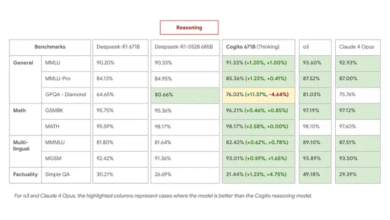
OpenAI Introduces the Evals API: Streamlined Model Evaluation for Developers
In a big step to enable developers and teams that work with large language models (LLMS), Openai presented Evals API,, A new tool group brings the code of the program to the fore. While the assessments were previously available via Openai’s information board, the new application programming interface allows developers to get Select the tests, automation of the evaluation, and repeat on the claims Directly from their workflow tasks.
Why do Evals applications
LLM’s performance evaluation often a long -time manual process, especially for teams that make applications to expand applications across various fields. With the EVALS application programming interface, Openai provides a systematic approach to:
- Evaluation of the performance of the model in dedicated test situations
- Measuring improvements via rapid repetitions
- Quality Assurance Automation in Development Pipelines
Now, every developer can deal with the evaluation as a first-class citizen in the development course-on how to deal with unit tests in traditional software engineering.
The basic features of Evals API
- Debate dedicated evaluation: Developers can write their evaluation logic by extending the basic chapters.
- Data integration testMerging the evaluation data sets smoothly to test specific scenarios.
- Teacher formationForm composition, temperature, maximum symbols, and other generation parameters.
- Automatic runs: Run the assessments via the code, and recover the results programming.
The API Evals supports the structure of YAML configuration, allowing both flexibility and reuse.
Start with EVALS application programming interface
To use the EVALS application programming interface, it first installs the Openai Python package:
After that, you can run an evaluation using a built -in evaluation, such as factuality_qna
oai evals registry:evaluation:factuality_qna \
--completion_fns gpt-4 \
--record_path eval_results.jsonlOr specify a dedicated evaluation in Bethon:
import openai.evals
class MyRegressionEval(openai.evals.Eval):
def run(self):
for example in self.get_examples():
result = self.completion_fn(example['input'])
score = self.compute_score(result, example['ideal'])
yield self.make_result(result=result, score=score)This example explains how you can determine the logic of assigned evaluation – in this case, measure the accuracy of the slope.
Case use: slope assessment
An example of the Openai Cooking Book walks by building an API borrower. Here is a simplified version:
from sklearn.metrics import mean_squared_error
class RegressionEval(openai.evals.Eval):
def run(self):
predictions, labels = [], []
for example in self.get_examples():
response = self.completion_fn(example['input'])
predictions.append(float(response.strip()))
labels.append(example['ideal'])
mse = mean_squared_error(labels, predictions)
yield self.make_result(result={"mse": mse}, score=-mse)This allows developers to measure digital predictions of models and track changes over time.
Integration of smooth workflow
Whether you are building a chatbot, a summary or classification system, the rating can now be run as part of the CI/CD pipeline. This ensures that every update or model maintains or improves performance just before going.
openai.evals.run(
eval_name="my_eval",
completion_fn="gpt-4",
eval_config={"path": "eval_config.yaml"}
)conclusion
The launch of the EVALS application programming interface is a shift towards strong automatic evaluation criteria in LLM development. By providing the ability to create, operate and analyze assessments, Openai enables the difference of construction with confidence and improve the quality of artificial intelligence applications constantly.
For more exploration, check the official Openai Evals documents and examples of cooking book.
Asif Razzaq is the CEO of Marktechpost Media Inc .. As a pioneer and vision engineer, ASIF is committed to harnessing the potential of artificial intelligence for social goodness. His last endeavor is to launch the artificial intelligence platform, Marktechpost, which highlights its in -depth coverage of machine learning and deep learning news, which is technically sound and can be easily understood by a wide audience. The platform is proud of more than 2 million monthly views, which shows its popularity among the masses.

Don’t miss more hot News like this! AI/" target="_blank" rel="noopener">Click here to discover the latest in AI news!
2025-04-09 06:36:00