed:
- Form details: The lexical 9B is 56 layers (out of 62 trains in advance), a hidden size of 4480, with an assembled attention and mamba-2 space layers that facilitate both the ability to expand and retain long sequence.
- Mamba-2 innovations: These recently circulated government space layers as highly productive sequencing models are intertwined with the singing self -enrollment (to maintain long -term dependencies) and large nutrition networks.
This structure allows high productivity to thinking tasks that require “the effects of thinking”-long generations that are based on a long input within the context-where they often slow or run out of traditional transformers.
Training recipe: diversity of huge data, open sources
Nemotron Nano 2 models are trained and distilled from the 12B teacher teacher model using a wide -quality range. NVIDIA’s unprecedented transparency is highlighting:
- 20T pre -codes: Data sources include Corpora sponsorship and artificial sponsorship of reality, mathematics, symbol, multi -language fields, academic and leg.
- Main data collections have been released:
- Nemotron-CC-V2: Multi -language web crawl (15 languages), artificial, divine, divine questions and answers.
- Nemotron-CC-Math: 133b distinctive codes for mathematics content, uniform to Latex, more than 52 B “highest quality”.
- Nimotron Code: Code: Gabbab source code from the sponsorship and candidate of quality; Removing strict pollution and distraction.
- SFT-SFT Nemotron: Artificial data groups, follow -up of stem, logic, and public fields.
- Post -training data: More than 80B includes a symbol of supervision control (SFT), RLHF, tools, and multi-language data groups-most of which are open for direct cloning.
Alignment, distillation, and pressure: open effective and long -term thinking thinking
The NVIDIA model compression process is designed on the “Minitron” and MAMBA trim:
- Knowledge distillation From the 12B teacher reduces the model to the 9B parameters, with the precise pruning of the layers, FFN dimensions, and an inclusion display.
- SFT and RL: Improving tools (BFCL V3), IFEVAL, DPO and GRPO reinforcement, control of thinking budget (support for reasonable reasonable thinking budgets).
- NAS target for memory: By searching for architecture, the hacking models are specifically designed so that they are both the maintenance of the major value and valuable value-and the performance-with the GPU A10G memory along the context of 128K.
The result: the inference speeds up to 6 x faster than the competitors open in the scenarios with large input/output symbols, without the accuracy of the task at risk.
Measurement: superior capabilities and multi -language capabilities
In face -to -face assessments, NAMOTRON NANO 2 Excel models:
| Mission/seat | Nemotron-nano-9B-V2 | QWEN3-8B | GEMMA3-12B |
|---|---|---|---|
| MMLU (General) | 74.5 | 76.4 | 73.6 |
| MMLU-PRO (5 shots) | 59.4 | 56.3 | 45.1 |
| GSM8K Cot (Mathematics) | 91.4 | 84.0 | 74.5 |
| mathematics | 80.5 | 55.4 | 42.4 |
| Humaneval+ | 58.5 | 57.6 | 36.7 |
| Ruler 128k (long context) | 82.2 | – | 80.7 |
| MMLU-Lite (Avg Multi) | 69.9 | 72.8 | 71.9 |
| MGSM Mathematical Mathematics (AVG) | 84.8 | 64.5 | 57.1 |
- Productivity (symbols/s/GPU) at 8K/16K output:
- Nemotron-nano-9B-V2: up to 6.3 x QWEN3-8B in the effects of thinking.
- It maintains up to 128 km with the size of the batch = 1- Not practical at the level of medium graphics processing units.
conclusion
The Nvidia’s Nemotron Nano 2 version is an important moment of LLM open research: it redefines what is possible to the unit of one-graphics processing in terms of cost-speed and context-while raising the tape of transparency and cloning. Its hybrid structure, productivity superiority, and high -quality open data groups have been set to accelerate innovation through Amnesty International’s ecosystem.
verify Technical details, paper and Models on face embrace. Do not hesitate to check our GitHub page for lessons, symbols and notebooks. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-08-19 17:40:00



