
OMEGA: A Structured Math Benchmark to Probe the Reasoning Limits of LLMs
Introduction to circular in sports thinking
Language models have shown widely with long-thinking of the children’s bed, such as Deepseek-R1, good results on mathematics at the Olympics level. However, the models trained through the learning subject to supervision or reinforcement are based on limited techniques, such as the repetition of the well -known algebra rules or the failure to coordinate engineering in graph problems. Since these models follow the patterns of thinking used instead of showing real sporting creativity, they face challenges with complex tasks that require original visions. Current mathematics data sets are not very suitable for analyzing mathematics skills that RL models can learn. Corpora is widely incorporated with a set of mathematics questions that differ in the subject and difficulty, which makes it difficult to isolate the specific thinking skills.
Current sports standards restrictions
Current methods, such as generalization outside the distribution, focus on dealing with test distributions that differ from training data, which is very important to sports thinking, material modeling and financial prediction. Connective circular techniques aim to help models systematically combine the skills learned. The researchers have created data collections through different ways to measure sports capabilities, which include human employment to write problems such as GSM8K and Minevamath, collect exam questions such as AIME and Olympiadbench, and ignore and liquidate Corpora like Numinamath and Bigmath. However, these methods either lack the sufficient challenge of modern LLMS or fail to provide analytical analysis.
Omega’s presentation: a controlled standard for thinking skills
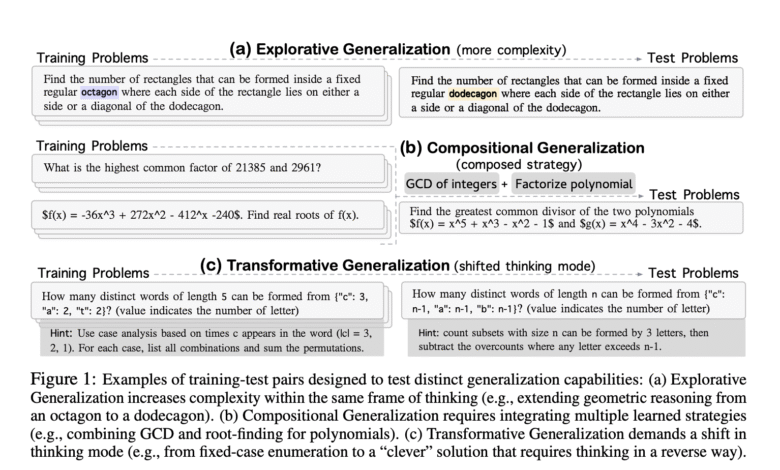
Researchers from the University of California, AI2, Washington University, and DMODEL.AI Omega, have suggested a designed standard for evaluating three dimensions of generalization outside the distribution, inspired by the Boden Creativity style. It creates identical training and test pairs designed to isolate specific thinking skills across three dimensions: exploration, formalism and transformation. Omega test problems are built on the train using carefully geometric molds, allowing accurate control of diversity, complexity and specific thinking strategies required for solutions. Moreover, 40 generators use problems represented in six sports fields: account, algebra, collusion, numbers theory, engineering, logic and puzzles.
Evaluation on Llms Frontier and preparation for reinforcement
Researchers evaluate four border models, including Deepseek-R1, Claude-3.7-Sonnet, Openai-O3-MINI, Openai-O4-MINI, across different complexity levels. For RL circulation experiments, the GRPO algorithm applies 1000 training problems using QWEN2.5-7B-Instruct and QWEN2.5-Math-7B models. The exploratory generalization is trained at restricted complexity levels and resides in the problems of higher complexity. The synthetic circular includes training models on individual skills in isolation and testing their ability to combine these skills and apply effectively. The circular is trained in traditional solutions and evaluates performance on problems that need unconventional strategies.
Performance notes and patterns of form
LLMS tends to make a worse performance with an increased complexity of the problem, and it often finds the right solutions early but spending many symbols on unnecessary verification. RL only has been applied to low complexity problems that enhance the generalization of medium complexity problems, with greater gains on examples more than those in the distribution field, indicating the effectiveness of RL in enhancing familiar patterns. For example, in the field of zebra logic, the basic model achieves only 30 % accuracy. However, the RL training increased 61 points on examples in regions and 53 points on examples outside the distribution without SFT.
Conclusion: Towards the progress of transformational thinking
In conclusion, researchers, Omega, a criterion that isolates and evaluates three generalizations outside the distribution in sports thinking: exploratory, synthetic, and transformation. The experimental study reveals three visions: (a) RL refining greatly to improve performance on distribution tasks and exploration, (B) RL benefits for limited synthetic tasks, and (C) RL fails to stimulate really new logic patterns. These results shed light on basic restrictions: RL can amplify the breadth and depth of problem solving, but it falls short in enabling the creative jumps necessary for transformational thinking. Future work should explore curriculum scores and metal controllers.
verify Paper, project page and Japemb. All the credit for this research goes to researchers in this project. Also, do not hesitate to follow us twitter And do not forget to join 100K+ ML Subreddit And subscribe to Our newsletter.
Sajjad Ansari is in the last year of the first university stage of Iit khargpur. As enthusiastic about technology, it turns into the practical applications of Amnesty International with a focus on understanding the impact of artificial intelligence techniques and their effects in the real world. It aims to clarify the concepts of complex artificial intelligence in a clear and accessible way.

Don’t miss more hot News like this! Click here to discover the latest in AI news!
2025-07-01 14:22:00



