
Nvidia Blackwell Reigns Supreme in MLPerf Training Benchmark

For those who have a root for the weak, the latest standard MLPERF results will disappoint your possession: NVIDIA graphics units have dominated the competition yetonce again. This includes a performance that leads the chart on the latest and most demanding standards, highlighting the Llama 3.1 403B language model. However, computers that were built around the latest GPU AMD, Mi325X, match NVIDIA H200, Blackwell Ancestor, on the most popular standard llm, precise polishing. This indicates that AMD is one generation behind NVIDIA.
Mlperf Training is one of the MLCOMMons. “The performance of artificial intelligence can sometimes be a kind of wild West. Mlperf seeks to provide the system to that chaos,” says Dave Salvator, Director of accelerating computing products at NVIDIA. “This is not an easy task.”
Competition consists of six criteria, each of which searches for a different automatic learning task with industry. Standards are content recommendation, great language model, great language model, detection of objects for machine vision applications, images generation, and classification of applications for applications such as fraud and drug discovery.
The task of training the big linguistic model is the most intense resource, and this tour has been updated to be more than that. The term “pre -training” is somewhat misleading – it may give the impression that it is followed by a stage called “training”. it’s not. The gradual is the place where most numbers occur, and the following is usually a good refinement, which improves the model for specific tasks.
In previous repetitions, training on the GPT3 model was conducted. This repetition was replaced by Meta’s Llama 3.1 403B, which is more than twice the size of GPT3 and uses a four -time context window. The window of context is the amount of the text of the input that the model can treat once. This is the largest standard of industry for larger models than ever, as well as including some architectural updates.
Blackwell tops the plans, AMD on its tail
For all six criteria, the fastest training time for Black Cwellings in NVIDIA. NVIDIA has provided itself to each standard (other companies have also been offered using various computers built around NVIDIA GPU). SALVATOR of NVIDIA emphasized that this is the first publication process to measure Blackweell on a large scale and that this performance is likely to improve only. “We are still somewhat early in the Blackwele Development Bay.”
This is the first time that AMD has been introduced to the training standard, although in previous years other companies have provided computers that included AMD graphics processing units. In the most popular standard, Llm Tuning, AMD showed that the latest GPU MI325X instinctively displayed with NVIDIA H200S. In addition, the MI325X instinct showed a 30 percent improvement on its predecessor, the MI300X instinct. (The main difference between the two is that Mi325X comes with a 30 percent high cross memory of Mi300X.)
For the part, Google has been sent to one standard, which is the task of meeting the images, with Trillium TPU.
The importance of networks
Among all the presentations to LLM minute control standards, the system that contains the largest number of graphics processing units by NVIDIA, a computer connecting 512 B200s. On this range, communication between graphics processing units begins to play an important role. Ideally, adding more than GPU will divide time to train in the number of graphics processing units. In fact, it is always less efficient than that, as some time is lost to contact. Reducing this loss is the training key efficiently the largest models.
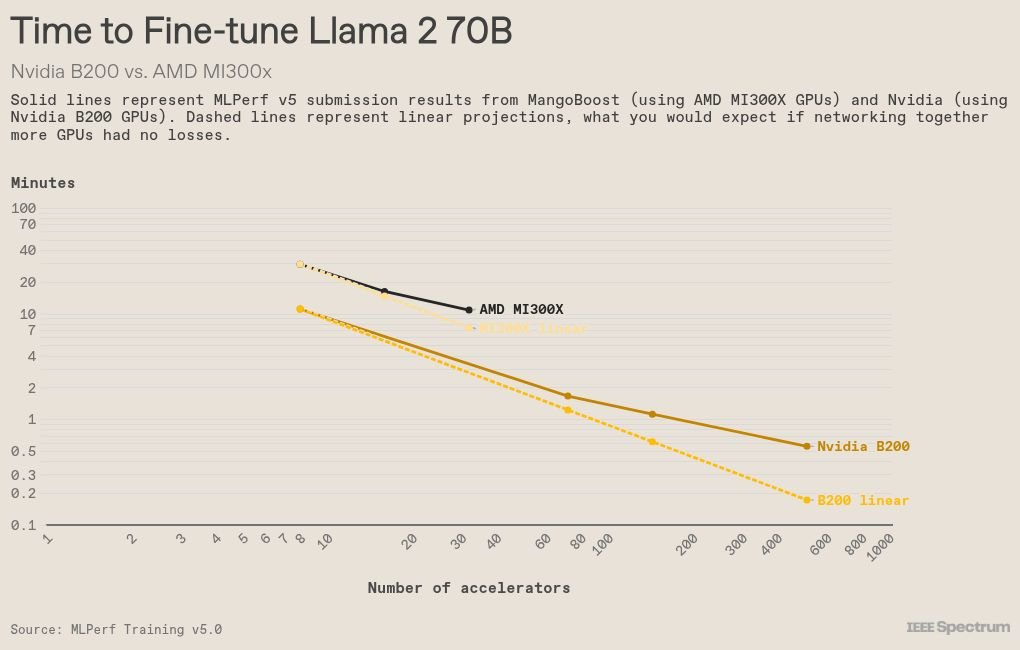
This becomes more important in the pre -standard, as the smallest introduction of 512 graphics processing units, and the largest 8,192. For this new standard, the scaling of performance with more graphics processing units in particular was close to the linear, achieving 90 percent of the ideal performance.
