NVIDIA AI Researchers Introduce FFN Fusion: A Novel Optimization Technique that Demonstrates How Sequential Computation in Large Language Models LLMs can be Effectively Parallelized
LLMS models have become vital across the fields, allowing high -performance applications such as generating natural language, scientific research, and conversation factors. Under these developments lies the intention of transformers, where layers alternate from attention mechanisms and feeding networks (FFNS) are treated for symbolic input. However, with increased volume and complexity, the mathematical burden is greatly required to infer significantly, creating the bottleneck. Effective reasoning has now become a decisive concern, as many research groups focus on strategies that can reduce cumin, increase productivity, and reduce mathematical costs while maintaining or improving the performance of the model.
In the center of this problem, the serial structure lies in its nature for transformers. The output of each layer feeds the next day, requires strict and synchronous arrangement, which represents a special problem on a large scale. With the expansion of models sizes, the cost of serial account and communication grows through graphics processing units, which leads to low efficiency and increasing the cost of publishing. This challenge is amplified in scenarios that require a quick and multiple generation, such as real -time artificial intelligence assistants. This serial load reduces the possibilities of the model as a major artistic obstacle. Opening new parallel strategies that maintain accuracy, but significantly reduces the depth of the account is necessary to expand access to LLMS and expansion.
Many techniques have appeared to improve efficiency. It reduces the accuracy of numerical representations to reduce memory and calculation needs, although they often risk accuracy losses, especially in the display of low bits. Pruning eliminates excessive parameters and simplifying models, but it is likely to harm accurately without care. Experience models (MEE) stimulate only a sub -set of parameters for each input, which makes them very effective for specific work burdens. However, it can be less than the performance of medium payments due to the use of low devices. Although they are valuable, these strategies have bodies that limit their global application capacity. Consequently, the field is looking for ways to provide extensive efficiency with fewer concessions, especially for dense structures that are simpler for training, deployment and maintenance.
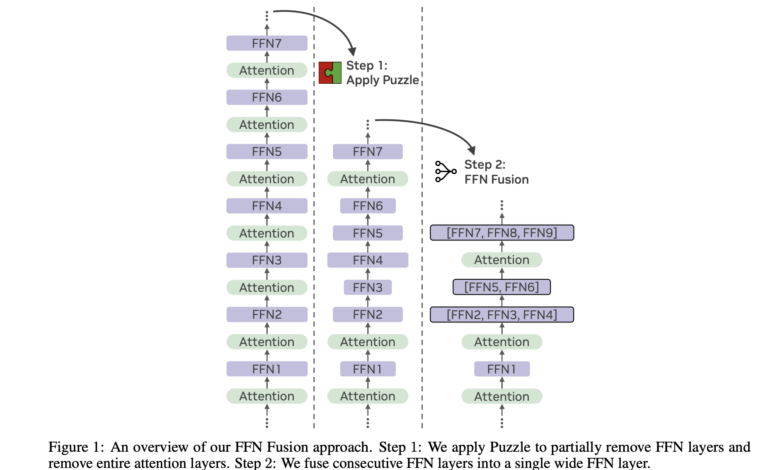
Researchers at NVIDIA presented a new architectural improvement technology FFN fusionWhich treats the serial bottleneck in transformers by identifying the FFN sequence that can be implemented in parallel. This approach appeared from noting that when attention layers are removed using the puzzle tool, models often keep long sequences of successive FFNS. These sequences show minimal mutual dependence, and therefore, can be treated simultaneously. By analyzing the LLMS structure such as Llama-3.1-405B-Instruct, researchers created a new model called Ultra-253B-Base by pruning and restructuring the basic model through FFN Fusion. This method leads to a more efficient model that maintains competitive performance.
FFN Fusion Many FFN layers in one FFN, wider. This process is based on mathematical parity: through the sequence of several FFNS weights, one can produce one unit that behaves like the total of the original layers but can be calculated in parallel. For example, if three FFNs are stacked successively, each depends on a previous one output, its merge removes these dependencies by ensuring the three work on the same inputs and collecting their outputs. The theoretical basis for this method shows that FFN fascinates maintains the same representative ability. The researchers conducted dependency analysis using a fully fully pocket distance to determine the low -bonding areas. These areas were considered ideal for fusion, as the minimum change in the direction of the distinctive symbol between classes indicated the feasibility of parallel treatment.
FFN Fusion app on the Llama-405B model led to the Ultra-253B base, making noticeable gains in speed and resource efficiency. Specifically, the new model achieved a improvement of 1.71X in the time of reasoning and reducing the calculations per 35x by 32 degrees. This efficiency did not come at the expense of ability. Ultra-253B-Base 85.17 % record on MMLU, 72.25 % on MMLU-PRO, 84.92 % on Arena hard, 86.58 % on Humaneval, and 9.19 on MT on the MT seat. These results often coincide or exceed the model of 405b parameters, although the Ultra-253B base contains only 253 billion teachers. Memory use also improved with a decrease of 2 x in KV-CACHE requirements. The training process included distillation of 54 billion symbols in the window of 8K, followed by a manufacturer of 16 km, 32 km and 128 km. These steps guaranteed that the molten model maintains high accuracy with the use of low size.
 AI-Researchers-Introduce-FFN-Fusion-A-Novel-Optimization-Technique.png" alt="" style="width:679px;height:auto"/>
AI-Researchers-Introduce-FFN-Fusion-A-Novel-Optimization-Technique.png" alt="" style="width:679px;height:auto"/>This research shows how the studied architect can open great gains from efficiency. The researchers have shown that FFN layers in the transformer structure are often more independent than supposed previously. The method of measuring the dependency between the layer and the conversion of the model structures allows a broader application through models of different sizes. This technique has been validated on the parameter 70B model, proving the circular. Additional experiments indicated that although FFN layers can often be combined with the minimum effect, and the complete parallel of the mass, including interest, it provides more performance deterioration due to the strongest bonding.

Many of the main meals of search on FFN Fusion:
- FFN Fusion technology reduces serial account in transformers by parallel to low -credit FFN layers.
- The integration is achieved by replacing the FFNS sequence with one widespread FFN using sequential weights.
- Ultra-253B-Base, derived from Llama-3.1-405B, achieves 1.71X the fastest inference and 35x less than the cost of everything.
- Standard results include: 85.17 % (MMLU), 72.25 % (MMLU-PRO), 86.58 % (Humaneval), 84.92 % (Arena Hard), and 9.19 (MT-Bect).
- The memory is cut by half due to the improvement of the KV-CACHE.
- FFN Fusion is more effective on the scales of the largest models and works well with techniques such as pruning and complementary.
- The full parallel of the ancient transformer appears, but it requires more research due to the strongest interconnection.
- A systematic method using the distance of the perfection pocket helps to determine the safe FFN serials for the installation.
- This technology has been validated through different typical sizes, including 49B, 70B and 253B.
- This is the basic approach to LLM designs more convenient and effective for devices.
Payment The paper. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 85k+ ml subreddit.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically intact and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.
2025-03-29 19:33:00