
Nvidia Released Llama-3.1-Nemotron-Ultra-253B-v1: A State-of-the-Art AI Model Balancing Massive Scale, Reasoning Power, and Efficient Deployment for Enterprise Innovation
With the increase in the adoption of artificial intelligence in digital infrastructure, institutions and developers face increasing pressure to balance mathematical costs with performance, ability to expand and the ability to adapt. The rapid progress of large language models (LLMS) has opened new boundaries in understanding the natural language, logic, and AI conversation. However, its absolute size and complexity often provide shortcomings that prevent publication on a large scale. In this dynamic scene, the question remains: Could artificial intelligence structures develop to maintain high performance without exaggerating general or financial costs? Enter the next chapter in the innovation epic in NVIDIA, a solution that seeks to improve this barter while expanding the functional limits of AI.
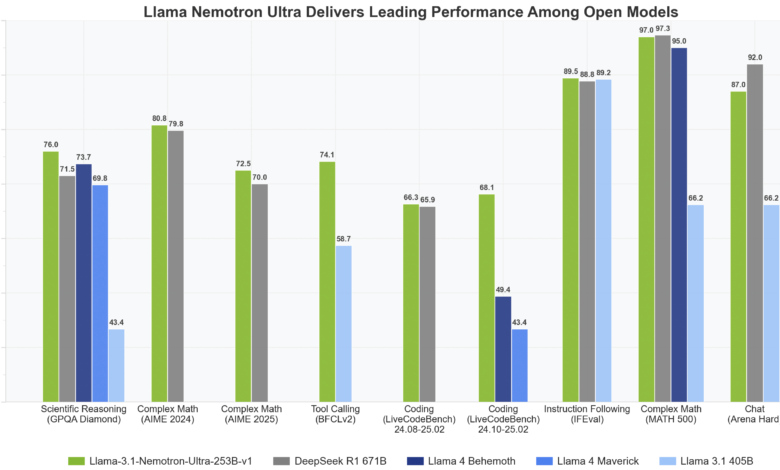
Released Llama-3.1-Sunotron-Ultra-253B-V1The teacher’s language model is 253 billion, which represents a great leap in the capabilities of thinking, the efficiency of architecture, and the preparation of production. This model is part of the broader Llama Nemotron collection, and is directly derived from the Llama-3.1-405B-Instruct. The two small models are part of this series Llama-3.1-heotron-nano-8B-V1 and Llama-3.3-Sunotron-SUPER-49B-V1. Nemotron Ultra, designed for commercial use and institutions, is designed to support tasks ranging from the use of tools and generation of retrieval (RAG) to multi -turn dialogue and monitoring complex instructions.
The essence of the model is only an intense transformer structure for deCONDER only using the NAS nervous engineering. Unlike traditional transformer models, architecture employs non -vulgar blocks and various improvement strategies. Among these innovations is the attention mechanism, where attention units are skipped in a whole layer completely or replaced with simpler linear layers. Also, Fedforward (FFN) fusion technology merges the FFNS sequence into lower and wider layers, which greatly reduces the time of reasoning while maintaining performance.
This model, which has been accurately seized, supports a symbolic context of 128,000, allowing it to absorb and reason on the extended text inputs, which makes it suitable for advanced cutting systems and multiple access analysis. Moreover, Nemotron Ultra fits the burdens of the inference work on one knot 8xh100, which represents a milestone in publishing efficiency. This compact inference capacity greatly reduces the costs of the data center and enhances access to institutional developers.
The post -training process includes the strict stages of NVIDIA, a polishing process is subject to overseeing tasks such as generating code, mathematics, chatting, thinking and tools. This is followed by reinforcement learning (RL) using the Group’s Relative policy (GRPO), which is a specially designed algorithm to control the possibilities of tracking and conversation of the model. These additional training layers guarantee that the model works well on the standards and is in line with human preferences during interactive sessions.
Nemotron Ultra is designed with preparedness for production, and is subject to the NVIDIA Open Model model. His release was accompanied by other brothers’ models in the same family, including Llama-3.1-heotron-nano-8B-V1 and Llama-3.3-Nemotron-SUPER-49B-V1. The version window, between November 2024 and the April 2025, included training data that was used until the end of 2023, making it a relative update in its knowledge and context.
Some fast food include Llama-3.1-Sunotron-Ultra-253B-V1:
- The first design of efficiency: Using NAS and FFN Fusion, NVIDIA reduced the complexity of the model without compromising accuracy, achieving superior and productive cumin.
- The length of the distinctive code is 128k: The model can handle large documents simultaneously, which enhances the capabilities of understanding and long context.
- Ready for the institution: The model is ideal for the Chatbots commercial systems and artificial intelligence agent systems because it is easy to publish on the 8xh100 node and follows the instructions well.
- Good refinement: It guarantees RL with GRPO and supervised training through multi -balance specialties between thinking power and chatting.
- Open license: Nvidia Open Model supports flexible publication, while a community license encourages cooperative adoption.
Payment The model is on the face embrace. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 85k+ ml subreddit.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-04-11 11:00:00