This NVIDIA SALVATOR is attributed to NVL72, an effective package linking 36 Grace CPUS and 72 GPUS Blackweell with Nvlink, to form a system “that works as a single single graphics processing”, and claims the database. Multiple NVL72S was then connected to the Infiniband network technology.
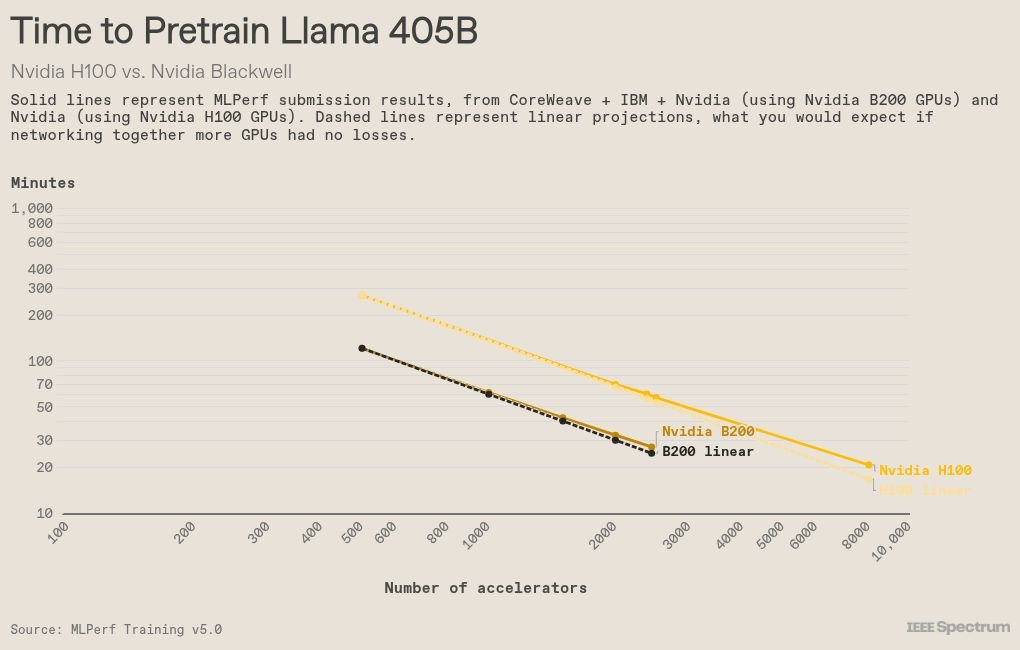
It is worth noting that the largest presentation of this round of Mlperf – in graphics processing units 8192 – is not the largest ever, although the increasing increasing in the pre -standard. Previous rounds witnessed the presentations with more than 10,000 graphics processing units. Kenneth Leach, the main AI and a machine learning engineer at Hewlett Packard Enterprise, is reducing the improvements in graphics processing units, as well as communication between them. “Previously, we needed 16 server contract [to pretrain LLMs]But today we are able to do this with 4. I think this is one of the reasons why we see a lot of huge systems, because we get a lot of effective scaling. ”
One way to avoid networks associated with networks is to place many artificial intelligence accelerators on the same huge chip, as CEREBRAS did, which recently claimed to overcome the graphics processing units in NVIDIA Blackweell with more than one factor for the tasks of inference. However, this result was measured by artificial analysis, which inquires about various service providers without controlling how the work burden is carried out. So it is not a comparison between apples to what is guaranteed by the MLPERF standard.
Lack of power
The MLPERF standard also includes an energy test, measuring the amount of energy consumed to achieve each training task. This tour, only one introduction – Lenovo – was able to measure energy in its introduction, making it impossible to make comparisons through artists. The energy it took to adjust LLM to the Blackwell 6.11 Gigajoules graphics units, or 1698 kilowatt hours, or almost the energy that it would take to heat a small winter house. With increasing concerns about the use of artificial intelligence energy, energy efficiency in training is very important, and this author may not be alone in the hope of providing more companies in future rounds.
From your site articles
Related articles about the web
Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-06-04 15:59:00



